
🚢 快速开始
安装SwanLab,并在几分钟内掌握如何跟踪你的机器学习实验。

了解如何在Transformers训练流程中无缝集成SwanLab,实现高效的实验跟踪。
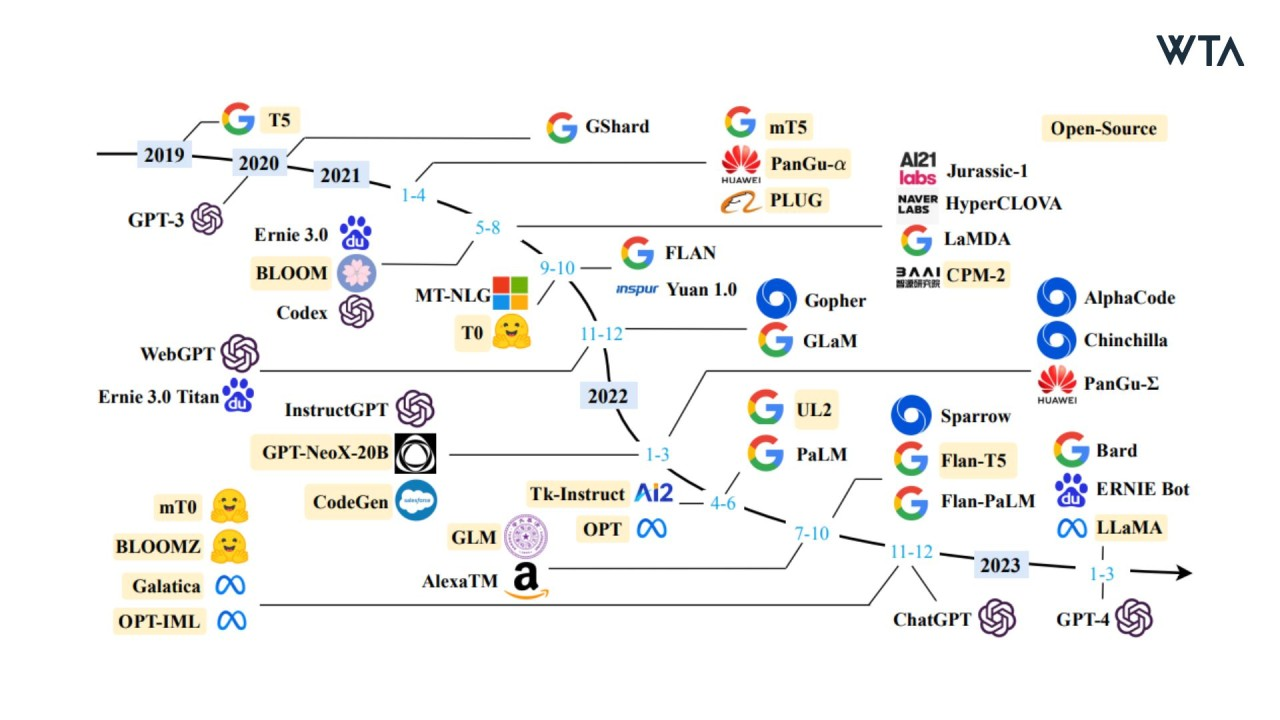
本文则从如何自己实战预训练一个大语言模型的角度,使用Wiki数据集进行一个简单的从零预训练工作。
深入了解SwanLab的插件生态,快速接入你的邮件、飞书、钉钉、企业微信等IM系统,让掌握进度快人一步

了解如何在LLaMA Factory训练流程中无缝集成SwanLab,实现高效的实验跟踪。

本文介绍如何从零到一训练一个Stable Diffusion火影忍者模型。
深入了解SwanLab的插件生态,快速接入你的邮件、飞书、钉钉、企业微信等IM系统,让掌握进度快人一步
情感机器(北京)科技有限公司
京ICP备2024101706号-1 · 版权所有 ©2024 SwanLab