使用llamafactory框架进行qlora微调教程
简介
接上回lora和qlora对比的那篇,本节讲用llama-factory框架来实现大模型的lora和qlora的教程,并且对比分析运行的结果,让读者更加清晰直观的感受qlora和lora的区别。
本次教程使用昇腾910B2,也就是NPU来进行训练,在AutoDL上创建NPU的容器进行训练,过程很简单,我们在下面的教程里会一步一步指导。
链接资料
模型
我们使用Qwen系列模型,为了能够更方便看出效果,会使用Qwen2的预训练模型做实验。不过Qwen2的好多Base模型在魔搭社区没有,可能删了,我只找到了0.5B的和7B的模型,0.5B的话Qlora和lora的结果对比可能不是很明显,7B的模型由于NPU没有集成deepspeed等加速框架,所以Qlora训练时间会很长,因此如果有需要的话也可以考虑用Qwen2.5-3B的预训练模型来测,效果应该跟Qwen2-3B差不多,技术报告里也说了2.5和2的框架没什么改变,无非是训练的数据集更多。
不过需要注意的是,AutoDL可能连不上huggingface,所以模型下载要在国内网站下载,可以选择魔搭社区的,我把链接放下面,可以直接加载模型到本地使用。
数据集
本次教程以实验操作为主,使用一个高质量数学问答数据集作为微调的数据集,可以在魔搭社区上下载,链接如下:
- Math10K:data
该数据集出自《LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models》,为解决当时推理数据集训练样本不足或缺乏推理步骤的问题,整合GSM8K、MAWPS等数据集的 共10k样本,并从 AQuA 数据集中筛选了1000个样本,用ChatGPT通过零样本思维链(zero-shot chain-of-thought)提示生成推理步骤,以增强模型的推理能力;同时,为确保数据质量,剔除了包含错误答案的样本。
我们在实际使用的时候不需要这么多的数据,微调的效果用2k条数据就可以展现,因此我们后续随机选择2k条数据集作为训练集,200条数据作为验证集。
SwanLab简介
我们的可视化工具选择SwanLab,llamafactory已经集成SwanLab工具,可以直接使用。
友情链接:
SwanLab官方文档,助你轻松开启深度学习之旅。
- 框架集成文档:SwanLab已经集成Transformers、LLaMA Factory、Pytorch等主流框架,并持续更新
- 实战案例:SwanLab提供了丰富的模型训练实战教程,助力用户快速掌握深度学习模型训练的要点
AutoDL简介
AutoDL 是面向 AI 开发者的一站式云算力服务平台,主打 “即开即用、灵活高效” 的算力解决方案,能大幅降低 AI 模型训练与推理的硬件门槛。平台整合了丰富的GPU以及NPU资源,覆盖从入门级到高端的各类显卡型号,比如RTX 3090、A100、H100等,同时也支持昇腾910B系列,开发者无需自行采购和维护硬件,通过简单操作就能快速获取专属算力环境。
同时还支持自动配置深度学习环境,预装了 PyTorch、TensorFlow 等主流框架及常用依赖库,还提供可视化界面管理实例,可实时监控算力使用情况、调整实例规格。
链接如下👇:
其他
- llama-factory框架地址:LLaMA-Factory
- autodl网站:算力广场
- swanlab地址:SwanLab官网
- 可视化结果地址:SwanLab结果
- 作者资料:情感机器实验室研究员-李馨雨
代码
环境准备
硬件环境准备
这次我们使用AutoDL的NPU昇腾910B2-64GB来进行实验,首先在算力广场,我们选择昇腾专区,卡的数量我们选择一块即可
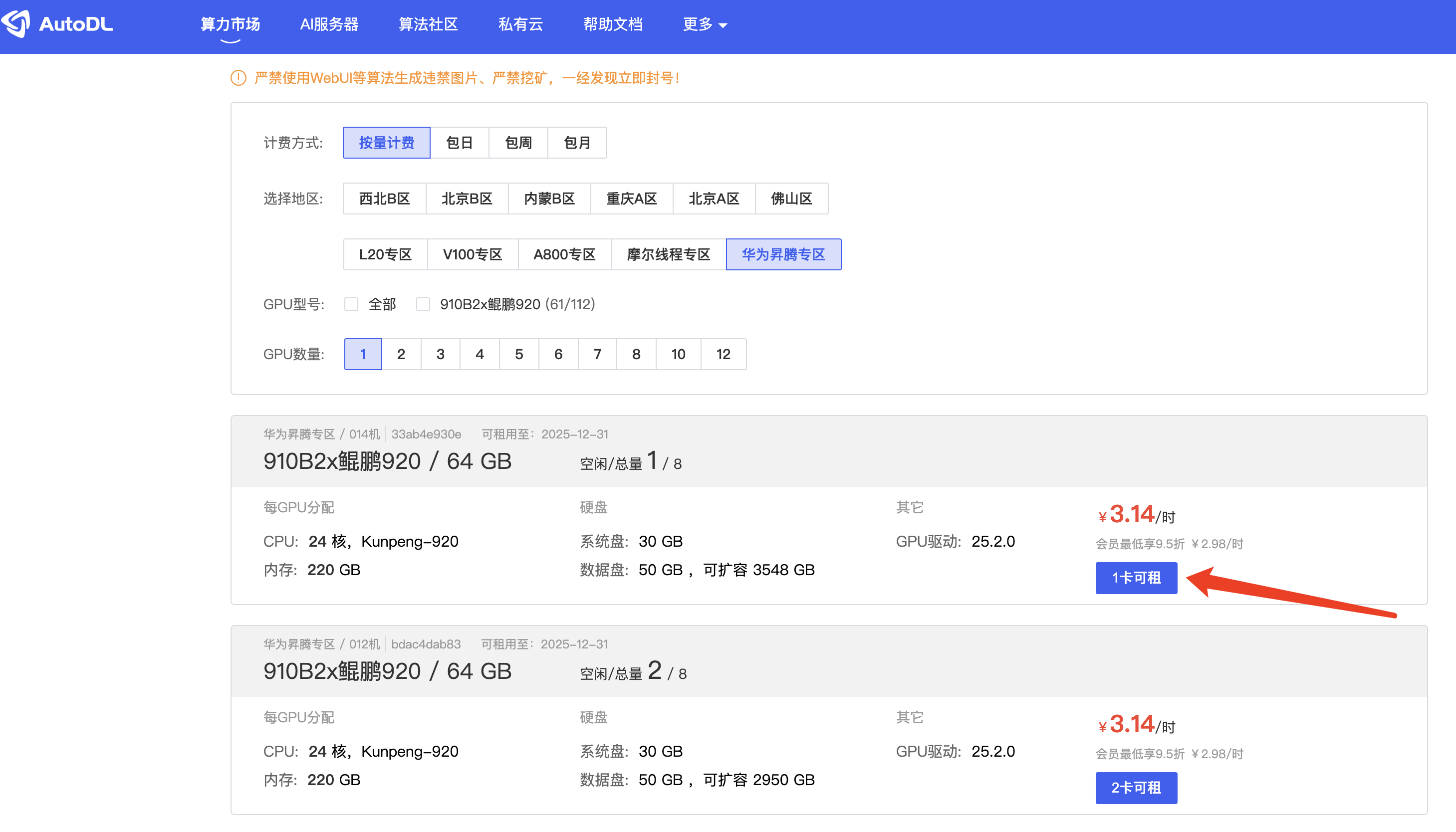
然后对应的镜像,我们选择基础镜像中有Pytorch框架的镜像
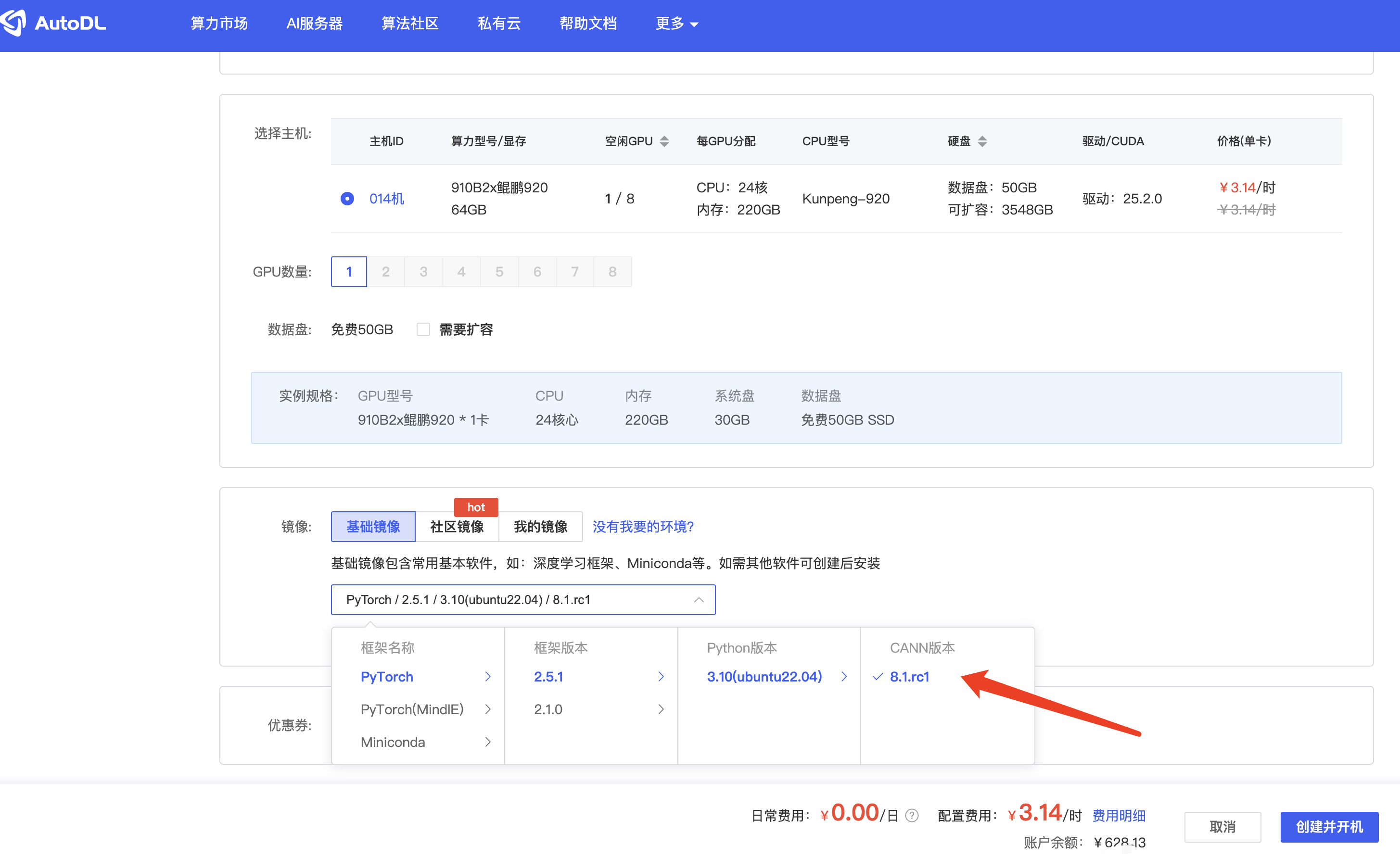
后续我们在本地控制台里选择容器实例,开机就可以直接使用NPU了

在使用的时候,我们既可以直接用JupyterLab线上各种操作,也可以使用他们的自定义服务,不过我比较习惯用VS Code,所以直接远程调用服务器本地编辑的,这里简单说下怎么用。
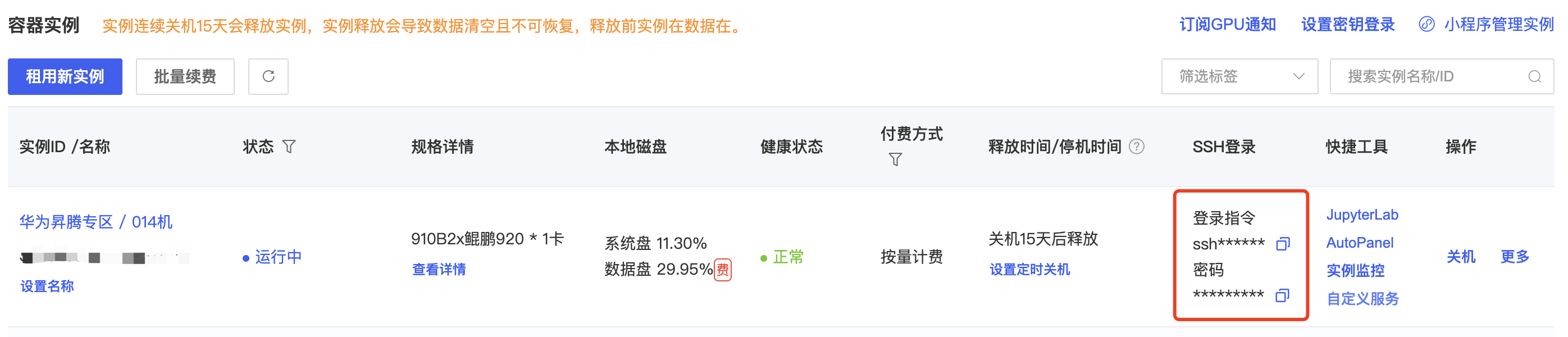
把SSH登陆的账号和密码输到VS Code的Remote Host即可。
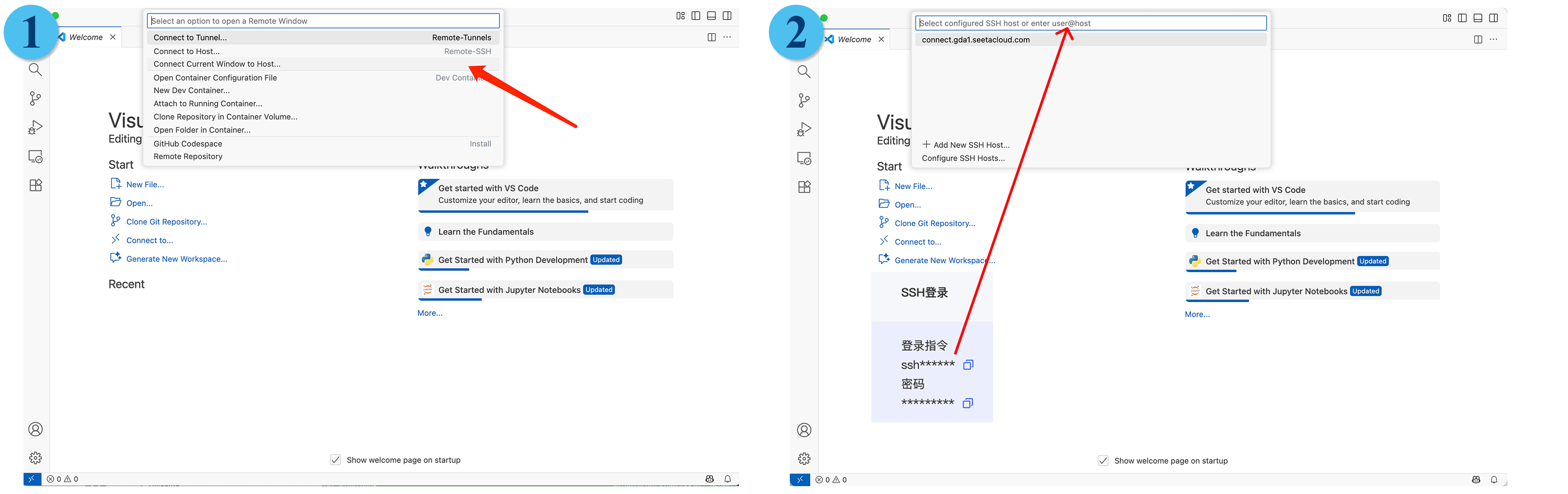
然后我们登陆容器后就可以正常使用了,不过要注意的是,对于模型和数据集最好存放在数据盘里,系统盘比较小,编辑代码就行。
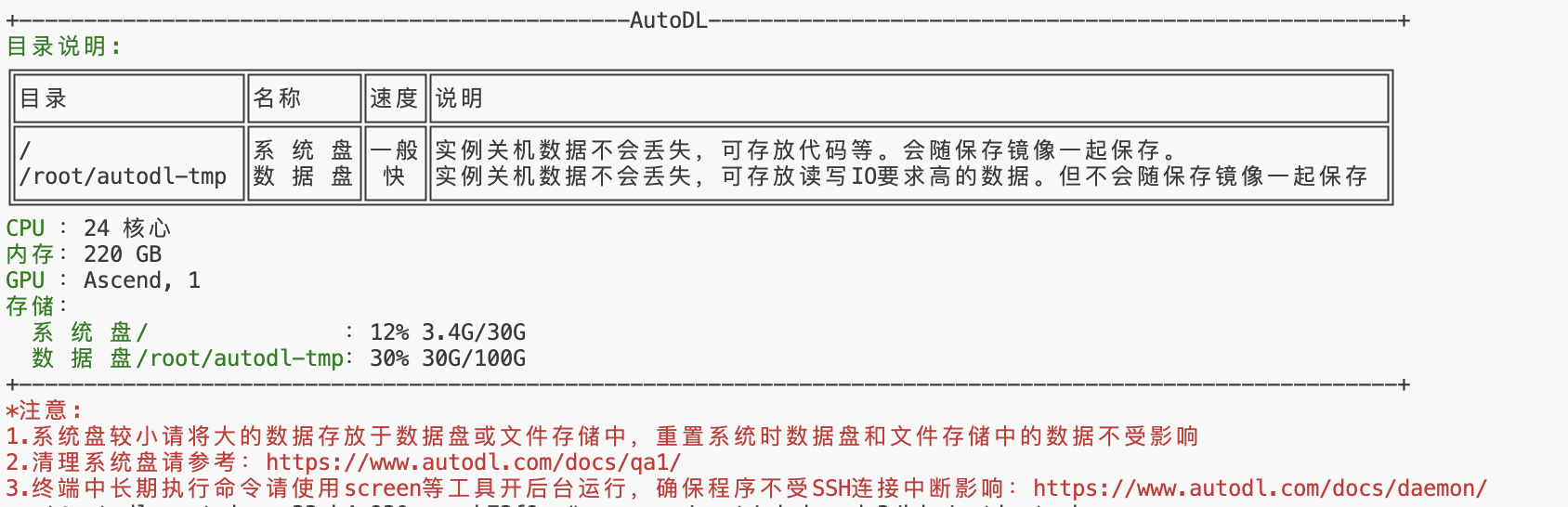
python环境安装
1. 基础环境安装
登陆后,安装以下环境
pip install transformers modelscope swanlab bitsandbytes>=0.39.0或者运行代码仓库的txt文件
pip install -r requirement.txt2. LLaMA-Factory框架安装
原始的安装教程在LLaMA-Factory官网,但是AutoDL没有办法直接连接到github,因此我们在国内gitee网站上下载。也可以直接运行下面的代码安装:
git clone https://gitee.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"后面的昇腾的Ascend CANN Toolkit 与 Kernels安装不用管,容器实例已经安装好了,我们只需要安装环境就好。
数据集准备
我们把数据集下载到本地保存并处理:
modelscope download --dataset lmms-lab/Math10K data/train-00000-of-00001.parquet --local_dir /root/autodl-tmp/data/lmm-lab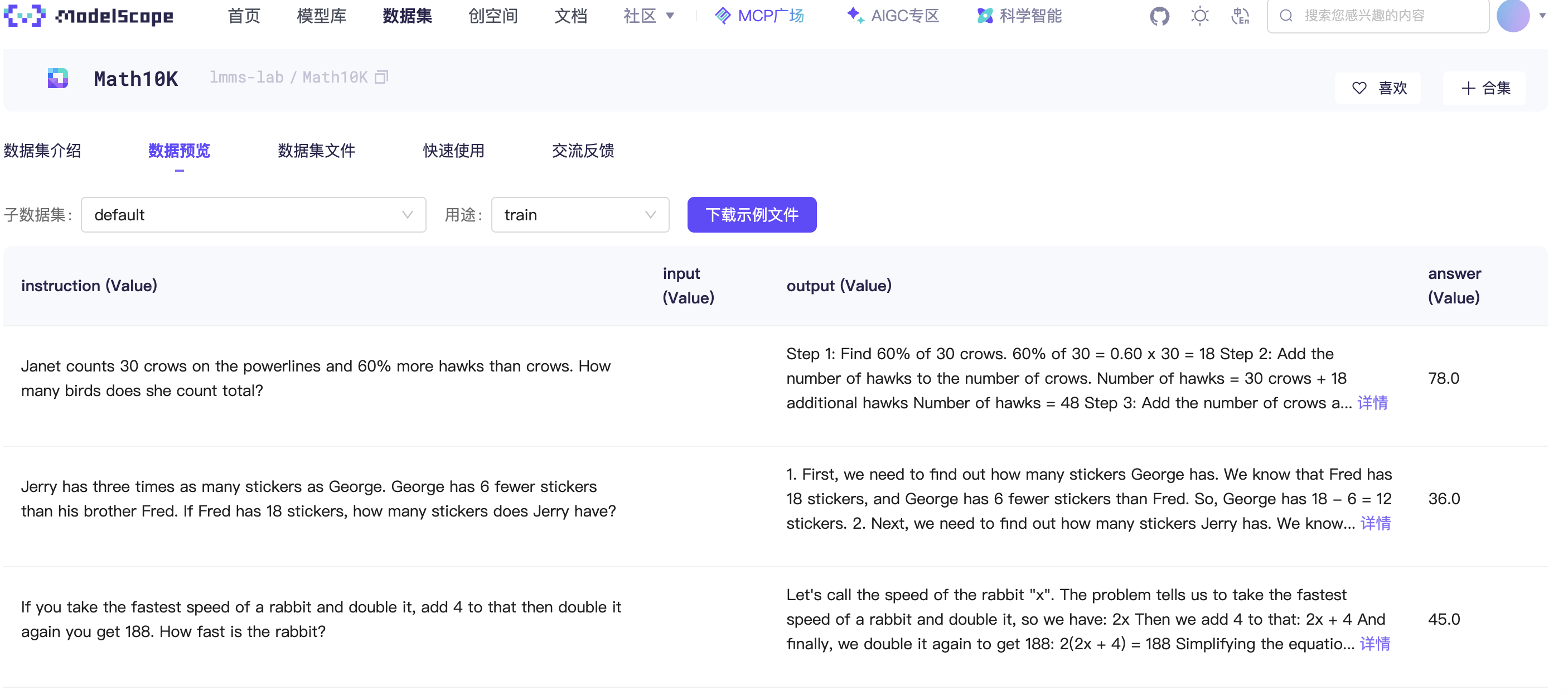
因为数据集数据较多,我们仅需要其2k条数据即可,因此我们随机选取2k条数据作为训练集,200条数据作为验证集。
{
"instruction": "写一个有效的比较语句",
"input": "篮球和足球",
"output": "篮球和足球都是受欢迎的运动。"
}# 查看数据
data_path="/root/autodl-tmp/data/lmm-lab/data/train-00000-of-00001.parquet"
from datasets import load_dataset
dataset = load_dataset("parquet", data_files=data_path)
# 转换成列表
dataset=list(dataset['train'])
# 计算分割点(前90%和后10%)
total_samples = len(dataset)
split_index = int(total_samples * 0.9)
# 分割数据集
train_90 = dataset[:split_index] # 前90%数据
train_10 = dataset[split_index:] # 后10%数据
# 随机选择样本(设置随机种子确保可复现)
import random
random.seed(42)
selected_90 = random.sample(list(train_90), min(2000, len(train_90))) # 前90%选2000条
selected_10 = random.sample(list(train_10), min(200, len(train_10))) # 后10%选200条
# 改造数据集,最终数据保存成json文件
import json
# 训练数据
train_json=[]
for data in selected_90:
output=data['output']+"\n#### "+data['answer']
train_json.append({'instruction':data['instruction'],'input':data['input'],'output':output})
with open("/root/autodl-tmp/data/lmm-lab/data/math-train.json", "w") as f:
json.dump(train_json, f, ensure_ascii=False)
# 验证数据
eval_json=[]
for data in selected_10:
output=data['output']+"\n#### "+data['answer']
eval_json.append({'instruction':data['instruction'],'input':data['input'],'output':output})
with open("/root/autodl-tmp/data/lmm-lab/data/math-eval.json", "w") as f:
json.dump(eval_json, f, ensure_ascii=False)保存的数据集每条数据如下:
{
"instruction": "Georgia has 25 pieces of stationery while Lorene has three times as many pieces of stationery as Georgia. How many fewer pieces of stationery does Georgia have than Lorene?\n ",
"input": "",
"output": "Step 1: Find how many pieces of stationery Lorene has. \n\nLorene has three times as many pieces of stationery as Georgia, so: \n\nLorene = 3 x Georgia \n\nLorene = 3 x 25 \n\nLorene = 75 \n\nLorene has 75 pieces of stationery. \n\nStep 2: Find the difference between the number of pieces of stationery Georgia has and the number Lorene has. \n\nDifference = Lorene - Georgia \n\nDifference = 75 - 25 \n\nDifference = 50 \n\nTherefore, Georgia has 50 fewer pieces of stationery than Lorene. The answer in Arabic numerals is: 50.\n#### 50.0"
}参数设置
本次教程使用LLaMA-Factory的命令行来实现训练、推理等任务,不过LLaMA-Factory很全面,只需要修改一些文件即可。
数据集参数设置
我们把上面保存的json文件转移至LLaMA-Factory的data中:
然后后续在使用train的命令行的时候会遇到dataset,dataset需要用到dataset_info.json中的数据集,我们需要把保存到data的数据集写入:

我们没有其他的名片,所以不需要写其他的键
这样我们在训练的脚本文件中可以直接写对应的数据集的名字。
训练文件参数设置
| 动作参数枚举 | 参数说明 |
|---|---|
| version | 显示版本信息 |
| train | 命令行版本训练 |
| chat | 命令行版本推理chat |
| export | 模型合并和导出 |
| api | 启动API server,供接口调用 |
| eval | 使用mmlu等标准数据集做评测 |
| webchat | 前端版本纯推理的chat页面 |
| webui | 启动LlamaBoard前端页面,包含可视化训练,预测,chat,模型合并多个子页面 |
# 查看命令参数
llamafactory-cli -h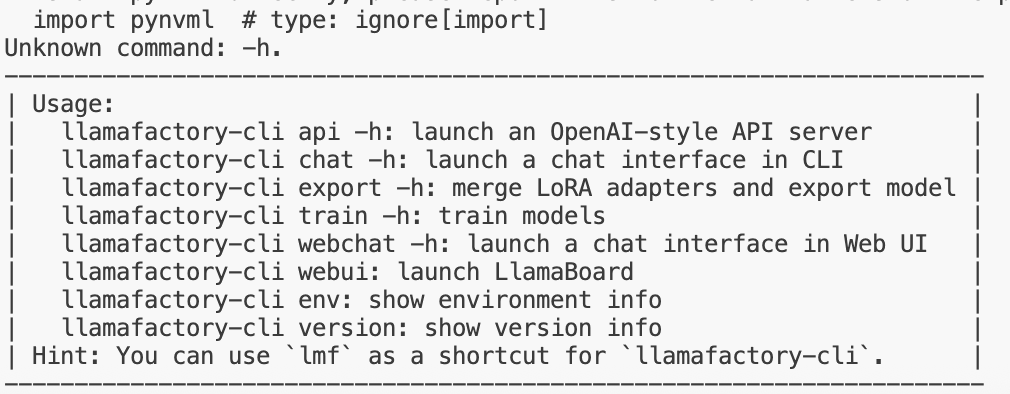
然后使用webui的时候,发现好像只能显示训练数据集,没有测试数据集比如mmlu、ceval等,下载再修改格式太麻烦了,所以如果评测eval的话还是用evalscope了,我另外有一篇是专门讲如何使用evalscope的,可以去看👉地址。
对应的参数细节可以通过命令行查看,可以看出我们可以在脚本里写哪些参数:
# 训练
llamafactory-cli train -h
# 模型合并
llamafactory-cli export -h虽然每个命令行有很多的参数设置细节,但是我们实际使用的时候并不会用到全部的参数,我们只需要训练相关的参数即可。
其中基本所有的命令行都需要下面两个参数:
| 参数名称 | 参数说明 |
|---|---|
| model_name_or_path | 参数的名称(huggingface或者modelscope上的标准定义,如“meta-llama/Meta-Llama-3-8B-Instruct”), 或者是本地下载的绝对路径,如/media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct |
| template | 模型问答时所使用的prompt模板,不同模型不同,请参考 template 获取不同模型的模板定义,否则会回答结果会很奇怪或导致重复生成等现象的出现。chat 版本的模型基本都需要指定,比如Meta-Llama-3-8B-Instruct的template 就是 llama3 |
对于template,因为我们使用Qwen2(或许可能会用到的Qwen2.5),Qwen系列直接template设置为qwen。
其他的参数,我们参考已经给出的llama模型的文件,可以直接复制粘贴一份,然后修改其中的参数,重点是模型地址、保存地址等,内容如下:
### model
model_name_or_path: /root/autodl-tmp/models/qwen2-7b
### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_target: all
### dataset
dataset: lmm-lab-math-demo
template: qwen
cutoff_len: 2048
max_samples: 2000
overwrite_cache: true
preprocessing_num_workers: 16
dataloader_num_workers: 4
### output
output_dir: /root/autodl-tmp/models/saves/math/qwen2-7b-lora
logging_steps: 5
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: false
report_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow]
### swanlab
use_swanlab: true
swanlab_project: llamafactory
swanlab_run_name: qwen2-7b-lora-math
### train
per_device_train_batch_size: 2
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 1.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
resume_from_checkpoint: null
### eval
eval_dataset: math-eval-demo
per_device_eval_batch_size: 2
eval_strategy: steps
eval_steps: 20这个文件需要保存到LLaMA-Factory/examples/train_lora/qwen2-7b-math-sft.yaml
上述是lora的参数设置,qlora也是同样,但是需要注意的是,因为NPU并没有涉及太多量化方法,因此我们需要复制粘贴带有NPU的文件,然后加工:
### model
model_name_or_path: /root/autodl-tmp/models/qwen2-7b
quantization_bit: 4
quantization_method: bnb
double_quantization: false
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_target: all
### dataset
dataset: lmm-lab-math-demo
template: qwen
cutoff_len: 2048
max_samples: 2000
overwrite_cache: true
preprocessing_num_workers: 16
dataloader_num_workers: 4
### output
output_dir: /root/autodl-tmp/models/saves/math/qwen2-7b-qlora
logging_steps: 5
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: false
report_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow]
### swanlab
use_swanlab: true
swanlab_project: llamafactory
swanlab_run_name: qwen2-7b-qlora-math
### train
per_device_train_batch_size: 2
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 1.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
eval_dataset: math-eval-demo
per_device_eval_batch_size: 2
eval_strategy: steps
eval_steps: 20这个文件需要保存到LLaMA-Factory/examples/train_qlora/qwen2-7b-sft-bnb-npu.yaml
实际实验的时候,Lora的速度很快,一个epoch基本不到10分钟就能完成,不太需要用到deepspeed或者accelerate加速,但是QLora会很慢,NPU的话llamafactory没有集成deepspeed或者accelerate,因此无法用到加速框架。
同时最好连deepspeed都不要安装到环境里,因为会直接报错...😭。
可视化工具设置
训练过程中我们需要观测train和eval的loss和其他的结果的变化,以便及时的掌握模型性能变动情况,我们在yaml的任意位置添加下面的代码,其实上面给出的训练脚本我已经提到,不过这里再展示下:
......
### swanlab
use_swanlab: true
swanlab_project: llamafactory
swanlab_run_name: Qwen2-7B第一次登陆SwanLab的话需要设置API Key才能使用,在设置中可以找到:
训练代码
运行下面的代码即可,需要注意的是,因为我们使用的是NPU设备,因此选择设备的时候需要用ASCEND_RT_VISIBLE_DEVICES=0:
cd LLaMA-Factory
# Lora
ASCEND_RT_VISIBLE_DEVICES=0 llamafactory-cli train examples/train_lora/qwen2-7b-math-sft.yaml
# QLora
ASCEND_RT_VISIBLE_DEVICES=0 llamafactory-cli train examples/train_qlora/qwen2-7b-sft-bnb-npu.yaml模型合并
微调后的模型文件需要和原模型进行合并,因为微调的文件是新增的参数量,不能直接使用(QLoRA也是同理),我们需要的参数如下:
| 参数名称 | 作用 | 说明 |
|---|---|---|
--model_name_or_path | 指定原模型(基座模型)的路径 | 即保存的Qwen原模型文件夹,需包含模型权重、配置文件等 |
--adapter_name_or_path | 指定训练好的 LoRA 权重路径 | 指向包含LoRA权重(如 adapter_config.json、adapter_model.bin)的文件夹,无需手动指定 checkpoint 子文件夹(工具会自动识别最新 checkpoint) |
--export_dir | 指定合并后模型的保存路径 | 最终合并后的完整模型会保存在此目录下 |
--stage | 指定任务类型为 “导出模型” | LoRA 微调属于 SFT(监督微调)阶段,固定填 sft 即可 |
--finetuning_type | 指定微调方式为 LoRA | 与你的训练方式匹配,确保工具识别并加载 LoRA 权重 |
实际使用的时候,我们运行下面的代码:
llamafactory-cli export \
--model_name_or_path /root/autodl-tmp/models/qwen2-7b \
--adapter_name_or_path /root/autodl-tmp/models/saves/math/qwen2-7b-qlora \
--export_dir /root/autodl-tmp/models/qlora/qwen2-7b-qlora \
--stage sft \
--template qwen \
--finetuning_type lora结果观测
SwanLab可视化结果
我在实验过程中对比了多个参数量模型的结果,同时也有lora和qlora的对比,其中qlora能明显看到NPU的占用降低,但是训练时间延长。加速框架由于没有与NPU适配,因此没有办法加速训练时间。
而从训练曲线上看,qlora和lora效果差不多,如果对结果有验证需求的炼丹师可以参考我的另一篇文章,使用evalscope框架来eval的,地址在这👉地址,llamafactory好像把原来的eval功能删了,那这里就不再赘述了。
模型训练过程曲线
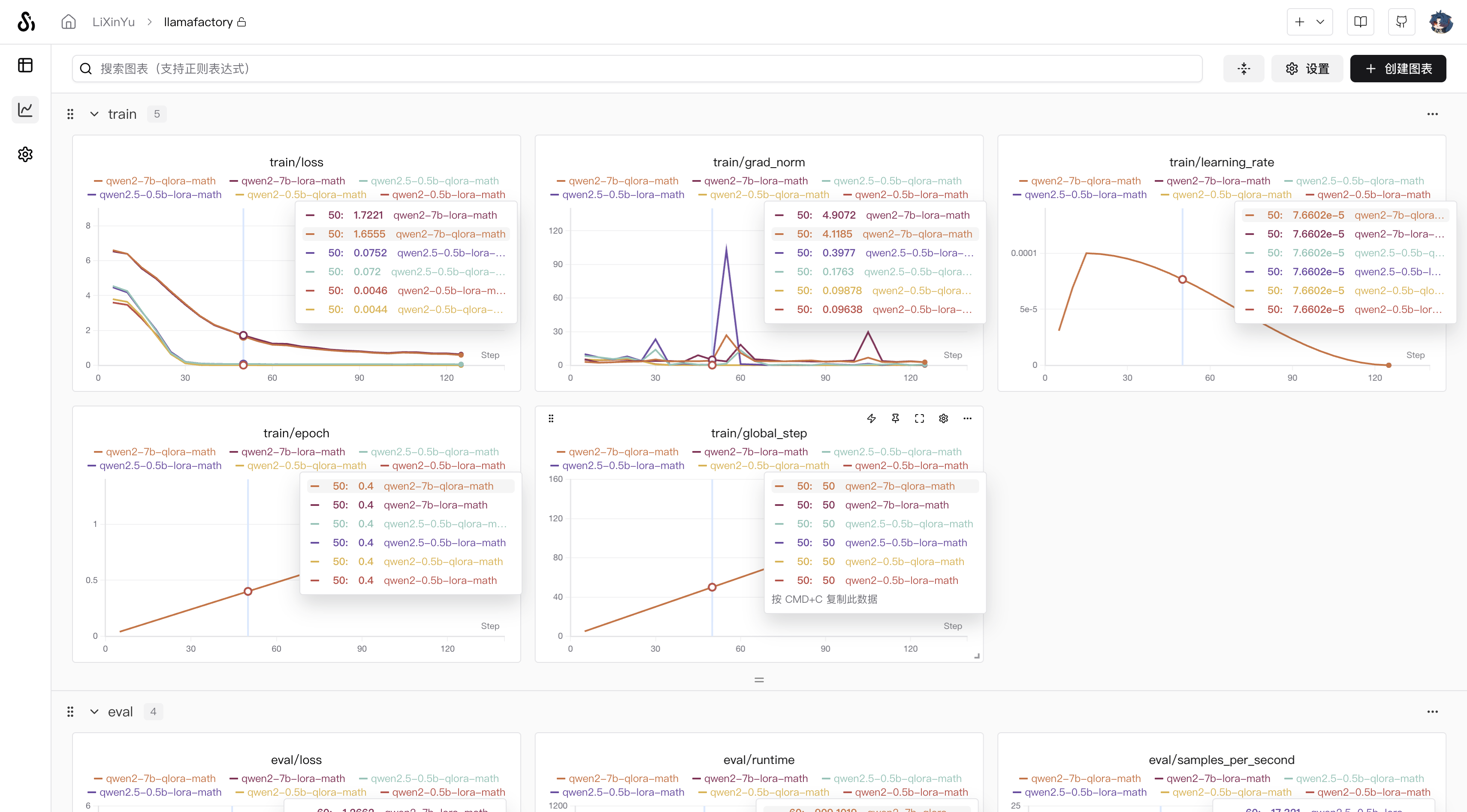
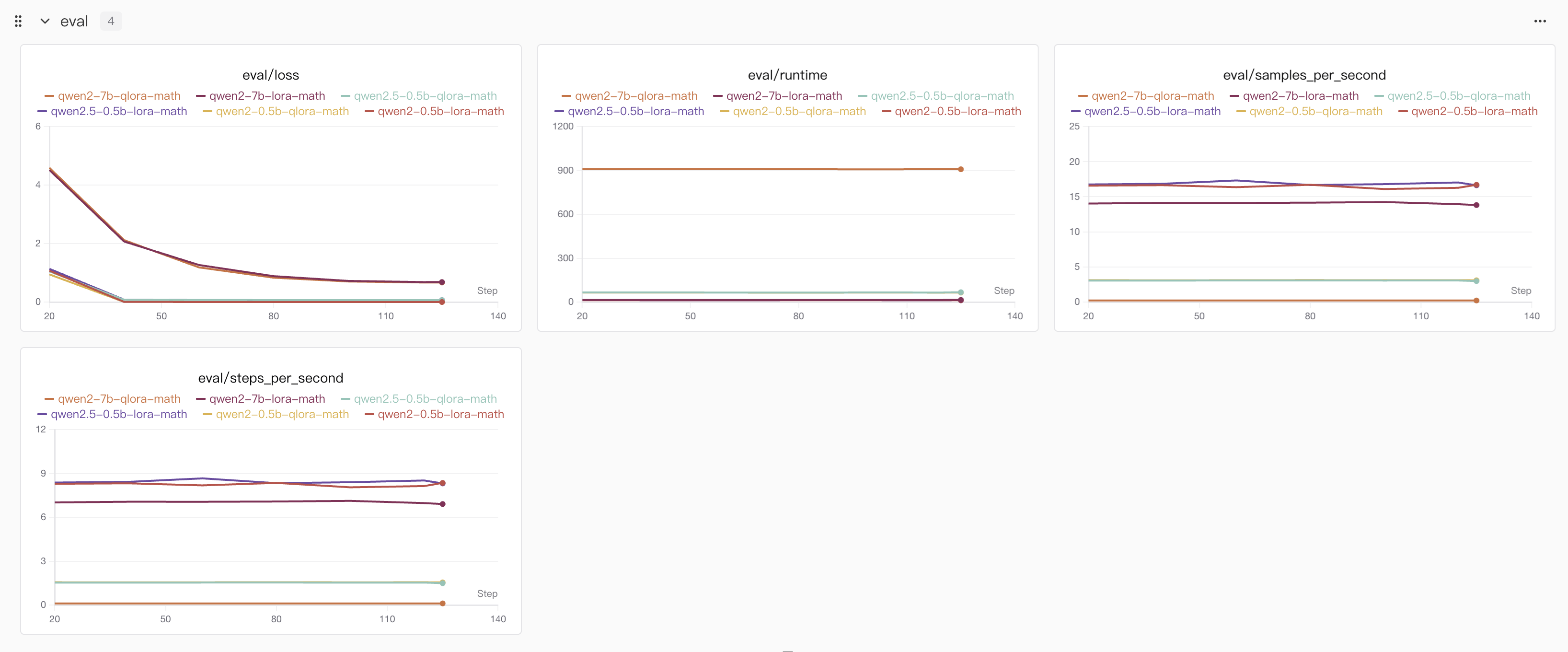
从训练效果上基本没有什么差别,因此如果资源充足,采用lora训练就行。
NPU显存占用对比
在训练资源的占用方面,很明显能对比出量化后,显存占用明显减少,训练loss上却差不多,所以如果资源受限,那么尝试使用QLoRA的方式微调是一个不错的选择。
本次教程重点在于如何使用NPU来基于llamafactory框架实现模型微调以及量化训练,如果对验证结果有需要,请参考我的另一篇基于evalscope框架的那篇。