实现合成数据代码举例
经过前文的理论知识的补充,我们对每个阶段是否需要合成数据,以及各个阶段的合成数据有了基本的了解,那么下面我们就通过简单的代码实现由大模型合成各个阶段的合成数据让大家有更深刻的理解。
预训练数据
其实构建Phi模型的团队在论文[1] [2]里仅说明了数据集的构成来源以及数量,但是并没有详细说明数据的内容、如何处理数据的,因此Huggingface团队生成含数十亿词元的合成数据集以复现 Phi-1.5 过程中所遇到的挑战及其解决方案,由此最终创建了 Cosmopedia 合成数据集[3]。该团队根据论文中提供的信息,从网络以及各个教育平台获得“种子数据”,然后由“种子数据”通过大模型合成扩大到3000万条的规模。
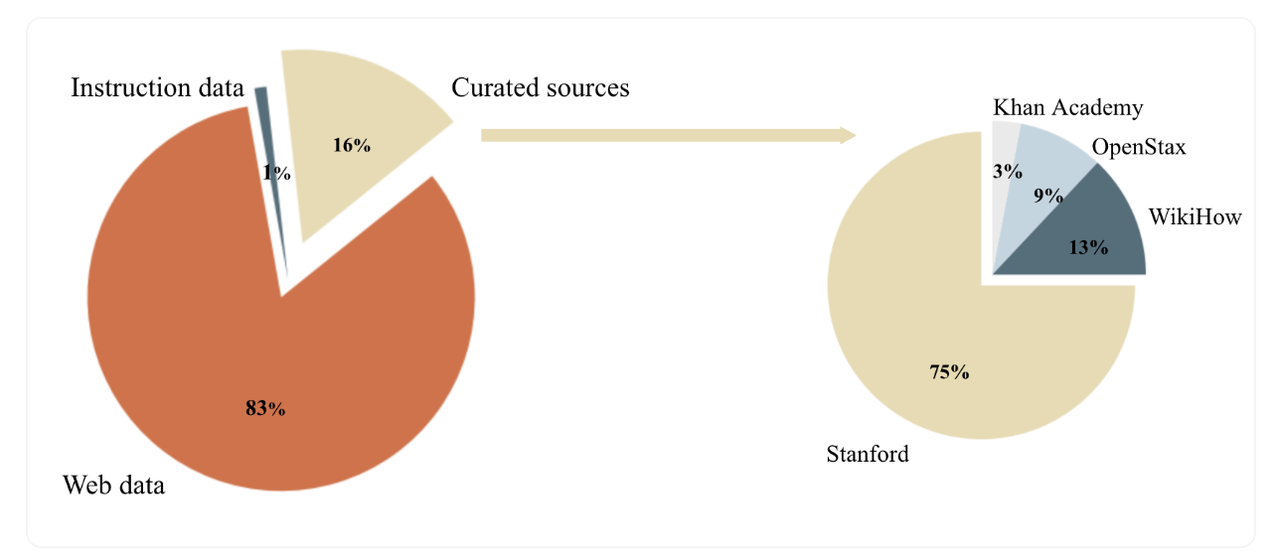
该团队获得的“种子数据源”分别是网络数据和教育数据,其中网络数据占比最高,高达83%,还有纯粹的教育数据由16%,最后还有其他少量指令数据。
该huggingface团队还提供了复现代码[4],其中将合成步骤简单总结为三步,分别是:
- 合成prompt
- 根据prompt生成数据
- 数据筛选、去重等
我们提供了简易的生成代码,链接在这,代码构成如下:
pretrain_data_generation/
├── generation.py # 数据生成
├── utils.py # openai接口设计以及其他工具等
├── data/ # 生成的数据保存地址
└── data_process/ # 数据处理
├── minhash_logs/ # 生成的哈希去重log
├── minhash_results/ # 哈希去重结果
├── data_depulication.py # 数据去重
└── data_format_conversion.py # 数据格式转换下面我们按照步骤依次执行:
1、合成prompt
由于数据集包含大量的网络数据,但是huggingface团队提供的比如生成web网络数据的prompt的代码里,数据集无法获取,不过该合成prompt的思想还是提示词+网络数据(上下文),具体的prompt可以参考官方的提示词:
提示词模板:
"wikihow":
"""Here is an extract from a webpage: "<INSERT_EXTRACT>".
Write a long and very detailed tutorial that could be part of WikiHow whose title is related to the extract above<ADD_TOPIC>. Include in depth explanations for each step and how it helps achieve the desired outcome, inluding key tips and guidelines.
Ensure clarity and practicality, allowing readers to easily follow and apply the instructions. Do not use images.""",<INSERT_EXTRACT>是网络数据放入的地方。
为了方便起见,我们直接获取HuggingFaceTB/cosmopedia-100k的prompt就行(因为我们只需要学习如何生成的思想,具体操作可以查阅网络数据填充对应的地方批量生成prompt)。
我们下载数据集到本地,可以使用modelscope下载数据集到本地
modelscope download --dataset swift/cosmopedia-100k data/train-00000-of-00002.parquet --local_dir ./dir然后查看第一条数据:

我们使用prompt作为我们后续生成的模板即可。
2、根据prompt生成数据
为快速、高效的生成数据,我们采用vllm框架实现,使用Qwen2.5-3B-Base模型,在开头环境安装和平台准备中,我们提醒道,因为vllm把本地的GPU完全利用,因此显存占用会比较高,3B的模型需要37-38GB左右,如果资源受限,可以使用更小的模型尝试,不过生成效果就不一定很好了。
我们先开启vllm,模型采用本地保存的模型地址:
vllm serve /home/lixinyu/weights/Qwen2.5-3B然后运行生成代码:
python generation.py不过需要注意的是,我们仅为了提供示例,下载.parquet格式数据,读取的时候也针对.parquet格式,如果你采用的是完整数据,请调整下面的代码:

我们的例子中只生成了20条数据,只需要两分钟时间,生成结果如下:

接下来我们看下如何处理数据。
3、数据筛选、去重等
首先关于数据筛选,huggingface团队给出的HuggingFaceTB/cosmopedia-100k数据集已经经过了筛选环节,我们只是使用筛选后的数据集进行生成,因此这里不多赘述,有兴趣了解的朋友可以查看官方给出的web数据筛选代码,其实就是预设题目筛选,我们主要来实现数据去重。
cosmopedia团队利用datatrove库中的Minhash实现数据去重,代码在此,然后我们的代码在这👉ours。
因为我们不需要Slurm集群来实现大规模数据去重,仅仅实现少量数据,因此我们使用本地的服务器就行,对于官方代码中的所有SlurmPipelineExecutor改成LocalPipelineExecutor,具体原理可参考datatrove的本地pipeline设置。
这段代码通过 Minhash 算法,也就是哈希去重的方法实现文本去重,哈希去重通过将任意长度文本转化为固定长度哈希值,既能大幅压缩数据规模,又能利用 “相同文本生成相同哈希值” 的特性快速判断重复,避免直接比对原始文本的冗余计算。其计算速度快且存储成本低,非常适合海量数据场景,像 Minhash 这类算法还能捕捉文本相似性,不仅检测完全重复,还能识别高度相似内容。同时,结合分桶、聚类等策略可进一步减少比对次数,显著提升大规模数据处理的效率,最终实现高效、精准的重复内容识别与过滤。
整个流程分四个阶段完成重复检测与过滤。
- 首先配置 Minhash 参数,包括哈希精度、桶数量和每个桶的哈希数,这些参数直接影响去重精度和效率。MinhashDedupSignature 组件为每条英文文本数据生成独特签名然后保存,签名作为文本的紧凑表示,在保留特征的同时减少数据量,且通过多进程并行处理提升效率。
- 第二阶段进行签名分桶匹配,从签名文件夹读取数据,按配置的桶数量将相似签名文本归入同一桶中。这种分桶策略缩小了后续比较范围,避免全量两两比对,大幅提高处理效率。
- 第三阶段基于桶结果聚类,从桶文件夹读取数据,将重复文本聚合成簇,确定需移除的重复数据 ID,明确重复文本对象,为最终过滤做准备。
- 第四阶段完成重复过滤:这一阶段再次读取原始数据,指定文本字段为 “generated_text”(我们的数据保存到这里,当然也可以命名其他字段);然后依据 remove_ids 信息过滤重复数据,被移除数据由 exclusion_writer 保存到 removed 文件夹,剩余非重复数据单独保存。
运行下面的代码👇:
python data_depulication.py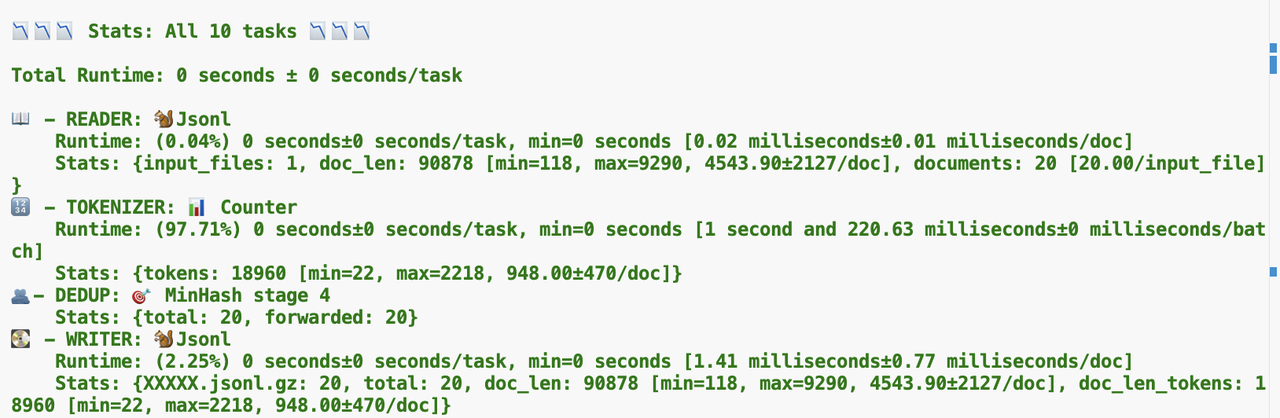
当看到上图表示完成数据去重,并且成功保存好数据,保存好的文件是gz压缩包,我们可以执行下面的代码👇,将压缩包文件转换成jsonl文件,这样你就完成了最终的数据去重操作。
python data_format_conversion.py其实从上面的结果中,我们可以知道,所有数据都没有重复的,这是当然的,因为:
- 我们的数据量很少,仅作为例子,20条数据想重复都比较难
- 我们随机从100k条(当然我们只下载了50k条)数据,从中随机选择20条prompt,主题重复的概率极低,那生成的数据的重复的概率也很低
微调数据
关于微调数据的合成,提供了完整的合成instruct数据的代码,完整的生成流程我们在前文已经讲过,我们再简单总结下:
- 生成任务指令
- 判断指令是否属于分类任务
- 采用输入优先或输出优先的方式进行实例生成
- 过滤低质量数据
完整的四步在生成代码里,具体看generate_instruction_following_data部分,基本按照生成流程的顺序实现,openai对应的API接口处理代码在工具里,代码原理也很简单,我们就不再赘述。
我们提供了简易的生成代码,链接在这,代码构成如下:
instruct_data_gengeration/
├── generate_instruction.py # 数据生成
├── utils.py # openai接口设计以及其他工具等
├── prompt.txt # 生成instruction的提示词
├── seed_tasks.jsonl # 种子任务
└── data/ # 生成的数据保存地址不过因为我们仍然用vllm框架来实现高效生成数据的方法,而官方的代码时间有点久,很多包进行了更新,不一定适配原始的代码,因此我们把需要改动的地方着重强调下。
因为我们希望使用本地保存的模型,重点是model_name_or_path换成我们的本地的模型地址,无论是本地模型Qwen还是默认的GPT系列的text-davinci-003,其实都适配OpenAI的JSON输入接口,因此该函数的整体逻辑不需要进行修改,但是由于openai这个包有更新,细节部分需要修改。
- 首先是openai的Completion换成了
openai.OpenAI.completions,这里需要注意。 - 其次是我们没有走openai的调用API的方法,走的是本地服务器,因此需要把url改成本地的端口地址,一般情况下,默认是8000,代码如下:
client = openai.OpenAI(
# defaults to os.environ.get("OPENAI_API_KEY")
api_key="EMPTY",
base_url="http://127.0.0.1:8000/v1",
)因此第一步的completions需要改成如下形式:
completion_batch = client.completions.create(prompt=prompt_batch, **shared_kwargs)- 最后openai删掉了openai_object,不过这一步基本只是规定输出格式,因此直接删掉所有关联的代码即可
具体的修改好的代码可以参考👉ours
我们先开启vllm,模型采用本地保存的模型地址:
vllm serve /home/lixinyu/weights/Qwen2.5-3B然后我们运行下面的代码,就可以合成微调数据了:
python -m generate_instruction generate_instruction_following_data \
--output_dir ./data \
--num_instructions_to_generate 10 \
--model_name /home/lixinyu/weights/Qwen2.5-3B \
--request_batch_size 2合成的数据如下:
推理数据
由于推理数据需要本身就具备思考过程的模型来实现,我们所熟悉的deepseek-r1还有Qwen3都有思考模块,我们选择Qwen3,为什么选择Qwen而不是DeepSeek,因为我们使用阿里百炼平台通过调用API的形式调用模型来生成数据,Qwen3能快点,DeeSeek-R1有点慢而已,用R1也绝对没有任何问题。
我们提供了简易的生成代码,链接在这,代码构成如下:
instruct_data_gengeration/
├── generate.py # 数据生成
└── data/ # 生成的数据保存地址为方便起见,我们直接选择alpaca中文版的指令和输入作为整体的输入数据,让Qwen3去生成思考+回答,作为我们的推理数据。我们简单分成下面两步:
- 下载Alpaca数据
- 调用Qwen3生成推理数据
我们直接运行下面的代码,就可以完整的生成推理数据:
python generation.py因为我们只是举例说明,我们只生成了10条数据,批量生成数据的话可以修改数量。

参考文献
[1].Textbooks Are All You Need
[2].Textbooks Are All You Need II: phi-1.5 technical report
[3].Cosmopedia: how to create large-scale synthetic data for pre-training