FashionMNIST
INFO
图像分类、机器学习入门、灰度图像
概述
FashionMNIST 是一个广泛用于测试机器学习算法的图像数据集,特别是在图像识别领域。它由 Zalando 发布,旨在替代传统的 MNIST 数据集,后者主要包含手写数字的图片。FashionMNIST 的设计初衷是提供一个稍微更具挑战性的问题,同时保持与原始 MNIST 数据集相同的图像大小(28x28 像素)和结构(训练集60,000张图片,测试集10,000张图片)。

FashionMNIST 包含来自 10 个类别的服装和鞋类商品的灰度图像。这些类别包括:
- T恤/上衣(T-shirt/top)
- 裤子(Trouser)
- 套头衫(Pullover)
- 裙子(Dress)
- 外套(Coat)
- 凉鞋(Sandal)
- 衬衫(Shirt)
- 运动鞋(Sneaker)
- 包(Bag)
- 短靴(Ankle boot)
每个类别都有相同数量的图像,使得这个数据集成为一个平衡的数据集。这些图像的简单性和标准化尺寸使得 FashionMNIST 成为计算机视觉和机器学习领域入门级的理想选择。数据集被广泛用于教育和研究,用于测试各种图像识别方法的效果。
本案例主要:
- 使用
pytorch进行ResNet34(残差神经网络)网络的构建、模型训练与评估 - 使用
swanlab跟踪超参数、记录指标和可视化监控整个训练周期
环境安装
本案例基于Python>=3.8,请在您的计算机上安装好Python。 环境依赖:
torch
torchvision
swanlab快速安装命令:
bash
pip install torch torchvision swanlab完整代码
python
import os
import torch
from torch import nn, optim, utils
import torch.nn.functional as F
from torchvision.datasets import FashionMNIST
from torchvision.transforms import ToTensor
import swanlab
# ResNet网络构建
class Basicblock(nn.Module):
def __init__(self, in_planes, planes, stride=1):
super(Basicblock, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=in_planes, out_channels=planes, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(planes),
nn.ReLU()
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=planes, out_channels=planes, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(planes),
)
if stride != 1 or in_planes != planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels=in_planes, out_channels=planes, kernel_size=3, stride=stride, padding=1),
nn.BatchNorm2d(planes)
)
else:
self.shortcut = nn.Sequential()
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_block, num_classes):
super(ResNet, self).__init__()
self.in_planes = 16
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(16),
nn.ReLU()
)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.block1 = self._make_layer(block, 16, num_block[0], stride=1)
self.block2 = self._make_layer(block, 32, num_block[1], stride=2)
self.block3 = self._make_layer(block, 64, num_block[2], stride=2)
# self.block4 = self._make_layer(block, 512, num_block[3], stride=2)
self.outlayer = nn.Linear(64, num_classes)
def _make_layer(self, block, planes, num_block, stride):
layers = []
for i in range(num_block):
if i == 0:
layers.append(block(self.in_planes, planes, stride))
else:
layers.append(block(planes, planes, 1))
self.in_planes = planes
return nn.Sequential(*layers)
def forward(self, x):
x = self.maxpool(self.conv1(x))
x = self.block1(x) # [200, 64, 28, 28]
x = self.block2(x) # [200, 128, 14, 14]
x = self.block3(x) # [200, 256, 7, 7]
# out = self.block4(out)
x = F.avg_pool2d(x, 7) # [200, 256, 1, 1]
x = x.view(x.size(0), -1) # [200,256]
out = self.outlayer(x)
return out
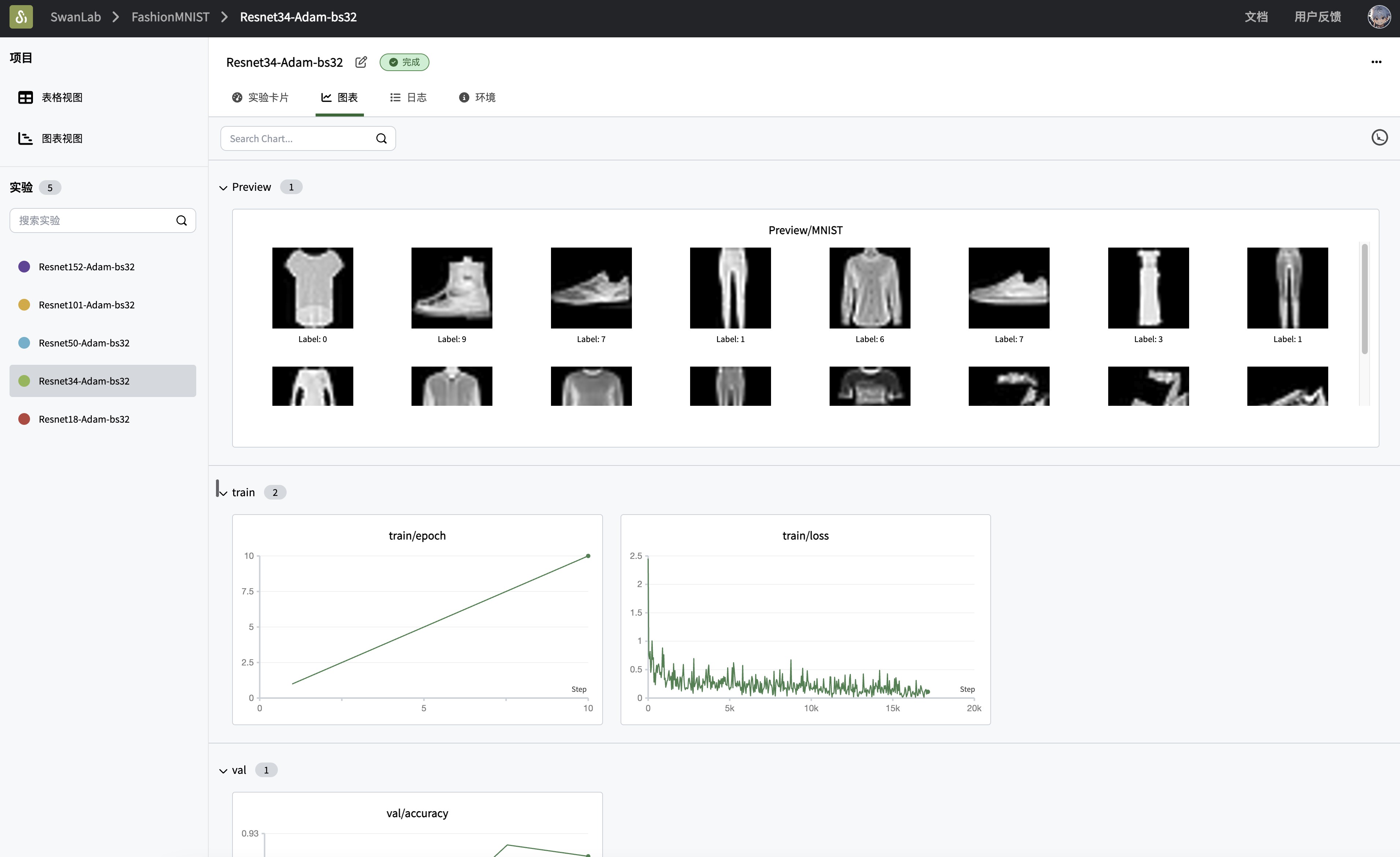
# 捕获并可视化前20张图像
def log_images(loader, num_images=16):
images_logged = 0
logged_images = []
for images, labels in loader:
# images: batch of images, labels: batch of labels
for i in range(images.shape[0]):
if images_logged < num_images:
# 使用swanlab.Image将图像转换为wandb可视化格式
logged_images.append(swanlab.Image(images[i], caption=f"Label: {labels[i]}", size=(128, 128)))
images_logged += 1
else:
break
if images_logged >= num_images:
break
swanlab.log({"Preview/MNIST": logged_images})
if __name__ == "__main__":
# 设置device
try:
use_mps = torch.backends.mps.is_available()
except AttributeError:
use_mps = False
if torch.cuda.is_available():
device = "cuda"
elif use_mps:
device = "mps"
else:
device = "cpu"
# 初始化swanlab
run = swanlab.init(
project="FashionMNIST",
experiment_name="Resnet34-Adam",
config={
"model": "Resnet34",
"optim": "Adam",
"lr": 0.001,
"batch_size": 32,
"num_epochs": 10,
"train_dataset_num": 55000,
"val_dataset_num": 5000,
"device": device,
"num_classes": 10,
},
)
# 设置训练机、验证集和测试集
dataset = FashionMNIST(os.getcwd(), train=True, download=True, transform=ToTensor())
train_dataset, val_dataset = utils.data.random_split(
dataset, [run.config.train_dataset_num, run.config.val_dataset_num]
)
train_loader = utils.data.DataLoader(train_dataset, batch_size=run.config.batch_size, shuffle=True)
val_loader = utils.data.DataLoader(val_dataset, batch_size=1, shuffle=False)
# 初始化模型、损失函数和优化器
if run.config.model == "Resnet18":
model = ResNet(Basicblock, [1, 1, 1, 1], 10)
elif run.config.model == "Resnet34":
model = ResNet(Basicblock, [2, 3, 5, 2], 10)
elif run.config.model == "Resnet50":
model = ResNet(Basicblock, [3, 4, 6, 3], 10)
elif run.config.model == "Resnet101":
model = ResNet(Basicblock, [3, 4, 23, 3], 10)
elif run.config.model == "Resnet152":
model = ResNet(Basicblock, [3, 8, 36, 3], 10)
model.to(torch.device(device))
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=run.config.lr)
# (可选)看一下数据集的前16张图像
log_images(train_loader, 16)
# 开始训练
for epoch in range(1, run.config.num_epochs+1):
swanlab.log({"train/epoch": epoch}, step=epoch)
# 训练循环
for iter, batch in enumerate(train_loader):
x, y = batch
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
output = model(x)
loss = criterion(output, y)
loss.backward()
optimizer.step()
if iter % 40 == 0:
print(
f"Epoch [{epoch}/{run.config.num_epochs}], Iteration [{iter + 1}/{len(train_loader)}], Loss: {loss.item()}"
)
swanlab.log({"train/loss": loss.item()}, step=(epoch - 1) * len(train_loader) + iter)
# 每4个epoch验证一次
if epoch % 2 == 0:
model.eval()
correct = 0
total = 0
with torch.no_grad():
for batch in val_loader:
x, y = batch
x, y = x.to(device), y.to(device)
output = model(x)
_, predicted = torch.max(output, 1)
total += y.size(0)
correct += (predicted == y).sum().item()
accuracy = correct / total
swanlab.log({"val/accuracy": accuracy}, step=epoch)切换其他ResNet模型
上面的代码支持切换以下ResNet模型:
- ResNet18
- ResNet34
- ResNet50
- ResNet101
- ResNet152
切换方式非常简单,只需要将config的model参数修改为对应的模型名称即可,如切换为ResNet50:
python
# 初始化swanlab
run = swanlab.init(
...
config={
"model": "Resnet50",
...
},
)config是如何发挥作用的? 👉 设置实验配置
效果演示