MNIST手写体识别
INFO
图像分类、机器学习入门、灰度图像


概述
MNIST手写体识别是深度学习最经典的入门任务之一,由 LeCun 等人提出。
该任务基于MNIST数据集,研究者通过构建机器学习模型,来识别10个手写数字(0~9)。

本案例主要:
- 使用
pytorch进行CNN(卷积神经网络)的构建、模型训练与评估 - 使用
swanlab跟踪超参数、记录指标和可视化监控整个训练周期
环境安装
本案例基于Python>=3.8,请在您的计算机上安装好Python。
环境依赖:
torch
torchvision
swanlab快速安装命令:
bash
pip install torch torchvision swanlab完整代码
python
import os
import torch
from torch import nn, optim, utils
import torch.nn.functional as F
import torchvision
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
import swanlab
# CNN网络构建
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
# 1,28x28
self.conv1 = nn.Conv2d(1, 10, 5) # 10, 24x24
self.conv2 = nn.Conv2d(10, 20, 3) # 128, 10x10
self.fc1 = nn.Linear(20 * 10 * 10, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
in_size = x.size(0)
out = self.conv1(x) # 24
out = F.relu(out)
out = F.max_pool2d(out, 2, 2) # 12
out = self.conv2(out) # 10
out = F.relu(out)
out = out.view(in_size, -1)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
out = F.log_softmax(out, dim=1)
return out
# 捕获并可视化前20张图像
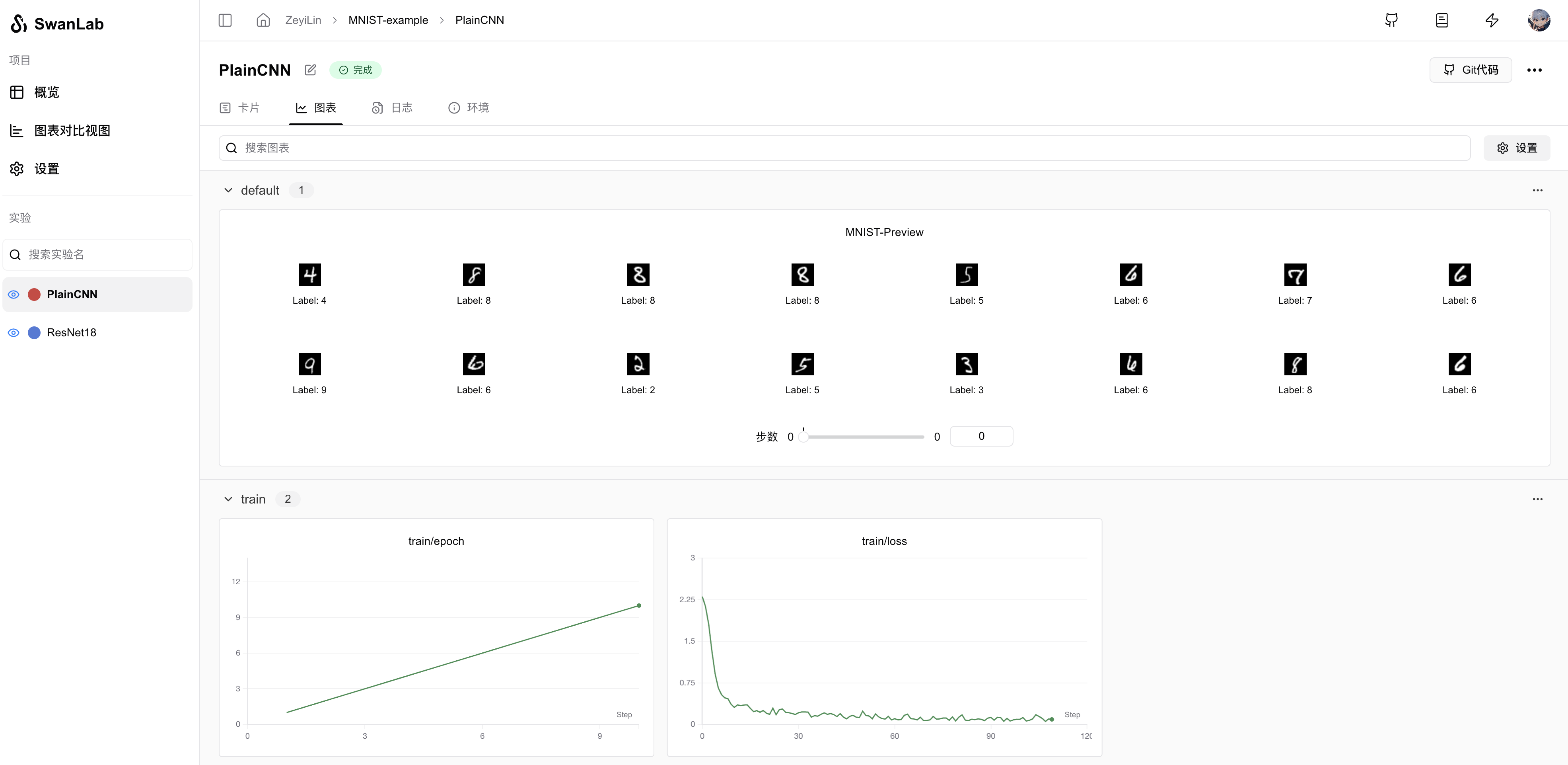
def log_images(loader, num_images=16):
images_logged = 0
logged_images = []
for images, labels in loader:
# images: batch of images, labels: batch of labels
for i in range(images.shape[0]):
if images_logged < num_images:
# 使用swanlab.Image将图像转换为wandb可视化格式
logged_images.append(swanlab.Image(images[i], caption=f"Label: {labels[i]}"))
images_logged += 1
else:
break
if images_logged >= num_images:
break
swanlab.log({"MNIST-Preview": logged_images})
def train(model, device, train_dataloader, optimizer, criterion, epoch, num_epochs):
model.train()
# 1. 循环调用train_dataloader,每次取出1个batch_size的图像和标签
for iter, (inputs, labels) in enumerate(train_dataloader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
# 2. 传入到resnet18模型中得到预测结果
outputs = model(inputs)
# 3. 将结果和标签传入损失函数中计算交叉熵损失
loss = criterion(outputs, labels)
# 4. 根据损失计算反向传播
loss.backward()
# 5. 优化器执行模型参数更新
optimizer.step()
print('Epoch [{}/{}], Iteration [{}/{}], Loss: {:.4f}'.format(epoch, num_epochs, iter + 1, len(train_dataloader),
loss.item()))
# 6. 每20次迭代,用SwanLab记录一下loss的变化
if iter % 20 == 0:
swanlab.log({"train/loss": loss.item()})
def test(model, device, val_dataloader, epoch):
model.eval()
correct = 0
total = 0
with torch.no_grad():
# 1. 循环调用val_dataloader,每次取出1个batch_size的图像和标签
for inputs, labels in val_dataloader:
inputs, labels = inputs.to(device), labels.to(device)
# 2. 传入到resnet18模型中得到预测结果
outputs = model(inputs)
# 3. 获得预测的数字
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
# 4. 计算与标签一致的预测结果的数量
correct += (predicted == labels).sum().item()
# 5. 得到最终的测试准确率
accuracy = correct / total
# 6. 用SwanLab记录一下准确率的变化
swanlab.log({"val/accuracy": accuracy}, step=epoch)
if __name__ == "__main__":
#检测是否支持mps
try:
use_mps = torch.backends.mps.is_available()
except AttributeError:
use_mps = False
#检测是否支持cuda
if torch.cuda.is_available():
device = "cuda"
elif use_mps:
device = "mps"
else:
device = "cpu"
# 初始化swanlab
run = swanlab.init(
project="MNIST-example",
experiment_name="PlainCNN",
config={
"model": "ResNet18",
"optim": "Adam",
"lr": 1e-4,
"batch_size": 256,
"num_epochs": 10,
"device": device,
},
)
# 设置MNIST训练集和验证集
dataset = MNIST(os.getcwd(), train=True, download=True, transform=ToTensor())
train_dataset, val_dataset = utils.data.random_split(dataset, [55000, 5000])
train_dataloader = utils.data.DataLoader(train_dataset, batch_size=run.config.batch_size, shuffle=True)
val_dataloader = utils.data.DataLoader(val_dataset, batch_size=8, shuffle=False)
# (可选)看一下数据集的前16张图像
log_images(train_dataloader, 16)
# 初始化模型
model = ConvNet()
model.to(torch.device(device))
# 打印模型
print(model)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=run.config.lr)
# 开始训练和测试循环
for epoch in range(1, run.config.num_epochs+1):
swanlab.log({"train/epoch": epoch}, step=epoch)
train(model, device, train_dataloader, optimizer, criterion, epoch, run.config.num_epochs)
if epoch % 2 == 0:
test(model, device, val_dataloader, epoch)
# 保存模型
# 如果不存在checkpoint文件夹,则自动创建一个
if not os.path.exists("checkpoint"):
os.makedirs("checkpoint")
torch.save(model.state_dict(), 'checkpoint/latest_checkpoint.pth')效果演示