DQN-CartPole

训练过程:RL-All-In-One
硬件环境:纯CPU可训,实测M1 Max训练3分30秒
一、什么是DQN?
DQN(Deep Q-Network,深度Q网络)是Q-Learning的深度学习扩展,通过神经网络替代Q表的方式来解决高维状态空间问题(例如图像输入),开启了深度强化学习时代。它在2013年由DeepMind提出,并在Atari游戏上取得了突破性表现。
传统的Q-Learning方法很好,但是Q表是个离散的结构,无法处理状态是连续的任务;以及一些状态空间巨大的任务(比如视频游戏),Q表的开销也是无法接受的,所以DQN应运而生。DQN用神经网络(称为QNet)近似Q函数,输入状态S,输出所有动作的Q值。
DQN还做了以下改进:
- 经验回放(Experience Replay) :存储历史经验(st,at,rt+1,st+1)(st,at,rt+1,st+1)到缓冲区,训练时随机采样,打破数据相关性。
- 目标网络(Target Network) :使用独立的网络计算目标Q值,减少训练波动。
- 端到端训练:直接从原始输入(如像素)学习,无需人工设计状态特征。
具体DQN原理本文不做过多赘述,结合本文提供的代码和网上其他教程/DeepSeek R1学习,会有更好效果。
二、什么是CartPole推车倒立摆任务?
CartPole(推车倒立摆) 是强化学习中经典的基准测试任务,因为其直观可视、方便调试、状态和动作空间小等特性,常用于入门教学和算法验证。它的目标是训练一个智能体(agent)通过左右移动小车,使车顶的杆子尽可能长时间保持竖直不倒。
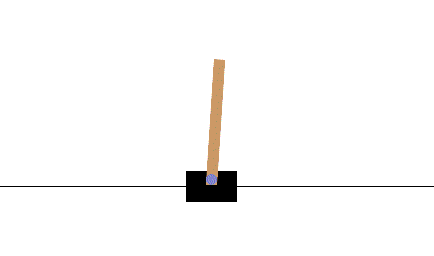
- 环境:小车(cart)可以在水平轨道上左右移动,顶部通过关节连接一根自由摆动的杆子(pole)。
- 目标:通过左右移动小车,使杆子的倾斜角度不超出阈值(±12°或±15°),同时小车不超出轨道范围(如轨道长度的±2.4单位)。简单理解为,就是杆子不会倒下里,小车不会飞出屏幕。
- 状态:状态空间包含4个连续变量,分别是小车位置(x),小车速度(v),杆子角度(θ),杆子角速度(ω)
- 动作:动作空间只有2个离线动作,分别是0(向左移动)或1(向右移动)
- 奖励机制:每成功保持杆子不倒+1分,目前是让奖励最大化,即杆子永远不倒
使用gymnasium库,启动cartpole环境非常容易,下面是一个简单的示例代码:
import gymnasium as gym
env = gym.make("CartPole-v1")
state = env.reset()
done = False
while not done:
action = 0 if state[2] < 0 else 1 # 根据杆子角度简单决策
next_state, reward, done, _ = env.step(action)
state = next_state
env.render()三、安装环境
首先你需要1个Python>=3.8的环境,然后安装下面的库:
swanlab
gymnasium
numpy
torch
pygame
moviepy一键安装命令:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install swanlab gymnasium numpy torch pygame moviepy四、定义QNet
DQN使用神经网络来近似QLearning中的Q表,这个神经网络被称为QNetwork。
QNetwork的输入是状态向量,输出是动作向量,这里用一个非常简单的神经网络:
class QNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(state_dim, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, action_dim)
)
self.to(device) # 将网络移到指定设备
def forward(self, x):
return self.fc(x)五、定义DQNAgent
DQNAgent定义了一系列强化学习训练的行为,代码略长,我拿部分内容进行解读:
初始配置
class DQNAgent:
def __init__(self, state_dim, action_dim):
self.q_net = QNetwork(state_dim, action_dim) # 当前网络
self.target_net = QNetwork(state_dim, action_dim) # 目标网络
self.target_net.load_state_dict(self.q_net.state_dict()) # 将目标网络和当前网络初始化一致,避免网络不一致导致的训练波动
self.optimizer = optim.Adam(self.q_net.parameters(), lr=1e-3)
self.replay_buffer = deque(maxlen=10000) # 经验回放缓冲区
self.update_target_freq = 100DQN会定义2个神经网络,分别是q_net和target_net,结构是完全相同的。训练过程中,target_net负责计算预期值,即 reward + target_net(next_state).max(1)[0] ,q_net负责计算当前值,训练时将两个值送到MSELoss里计算差值,反向传播后更新q_net的参数;每过update_target_freq步,将q_net的参数赋给target_net。
优化器使用Adam;经验回访缓冲区是最大长度为10000的队列,用于存储历史经验用于训练。
动作选择(ε-贪婪策略)
动作选择的ε-贪婪策略,指的是在当前状态下,选择下一个动作时的两种方式:
A. 随机选择1个动作,这种被称为探索
B. 按照先前训练得到的知识选择动作。
在强化学习训练中,每一步会以epsilon(即ε)的概率选择A,否则选择B:
def choose_action(self, state):
if np.random.rand() < self.epsilon:
return np.random.randint(0, 2) # CartPole有2个动作(左/右)
else:
state_tensor = torch.FloatTensor(state).to(device)
q_values = self.q_net(state_tensor)
return q_values.cpu().detach().numpy().argmax()在训练中,开始时以高概率随机探索环境,逐渐转向利用学到的知识。
六、完整代码
下面是DQN训练的完整代码,做了这些事:
- 开启gymnasium中的CartPole环境
- QAgent按照ε-贪婪策略选择动作,更新状态,训练模型更新q_net参数
- 每隔固定的步数,同步target_net的参数
- 一共训练600轮,每10轮会进行一次评估,并使用swanlab记录参数
- 保存评估时最高reward的模型权重
- 使用了经验回放与ε衰减策略
- 训练完成后,进行测试,并保存测试视频到本地目录下
完整代码如下:
import gymnasium as gym
from gymnasium.wrappers import RecordVideo
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from collections import deque
import random
import swanlab
import os
# 设置随机数种子
SEED = 42
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
# 定义Q网络
class QNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(state_dim, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, action_dim)
)
def forward(self, x):
return self.fc(x)
# DQN Agent
class DQNAgent:
def __init__(self, state_dim, action_dim):
self.q_net = QNetwork(state_dim, action_dim) # 当前网络
self.target_net = QNetwork(state_dim, action_dim) # 目标网络
self.target_net.load_state_dict(self.q_net.state_dict()) # 将目标网络和当前网络初始化一致,避免网络不一致导致的训练波动
self.best_net = QNetwork(state_dim, action_dim)
self.optimizer = optim.Adam(self.q_net.parameters(), lr=1e-3)
self.replay_buffer = deque(maxlen=10000) # 经验回放缓冲区
self.batch_size = 64
self.gamma = 0.99
self.epsilon = 0.1
self.update_target_freq = 100 # 目标网络更新频率
self.step_count = 0
self.best_reward = 0
self.best_avg_reward = 0
self.eval_episodes = 5 # 评估时的episode数量
def choose_action(self, state):
if np.random.rand() < self.epsilon:
return np.random.randint(0, 2) # CartPole有2个动作(左/右)
else:
state_tensor = torch.FloatTensor(state)
q_values = self.q_net(state_tensor)
return q_values.cpu().detach().numpy().argmax()
def store_experience(self, state, action, reward, next_state, done):
self.replay_buffer.append((state, action, reward, next_state, done))
def train(self):
if len(self.replay_buffer) < self.batch_size:
return
# 从缓冲区随机采样
batch = random.sample(self.replay_buffer, self.batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
states = torch.FloatTensor(np.array(states))
actions = torch.LongTensor(actions)
rewards = torch.FloatTensor(rewards)
next_states = torch.FloatTensor(np.array(next_states))
dones = torch.FloatTensor(dones)
# 计算当前Q值
current_q = self.q_net(states).gather(1, actions.unsqueeze(1)).squeeze()
# 计算目标Q值(使用目标网络)
with torch.no_grad():
next_q = self.target_net(next_states).max(1)[0]
target_q = rewards + self.gamma * next_q * (1 - dones)
# 计算损失并更新网络
loss = nn.MSELoss()(current_q, target_q)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 定期更新目标网络
self.step_count += 1
if self.step_count % self.update_target_freq == 0:
# 使用深拷贝更新目标网络参数
self.target_net.load_state_dict({
k: v.clone() for k, v in self.q_net.state_dict().items()
})
def save_model(self, path="./output/best_model.pth"):
if not os.path.exists("./output"):
os.makedirs("./output")
torch.save(self.q_net.state_dict(), path)
print(f"Model saved to {path}")
def evaluate(self, env):
"""评估当前模型的性能"""
original_epsilon = self.epsilon
self.epsilon = 0 # 关闭探索
total_rewards = []
for _ in range(self.eval_episodes):
state = env.reset()[0]
episode_reward = 0
while True:
action = self.choose_action(state)
next_state, reward, done, _, _ = env.step(action)
episode_reward += reward
state = next_state
if done or episode_reward > 2e4:
break
total_rewards.append(episode_reward)
self.epsilon = original_epsilon # 恢复探索
return np.mean(total_rewards)
# 训练过程
env = gym.make('CartPole-v1')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = DQNAgent(state_dim, action_dim)
# 初始化SwanLab日志记录器
swanlab.init(
project="RL-All-In-One",
experiment_name="DQN-CartPole-v1",
config={
"state_dim": state_dim,
"action_dim": action_dim,
"batch_size": agent.batch_size,
"gamma": agent.gamma,
"epsilon": agent.epsilon,
"update_target_freq": agent.update_target_freq,
"replay_buffer_size": agent.replay_buffer.maxlen,
"learning_rate": agent.optimizer.param_groups[0]['lr'],
"episode": 600,
"epsilon_start": 1.0,
"epsilon_end": 0.01,
"epsilon_decay": 0.995,
},
description="增加了初始化目标网络和当前网络一致,避免网络不一致导致的训练波动"
)
# ========== 训练阶段 ==========
agent.epsilon = swanlab.config["epsilon_start"]
for episode in range(swanlab.config["episode"]):
state = env.reset()[0]
total_reward = 0
while True:
action = agent.choose_action(state)
next_state, reward, done, _, _ = env.step(action)
agent.store_experience(state, action, reward, next_state, done)
agent.train()
total_reward += reward
state = next_state
if done or total_reward > 2e4:
break
# epsilon是探索系数,随着每一轮训练,epsilon 逐渐减小
agent.epsilon = max(swanlab.config["epsilon_end"], agent.epsilon * swanlab.config["epsilon_decay"])
# 每10个episode评估一次模型
if episode % 10 == 0:
eval_env = gym.make('CartPole-v1')
avg_reward = agent.evaluate(eval_env)
eval_env.close()
if avg_reward > agent.best_avg_reward:
agent.best_avg_reward = avg_reward
# 深拷贝当前最优模型的参数
agent.best_net.load_state_dict({k: v.clone() for k, v in agent.q_net.state_dict().items()})
agent.save_model(path=f"./output/best_model.pth")
print(f"New best model saved with average reward: {avg_reward}")
print(f"Episode: {episode}, Train Reward: {total_reward}, Best Eval Avg Reward: {agent.best_avg_reward}")
swanlab.log(
{
"train/reward": total_reward,
"eval/best_avg_reward": agent.best_avg_reward,
"train/epsilon": agent.epsilon
},
step=episode,
)
# 测试并录制视频
agent.epsilon = 0 # 关闭探索策略
test_env = gym.make('CartPole-v1', render_mode='rgb_array')
test_env = RecordVideo(test_env, "./dqn_videos", episode_trigger=lambda x: True) # 保存所有测试回合
agent.q_net.load_state_dict(agent.best_net.state_dict()) # 使用最佳模型
for episode in range(3): # 录制3个测试回合
state = test_env.reset()[0]
total_reward = 0
steps = 0
while True:
action = agent.choose_action(state)
next_state, reward, done, _, _ = test_env.step(action)
total_reward += reward
state = next_state
steps += 1
# 限制每个episode最多1500步,约30秒,防止录制时间过长
if done or steps >= 1500:
break
print(f"Test Episode: {episode}, Reward: {total_reward}")
test_env.close()训练用的是SwanLab的记录过程,能更好地分析和总结知识。
在开始训练之前,如果你没有使用过SwanLab,需要去它的官网(https://swanlab.cn)注册一下,然后按下面的步骤复制API Key:
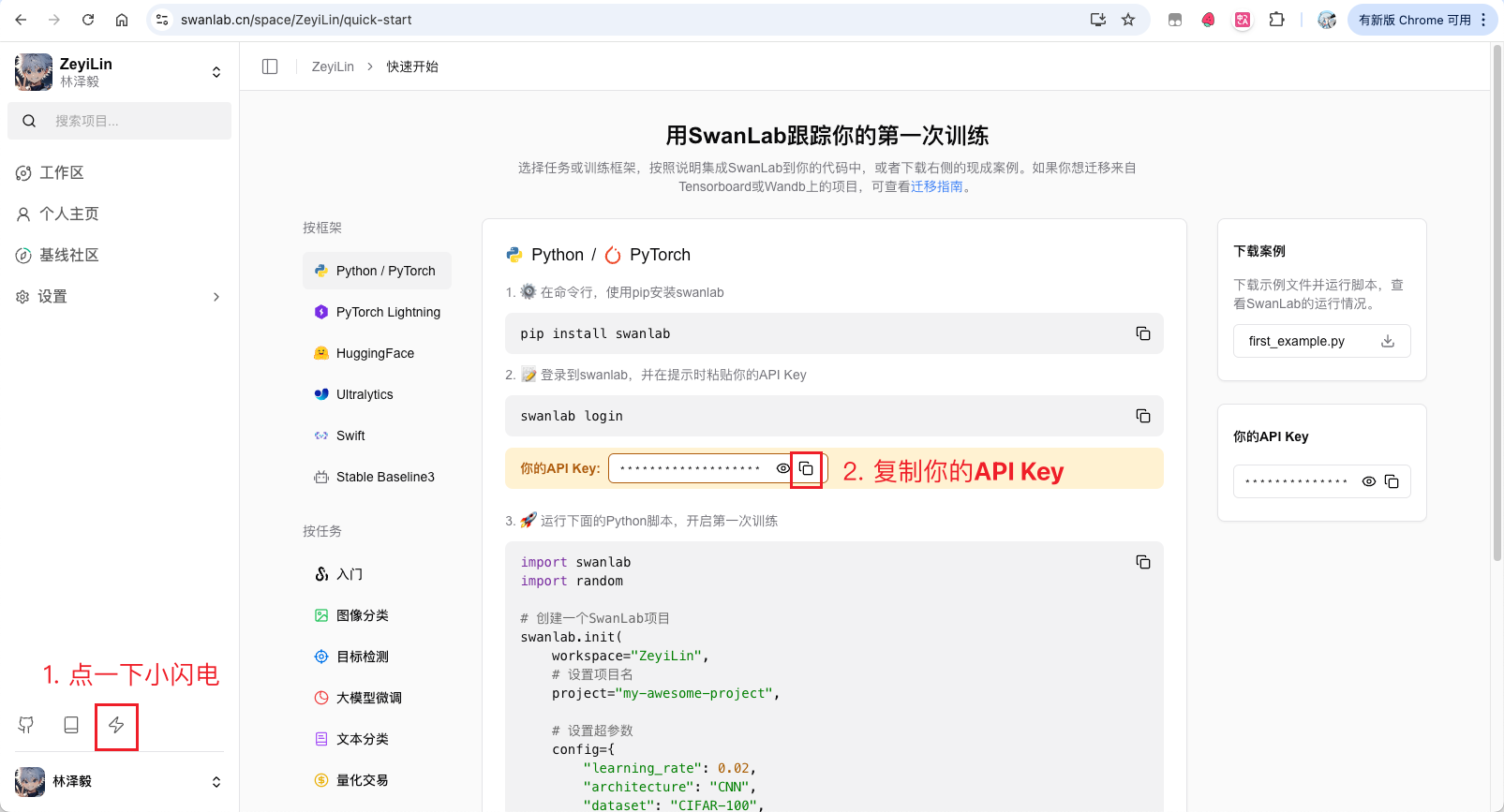
接下来打开命令行,敲下面的命令:
swanlab login在弹出的提示中,把API Key粘贴进去(粘贴进去不会显示任何东西,放心这是正常的),然后按回车,登录完毕!
然后,就可以运行训练代码了。
七、训练结果
训练过程可以看:RL-All-In-One - SwanLab
我的机器是Macbook M1 Max,大概训练了3分30秒。
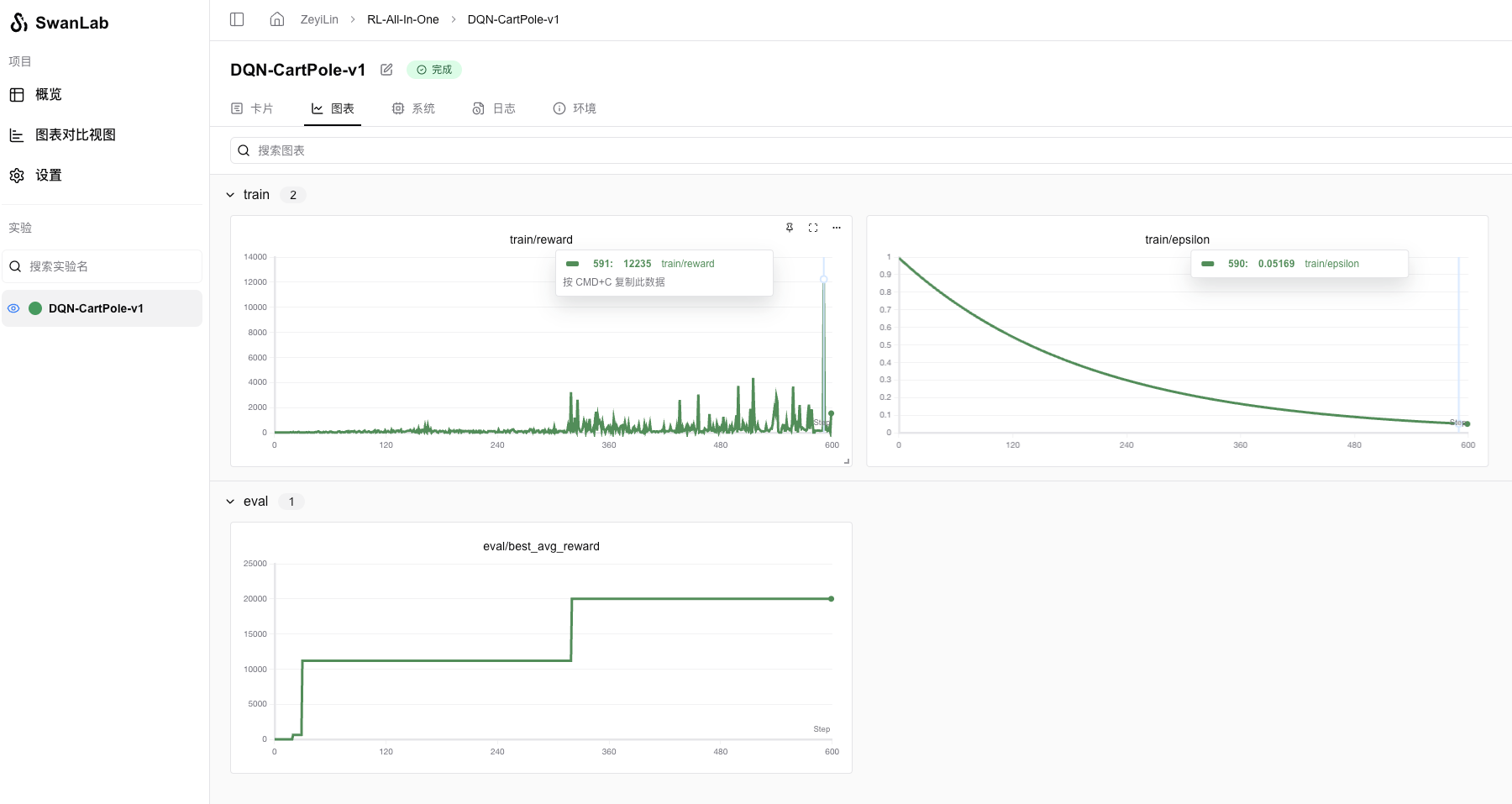
可以看到train的reward波动的很厉害,因为随机探索的缘故,但eval(关闭随机探索)可以看到是很快达到了20000分的上限。
下面是训练好的Agent控制倒立摆的30s视频: