
DQN-CartPole
Training Process: RL-All-In-One
Code: Zeyi-Lin/SwanBook-RL
Hardware Environment: Can be trained on CPU only, tested on M1 Max with a training time of 3 minutes and 30 seconds.
1. What is DQN?
DQN (Deep Q-Network) is a deep learning extension of Q-Learning, which uses neural networks to replace Q-tables to solve high-dimensional state space problems (such as image input), ushering in the era of deep reinforcement learning. It was proposed by DeepMind in 2013 and achieved breakthrough performance on Atari games.
Traditional Q-Learning methods are good, but Q-tables are discrete structures and cannot handle tasks with continuous states. Additionally, for tasks with huge state spaces (such as video games), the overhead of Q-tables is unacceptable. Hence, DQN was born. DQN uses a neural network (called QNet) to approximate the Q-function, taking the state S as input and outputting the Q-values for all actions.
DQN also introduces the following improvements:
- Experience Replay: Stores historical experiences (st, at, rt+1, st+1) in a buffer and randomly samples them during training to break data correlations.
- Target Network: Uses a separate network to compute target Q-values, reducing training fluctuations.
- End-to-End Training: Learns directly from raw inputs (such as pixels) without the need for manually designed state features.
This article will not delve too much into the specifics of DQN. Combining the provided code with other tutorials/DeepSeek R1 learning will yield better results.
2. What is the CartPole Task?
CartPole is a classic benchmark task in reinforcement learning. Due to its intuitive visualization, ease of debugging, and small state and action spaces, it is often used for introductory teaching and algorithm validation. The goal is to train an agent to move a cart left or right to keep a pole on top of the cart balanced for as long as possible.
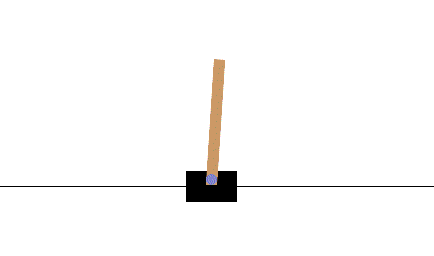
- Environment: A cart can move left or right on a horizontal track, with a freely swinging pole attached to the top via a joint.
- Goal: By moving the cart left or right, keep the pole's tilt angle within a threshold (±12° or ±15°), while ensuring the cart does not go out of bounds (e.g., ±2.4 units of the track length). Simply put, the pole should not fall, and the cart should not fly off the screen.
- State: The state space consists of 4 continuous variables: cart position (x), cart velocity (v), pole angle (θ), and pole angular velocity (ω).
- Action: The action space has only 2 discrete actions: 0 (move left) or 1 (move right).
- Reward Mechanism: +1 point for each step the pole remains balanced. The goal is to maximize the reward, meaning the pole never falls.
Using the gymnasium library, starting the CartPole environment is very easy. Here is a simple example code:
import gymnasium as gym
env = gym.make("CartPole-v1")
state = env.reset()
done = False
while not done:
action = 0 if state[2] < 0 else 1 # Simple decision based on pole angle
next_state, reward, done, _ = env.step(action)
state = next_state
env.render()3. Setting Up the Environment
First, you need a Python environment with version >= 3.8. Then install the following libraries:
swanlab
gymnasium
numpy
torch
pygame
moviepyOne-command installation:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install swanlab gymnasium numpy torch pygame moviepy4. Defining QNet
DQN uses a neural network to approximate the Q-table in Q-Learning. This neural network is called QNetwork.
QNetwork takes the state vector as input and outputs the action vector. Here, a very simple neural network is used:
class QNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(state_dim, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, action_dim)
)
self.to(device) # Move the network to the specified device
def forward(self, x):
return self.fc(x)5. Defining DQNAgent
DQNAgent defines a series of behaviors for reinforcement learning training. The code is a bit long, so I'll interpret part of it:
Initial Configuration
class DQNAgent:
def __init__(self, state_dim, action_dim):
self.q_net = QNetwork(state_dim, action_dim) # Current network
self.target_net = QNetwork(state_dim, action_dim) # Target network
self.target_net.load_state_dict(self.q_net.state_dict()) # Initialize target network and current network to be the same to avoid training fluctuations due to network inconsistency
self.optimizer = optim.Adam(self.q_net.parameters(), lr=1e-3)
self.replay_buffer = deque(maxlen=10000) # Experience replay buffer
self.update_target_freq = 100DQN defines two neural networks: q_net and target_net, which have identical structures. During training, target_net is responsible for computing the expected value, i.e., reward + target_net(next_state).max(1)[0], while q_net computes the current value. During training, these two values are fed into MSELoss to compute the difference, and after backpropagation, the parameters of q_net are updated. Every update_target_freq steps, the parameters of q_net are assigned to target_net.
The optimizer uses Adam; the experience replay buffer is a queue with a maximum length of 10,000, used to store historical experiences for training.
Action Selection (ε-Greedy Policy)
The ε-greedy policy for action selection refers to two ways of choosing the next action in the current state:
A. Randomly select an action, known as exploration.
B. Choose an action based on previously learned knowledge.
In reinforcement learning training, at each step, there is an epsilon (ε) probability of choosing A, otherwise B is chosen:
def choose_action(self, state):
if np.random.rand() < self.epsilon:
return np.random.randint(0, 2) # CartPole has 2 actions (left/right)
else:
state_tensor = torch.FloatTensor(state).to(device)
q_values = self.q_net(state_tensor)
return q_values.cpu().detach().numpy().argmax()During training, the agent starts by exploring the environment with a high probability of random actions, gradually shifting to exploiting learned knowledge.
6. Complete Code
Below is the complete code for DQN training, which does the following:
- Starts the CartPole environment in gymnasium.
- QAgent selects actions according to the ε-greedy policy, updates the state, and trains the model to update q_net parameters.
- Synchronizes target_net parameters at fixed intervals.
- Trains for a total of 600 episodes, evaluating every 10 episodes and recording parameters with swanlab.
- Saves the model weights with the highest reward during evaluation.
- Uses experience replay and ε-decay strategy.
- After training, performs testing and saves the test video to a local directory.
Complete code:
import gymnasium as gym
from gymnasium.wrappers import RecordVideo
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from collections import deque
import random
import swanlab
import os
# Set random seed
SEED = 42
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
# Define Q-network
class QNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(state_dim, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, action_dim)
)
def forward(self, x):
return self.fc(x)
# DQN Agent
class DQNAgent:
def __init__(self, state_dim, action_dim):
self.q_net = QNetwork(state_dim, action_dim) # Current network
self.target_net = QNetwork(state_dim, action_dim) # Target network
self.target_net.load_state_dict(self.q_net.state_dict()) # Initialize target network and current network to be the same to avoid training fluctuations due to network inconsistency
self.best_net = QNetwork(state_dim, action_dim)
self.optimizer = optim.Adam(self.q_net.parameters(), lr=1e-3)
self.replay_buffer = deque(maxlen=10000) # Experience replay buffer
self.batch_size = 64
self.gamma = 0.99
self.epsilon = 0.1
self.update_target_freq = 100 # Target network update frequency
self.step_count = 0
self.best_reward = 0
self.best_avg_reward = 0
self.eval_episodes = 5 # Number of episodes for evaluation
def choose_action(self, state):
if np.random.rand() < self.epsilon:
return np.random.randint(0, 2) # CartPole has 2 actions (left/right)
else:
state_tensor = torch.FloatTensor(state)
q_values = self.q_net(state_tensor)
return q_values.cpu().detach().numpy().argmax()
def store_experience(self, state, action, reward, next_state, done):
self.replay_buffer.append((state, action, reward, next_state, done))
def train(self):
if len(self.replay_buffer) < self.batch_size:
return
# Randomly sample from the buffer
batch = random.sample(self.replay_buffer, self.batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
states = torch.FloatTensor(np.array(states))
actions = torch.LongTensor(actions)
rewards = torch.FloatTensor(rewards)
next_states = torch.FloatTensor(np.array(next_states))
dones = torch.FloatTensor(dones)
# Compute current Q-values
current_q = self.q_net(states).gather(1, actions.unsqueeze(1)).squeeze()
# Compute target Q-values (using target network)
with torch.no_grad():
next_q = self.target_net(next_states).max(1)[0]
target_q = rewards + self.gamma * next_q * (1 - dones)
# Compute loss and update network
loss = nn.MSELoss()(current_q, target_q)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# Periodically update target network
self.step_count += 1
if self.step_count % self.update_target_freq == 0:
# Use deep copy to update target network parameters
self.target_net.load_state_dict({
k: v.clone() for k, v in self.q_net.state_dict().items()
})
def save_model(self, path="./output/best_model.pth"):
if not os.path.exists("./output"):
os.makedirs("./output")
torch.save(self.q_net.state_dict(), path)
print(f"Model saved to {path}")
def evaluate(self, env):
"""Evaluate the current model's performance"""
original_epsilon = self.epsilon
self.epsilon = 0 # Turn off exploration
total_rewards = []
for _ in range(self.eval_episodes):
state = env.reset()[0]
episode_reward = 0
while True:
action = self.choose_action(state)
next_state, reward, done, _, _ = env.step(action)
episode_reward += reward
state = next_state
if done or episode_reward > 2e4:
break
total_rewards.append(episode_reward)
self.epsilon = original_epsilon # Restore exploration
return np.mean(total_rewards)
# Training process
env = gym.make('CartPole-v1')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = DQNAgent(state_dim, action_dim)
# Initialize SwanLab logger
swanlab.init(
project="RL-All-In-One",
experiment_name="DQN-CartPole-v1",
config={
"state_dim": state_dim,
"action_dim": action_dim,
"batch_size": agent.batch_size,
"gamma": agent.gamma,
"epsilon": agent.epsilon,
"update_target_freq": agent.update_target_freq,
"replay_buffer_size": agent.replay_buffer.maxlen,
"learning_rate": agent.optimizer.param_groups[0]['lr'],
"episode": 600,
"epsilon_start": 1.0,
"epsilon_end": 0.01,
"epsilon_decay": 0.995,
},
description="Added initialization of target network and current network to be the same to avoid training fluctuations due to network inconsistency"
)
# ========== Training Phase ==========
agent.epsilon = swanlab.config["epsilon_start"]
for episode in range(swanlab.config["episode"]):
state = env.reset()[0]
total_reward = 0
while True:
action = agent.choose_action(state)
next_state, reward, done, _, _ = env.step(action)
agent.store_experience(state, action, reward, next_state, done)
agent.train()
total_reward += reward
state = next_state
if done or total_reward > 2e4:
break
# Epsilon is the exploration coefficient, which gradually decreases with each training episode
agent.epsilon = max(swanlab.config["epsilon_end"], agent.epsilon * swanlab.config["epsilon_decay"])
# Evaluate the model every 10 episodes
if episode % 10 == 0:
eval_env = gym.make('CartPole-v1')
avg_reward = agent.evaluate(eval_env)
eval_env.close()
if avg_reward > agent.best_avg_reward:
agent.best_avg_reward = avg_reward
# Deep copy the parameters of the current best model
agent.best_net.load_state_dict({k: v.clone() for k, v in agent.q_net.state_dict().items()})
agent.save_model(path=f"./output/best_model.pth")
print(f"New best model saved with average reward: {avg_reward}")
print(f"Episode: {episode}, Train Reward: {total_reward}, Best Eval Avg Reward: {agent.best_avg_reward}")
swanlab.log(
{
"train/reward": total_reward,
"eval/best_avg_reward": agent.best_avg_reward,
"train/epsilon": agent.epsilon
},
step=episode,
)
# Test and record video
agent.epsilon = 0 # Turn off exploration policy
test_env = gym.make('CartPole-v1', render_mode='rgb_array')
test_env = RecordVideo(test_env, "./dqn_videos", episode_trigger=lambda x: True) # Save all test episodes
agent.q_net.load_state_dict(agent.best_net.state_dict()) # Use the best model
for episode in range(3): # Record 3 test episodes
state = test_env.reset()[0]
total_reward = 0
steps = 0
while True:
action = agent.choose_action(state)
next_state, reward, done, _, _ = test_env.step(action)
total_reward += reward
state = next_state
steps += 1
# Limit each episode to a maximum of 1500 steps, about 30 seconds, to prevent excessively long recordings
if done or steps >= 1500:
break
print(f"Test Episode: {episode}, Reward: {total_reward}")
test_env.close()The training process is recorded using SwanLab, which helps in better analysis and summarization of knowledge.
Before starting the training, if you haven't used SwanLab before, you need to register on its official website (https://swanlab.cn), and then follow the steps below to copy the API Key:
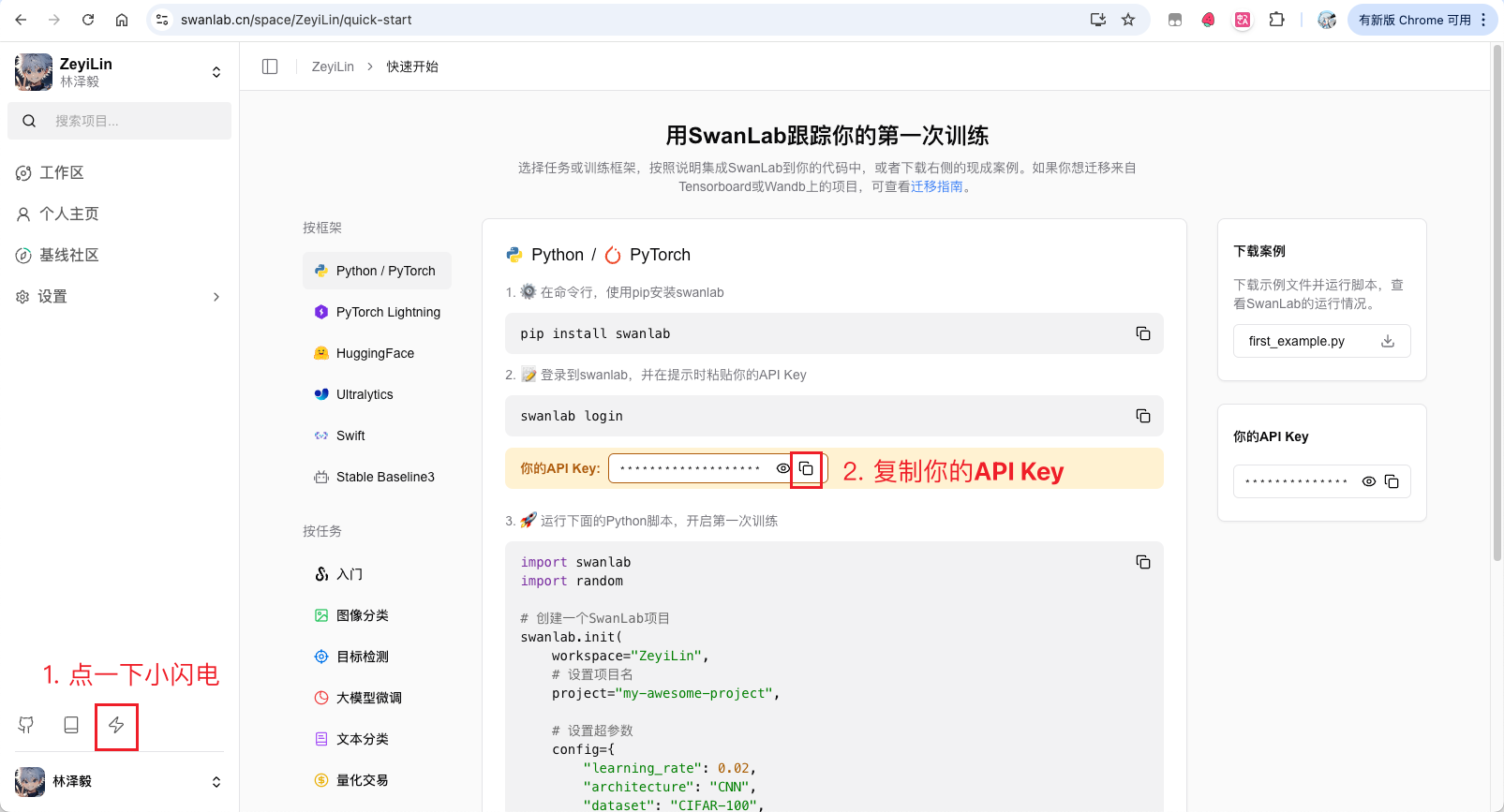
Next, open the command line and type the following command:
swanlab loginIn the prompt that appears, paste the API Key (it won't display anything when pasted, which is normal), then press Enter. You are now logged in!
Then, you can run the training code.
7. Training Results
The training process can be viewed at: RL-All-In-One - SwanLab
My machine is a Macbook M1