Qwen1.5 Fine-Tuning Case Study
INFO
Text Classification, Large Language Models, Fine-Tuning Large Models
Experiment Process | Qwen2 Fine-Tuning Tutorial
Overview
Qwen1.5 is an open-source large language model developed by the Qwen team from Alibaba Cloud's Tongyi Lab. Using Qwen-1.5 as the base model, high-accuracy text classification can be achieved through task-specific fine-tuning, making it an excellent entry task for learning large language model fine-tuning.

Fine-tuning is a process of further training LLMs on a dataset consisting of (input, output) pairs. This process helps the LLM perform better on specific downstream tasks.
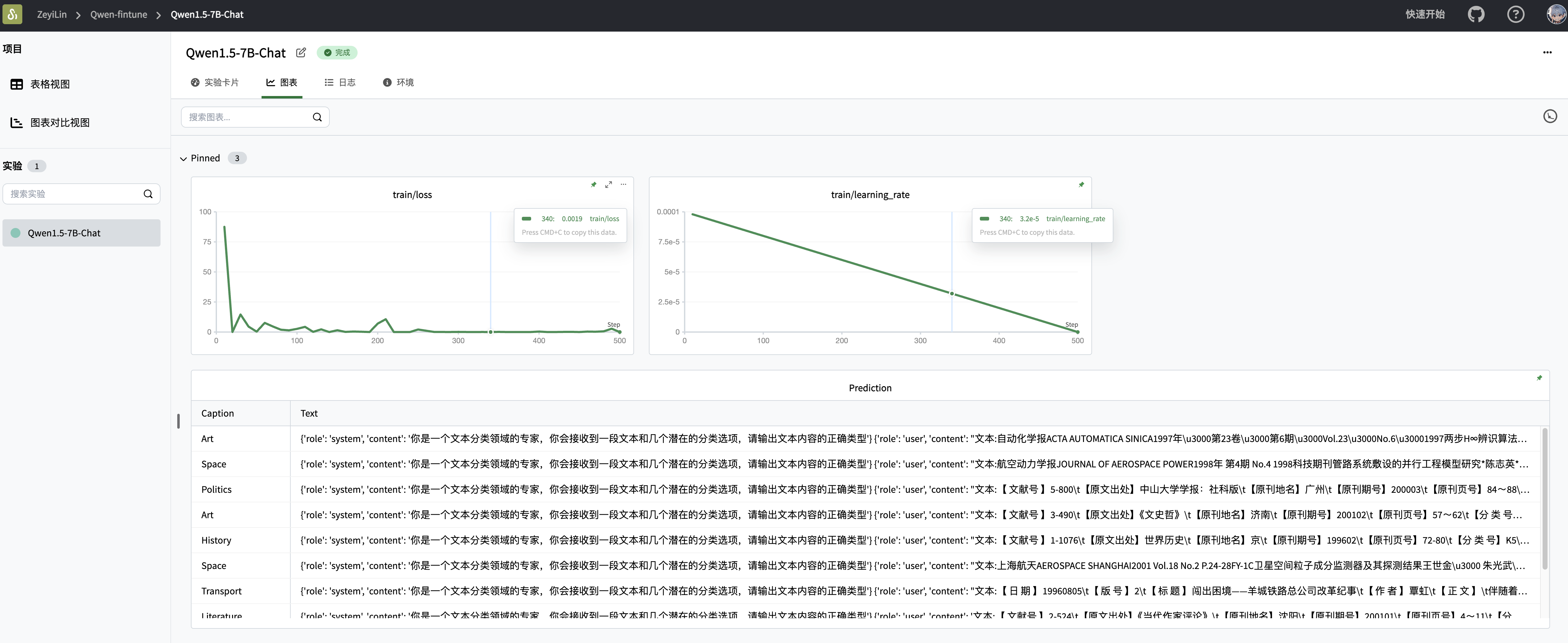
In this task, we will use the Qwen-1.5-7b model to fine-tune on the zh_cls_fudan-news dataset for instruction fine-tuning tasks, while using SwanLab for monitoring and visualization.
Environment Setup
This case study is based on Python>=3.10. Please ensure Python is installed on your computer.
Environment dependencies:
swanlab
modelscope
transformers
datasets
peft
accelerat
pandasOne-click installation command:
pip install swanlab modelscope transformers datasets peft pandasThis case study is tested with modelscope==1.14.0, transformers==4.41.2, datasets==2.18.0, peft==0.11.1, accelerate==0.30.1, swanlab==0.3.8
Dataset Introduction
This case study uses the zh_cls_fudan-news dataset, which is primarily used for training text classification models.
zh_cls_fudan-news consists of several thousand entries, each containing three columns: text, category, and output.
- text is the training corpus, containing text content from books or news articles.
- category is a list of potential types for the text.
- output is the single true type of the text.

Example dataset entry:
"""
[PROMPT]Text: The fourth national large enterprise football tournament's knockout stage concluded. Xinhua News Agency, Zhengzhou, May 3rd (Intern Tian Zhaoyun) The Shanghai Dalong Machinery Factory team defeated the Chengdu Metallurgical Experimental Factory team 5:4 in the knockout stage of the fourth Peony Cup national large enterprise football tournament held in Luoyang yesterday, advancing to the top four. The match between Shanghai and Chengdu was evenly matched, with no winner after 90 minutes. Finally, the two teams took turns in penalty kicks, and the Shanghai team won by a one-goal margin. In the other three knockout matches, Qinghai Shanchuan Machine Tool Foundry team defeated the host Luoyang Mining Machinery Factory team 3:0, Qingdao Foundry Machinery Factory team defeated Shijiazhuang First Printing and Dyeing Factory team 3:1, and Wuhan Meat Processing Factory team narrowly defeated Tianjin Second Metallurgical Machinery Factory team 1:0. In today's two matches to determine the 9th to 12th places, Baogang Seamless Steel Tube Factory team and Henan Pingdingshan Mining Bureau No.1 Mine team respectively defeated Henan Pingdingshan Nylon Cord Factory team and Jiangsu Yancheng Radio General Factory team. On the 4th, two semi-final matches will be held, with Qinghai Shanchuan Machine Tool Foundry team and Qingdao Foundry Machinery Factory team facing off against Wuhan Meat Processing Factory team and Shanghai Dalong Machinery Factory team respectively. The tournament will conclude on the 6th. (End)
Category: Sports, Politics
Output:[OUTPUT]Sports
"""Our training task is to fine-tune the large model so that it can predict the correct output based on the prompt consisting of text and category.
Preparations
Before starting the training, ensure that the environment is installed and that you have a GPU with at least 16GB of VRAM.
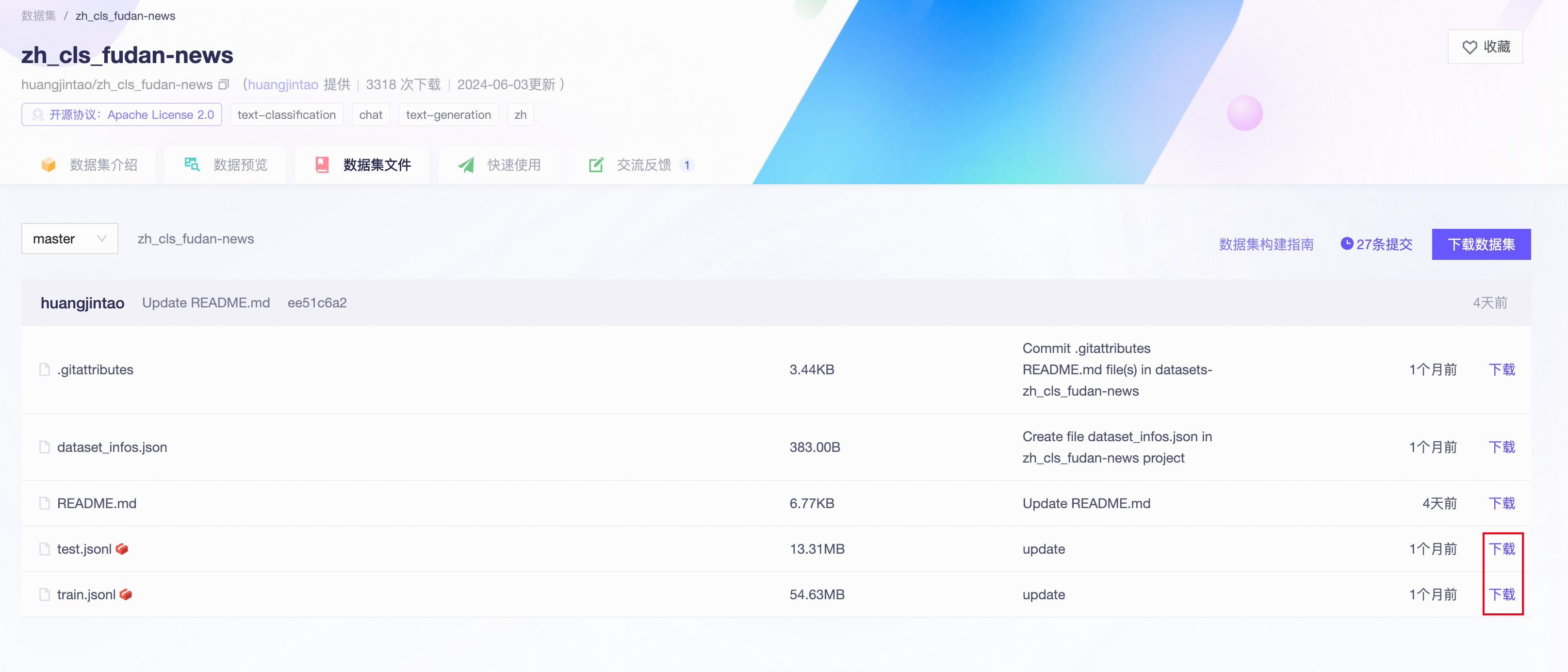
Next, download the dataset to your local directory. The download method is to go to zh_cls_fudan-news - ModelScope Community and download train.jsonl and test.jsonl to your local root directory:
Complete Code
Directory structure before starting training:
|--- train.py
|--- train.jsonl
|--- test.jsonltrain.py:
import json
import pandas as pd
import torch
from datasets import Dataset
from modelscope import snapshot_download, AutoTokenizer
from swanlab.integration.transformers import SwanLabCallback
from peft import LoraConfig, TaskType, get_peft_model
from transformers import AutoModelForCausalLM, TrainingArguments, Trainer, DataCollatorForSeq2Seq
import os
import swanlab
def dataset_jsonl_transfer(origin_path, new_path):
"""
Convert the original dataset to the new dataset format required for large model fine-tuning.
"""
messages = []
# Read the old JSONL file
with open(origin_path, "r") as file:
for line in file:
# Parse each line's json data
data = json.loads(line)
context = data["text"]
catagory = data["category"]
label = data["output"]
message = {
"instruction": "You are an expert in text classification. You will receive a piece of text and several potential classification options. Please output the correct type of the text content.",
"input": f"Text: {context}, Type Options: {catagory}",
"output": label,
}
messages.append(message)
# Save the reconstructed JSONL file
with open(new_path, "w", encoding="utf-8") as file:
for message in messages:
file.write(json.dumps(message, ensure_ascii=False) + "\n")
def process_func(example):
"""
Preprocess the dataset.
"""
MAX_LENGTH = 384
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer(
f"<|im_start|>system\nYou are an expert in text classification. You will receive a piece of text and several potential classification options. Please output the correct type of the text content.<|im_end|>\n<|im_start|>user\n{example['input']}<|im_end|>\n<|im_start|>assistant\n",
add_special_tokens=False,
)
response = tokenizer(f"{example['output']}", add_special_tokens=False)
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]
attention_mask = (
instruction["attention_mask"] + response["attention_mask"] + [1]
)
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]
if len(input_ids) > MAX_LENGTH: # Truncate if necessary
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {"input_ids": input_ids, "attention_mask": attention_mask, "labels": labels}
def predict(messages, model, tokenizer):
device = "cuda"
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
return response
# Download Qwen1.5-7B model from modelscope to local directory
model_dir = snapshot_download("qwen/Qwen1.5-7B-Chat", cache_dir="./", revision="master")
# Load model weights using Transformers
tokenizer = AutoTokenizer.from_pretrained("./qwen/Qwen1___5-7B-Chat/", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("./qwen/Qwen1___5-7B-Chat/", device_map="auto", torch_dtype=torch.bfloat16)
model.enable_input_require_grads() # Enable gradient checkpointing
# Load and process the training and test datasets
train_dataset_path = "train.jsonl"
test_dataset_path = "test.jsonl"
train_jsonl_new_path = "new_train.jsonl"
test_jsonl_new_path = "new_test.jsonl"
if not os.path.exists(train_jsonl_new_path):
dataset_jsonl_transfer(train_dataset_path, train_jsonl_new_path)
if not os.path.exists(test_jsonl_new_path):
dataset_jsonl_transfer(test_dataset_path, test_jsonl_new_path)
# Get the training dataset
train_df = pd.read_json(train_jsonl_new_path, lines=True)
train_ds = Dataset.from_pandas(train_df)
train_dataset = train_ds.map(process_func, remove_columns=train_ds.column_names)
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode=False, # Training mode
r=8, # Lora rank
lora_alpha=32, # Lora alpha, refer to Lora theory for details
lora_dropout=0.1, # Dropout ratio
)
model = get_peft_model(model, config)
args = TrainingArguments(
output_dir="./output/Qwen1.5",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
logging_steps=10,
num_train_epochs=2,
save_steps=100,
learning_rate=1e-4,
save_on_each_node=True,
gradient_checkpointing=True,
report_to="none",
)
swanlab_callback = SwanLabCallback(project="Qwen-fintune", experiment_name="Qwen1.5-7B-Chat")
trainer = Trainer(
model=model,
args=args,
train_dataset=train_dataset,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
callbacks=[swanlab_callback],
)
trainer.train()
# Test the model with the first 10 entries of the test dataset
test_df = pd.read_json(test_jsonl_new_path, lines=True)[:10]
test_text_list = []
for index, row in test_df.iterrows():
instruction = row['instruction']
input_value = row['input']
messages = [
{"role": "system", "content": f"{instruction}"},
{"role": "user", "content": f"{input_value}"}
]
response = predict(messages, model, tokenizer)
messages.append({"role": "assistant", "content": f"{response}"})
result_text = f"{messages[0]}\n\n{messages[1]}\n\n{messages[2]}"
test_text_list.append(swanlab.Text(result_text, caption=response))
swanlab.log({"Prediction": test_text_list})
swanlab.finish()Demonstration of Results