BERT Text Classification
INFO
Introduction to Natural Language Processing, Text Classification, and Machine Learning
Online Demo | Zhihu | Meituan Waimai Review Classification
Overview
BERT (Bidirectional Encoder Representations from Transformers) is a pre-trained natural language processing model proposed by Google, widely used in various natural language processing tasks. BERT captures contextual relationships between words by pre-training on large-scale corpora, achieving excellent results in many tasks.
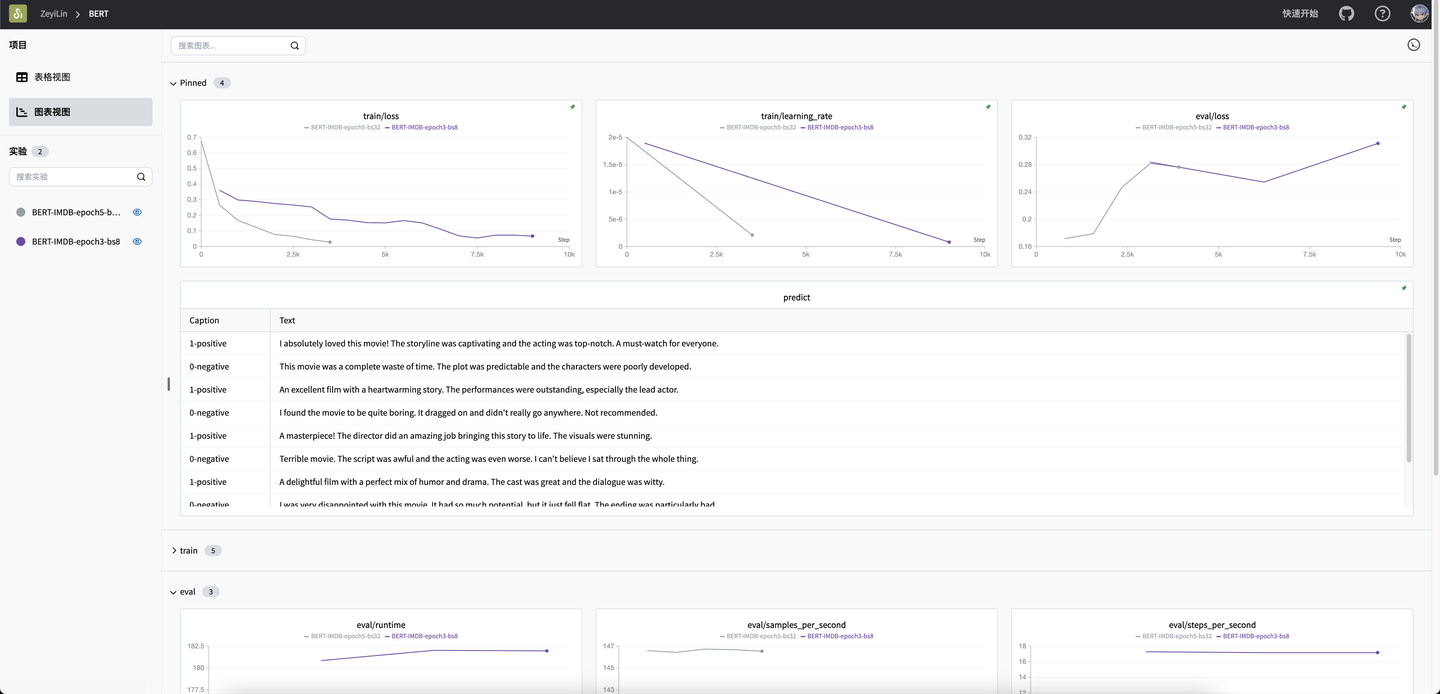
In this task, we will use the BERT model to classify IMDB movie reviews into "positive" or "negative" sentiments.
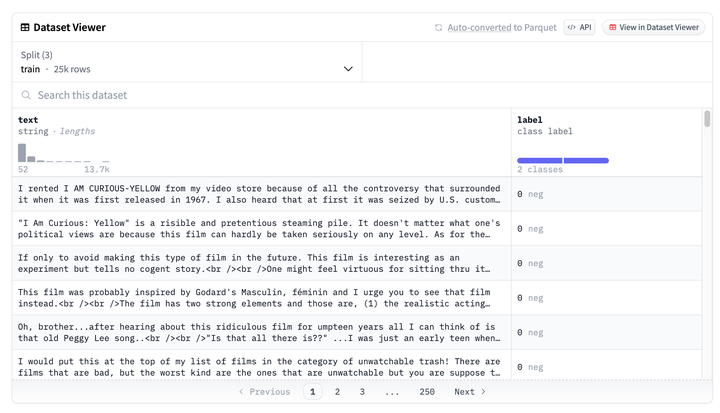
The IMDB movie review dataset contains 50,000 movie reviews, divided into 25,000 training and 25,000 test data, each with 50% positive and 50% negative reviews. We will use the pre-trained BERT model to fine-tune these reviews for sentiment classification.
Environment Setup
This example is based on Python>=3.8. Please ensure Python is installed on your computer. Environment dependencies:
transformers
datasets
swanlabQuick installation command:
pip install transformers datasets swanlabThe code in this article is tested with transformers==4.41.0, datasets==2.19.1, swanlab==0.3.3
Complete Code
"""
Fine-tune a pre-trained BERT model on the IMDB dataset and use the SwanLabCallback callback function to upload the results to SwanLab.
The IMDB dataset labels 1 as positive and 0 as negative.
"""
import torch
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from swanlab.integration.transformers import SwanLabCallback
import swanlab
def predict(text, model, tokenizer, CLASS_NAME):
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
predicted_class = torch.argmax(logits).item()
print(f"Input Text: {text}")
print(f"Predicted class: {int(predicted_class)} {CLASS_NAME[int(predicted_class)]}")
return int(predicted_class)
# Load the IMDB dataset
dataset = load_dataset('imdb')
# Load the pre-trained BERT tokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
# Define the tokenize function
def tokenize(batch):
return tokenizer(batch['text'], padding=True, truncation=True)
# Tokenize the dataset
tokenized_datasets = dataset.map(tokenize, batched=True)
# Set the model input format
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format('torch', columns=['input_ids', 'attention_mask', 'labels'])
# Load the pre-trained BERT model
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# Set training arguments
training_args = TrainingArguments(
output_dir='./results',
eval_strategy='epoch',
save_strategy='epoch',
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
logging_first_step=100,
# Total number of training epochs
num_train_epochs=3,
weight_decay=0.01,
report_to="none",
# Single GPU training
)
CLASS_NAME = {0: "negative", 1: "positive"}
# Set the swanlab callback function
swanlab_callback = SwanLabCallback(project='BERT',
experiment_name='BERT-IMDB',
config={'dataset': 'IMDB', "CLASS_NAME": CLASS_NAME})
# Define the Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets['train'],
eval_dataset=tokenized_datasets['test'],
callbacks=[swanlab_callback],
)
# Train the model
trainer.train()
# Save the model
model.save_pretrained('./sentiment_model')
tokenizer.save_pretrained('./sentiment_model')
# Test the model
test_reviews = [
"I absolutely loved this movie! The storyline was captivating and the acting was top-notch. A must-watch for everyone.",
"This movie was a complete waste of time. The plot was predictable and the characters were poorly developed.",
"An excellent film with a heartwarming story. The performances were outstanding, especially the lead actor.",
"I found the movie to be quite boring. It dragged on and didn't really go anywhere. Not recommended.",
"A masterpiece! The director did an amazing job bringing this story to life. The visuals were stunning.",
"Terrible movie. The script was awful and the acting was even worse. I can't believe I sat through the whole thing.",
"A delightful film with a perfect mix of humor and drama. The cast was great and the dialogue was witty.",
"I was very disappointed with this movie. It had so much potential, but it just fell flat. The ending was particularly bad.",
"One of the best movies I've seen this year. The story was original and the performances were incredibly moving.",
"I didn't enjoy this movie at all. It was confusing and the pacing was off. Definitely not worth watching."
]
model.to('cpu')
text_list = []
for review in test_reviews:
label = predict(review, model, tokenizer, CLASS_NAME)
text_list.append(swanlab.Text(review, caption=f"{label}-{CLASS_NAME[label]}"))
if text_list:
swanlab.log({"predict": text_list})
swanlab.finish()Demonstration Effect