LSTM股票预测
INFO
时间序列、量化交易、时序模型

概述
LSTM(Long Short-Term Memory),即长短时记忆网络,是一种特殊的RNN(递归神经网络),它改进了传统RNN在处理长序列数据时存在的梯度消失和梯度爆炸问题。LSTM由Hochreiter和Schmidhuber于1997年提出,已成为处理时间序列数据的经典模型之一。
股票预测任务指的是根据一支股票的过去一段时间的数据,通过AI模型预测现在以及未来的股价变化,也是一种实用的时间序列任务。这里我们使用2016~2021年的Google股价数据数据集来进行训练和推理。
环境安装
本案例基于Python>=3.8,请在您的计算机上安装好Python。 环境依赖:
txt
pandas
torch
matplotlib
swanlab
scikit-learn快速安装命令:
bash
pip install pandas torch matplotlib swanlab scikit-learn本代码测试于torch==2.3.0、pandas==2.0.3、matplotlib==3.8.2、swanlab==0.3.8、scikit-learn==1.3.2
完整代码
请先在Kaggle下载Google Stock Prediction数据集到根目录下。
python
import os
import swanlab
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from copy import deepcopy as dc
import numpy as np
import pandas as pd
from torch.utils.data import Dataset
from sklearn.preprocessing import MinMaxScaler
class LSTMModel(nn.Module):
"""
定义模型类
"""
def __init__(self, input_size=1, hidden_size1=50, hidden_size2=64, fc1_size=32, fc2_size=16, output_size=1):
super(LSTMModel, self).__init__()
self.lstm1 = nn.LSTM(input_size, hidden_size1, batch_first=True)
self.lstm2 = nn.LSTM(hidden_size1, hidden_size2, batch_first=True)
self.fc1 = nn.Linear(hidden_size2, fc1_size)
self.fc2 = nn.Linear(fc1_size, fc2_size)
self.fc3 = nn.Linear(fc2_size, output_size)
def forward(self, x):
x, _ = self.lstm1(x)
x, _ = self.lstm2(x)
x = self.fc1(x[:, -1, :])
x = self.fc2(x)
x = self.fc3(x)
return x
class TimeSeriesDataset(Dataset):
"""
定义数据集类
"""
def __init__(self, X, y):
self.X = X
self.y = y
def __len__(self):
return len(self.X)
def __getitem__(self, i):
return self.X[i], self.y[i]
def prepare_dataframe_for_lstm(df, n_steps):
"""
处理数据集,使其适用于LSTM模型
"""
df = dc(df)
df['date'] = pd.to_datetime(df['date'])
df.set_index('date', inplace=True)
for i in range(1, n_steps+1):
df[f'close(t-{i})'] = df['close'].shift(i)
df.dropna(inplace=True)
return df
def get_dataset(file_path, lookback, split_ratio=0.9):
"""
归一化数据、划分训练集和测试集
"""
data = pd.read_csv(file_path)
data = data[['date','close']]
shifted_df_as_np = prepare_dataframe_for_lstm(data, lookback)
scaler = MinMaxScaler(feature_range=(-1,1))
shifted_df_as_np = scaler.fit_transform(shifted_df_as_np)
X = shifted_df_as_np[:, 1:]
y = shifted_df_as_np[:, 0]
X = dc(np.flip(X,axis=1))
# 划分训练集和测试集
split_index = int(len(X) * split_ratio)
X_train = X[:split_index]
X_test = X[split_index:]
y_train = y[:split_index]
y_test = y[split_index:]
X_train = X_train.reshape((-1, lookback, 1))
X_test = X_test.reshape((-1, lookback, 1))
y_train = y_train.reshape((-1, 1))
y_test = y_test.reshape((-1, 1))
# 转换为Tensor
X_train = torch.tensor(X_train).float()
y_train = torch.tensor(y_train).float()
X_test = torch.tensor(X_test).float()
y_test = torch.tensor(y_test).float()
return scaler, X_train, X_test, y_train, y_test
def train(model, train_loader, optimizer, criterion):
model.train()
running_loss = 0
# 训练
for i, batch in enumerate(train_loader):
x_batch, y_batch = batch[0].to(device), batch[1].to(device)
y_pred = model(x_batch)
loss = criterion(y_pred, y_batch)
running_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss_epoch = running_loss / len(train_loader)
print(f'Epoch: {epoch}, Batch: {i}, Avg. Loss: {avg_loss_epoch}')
swanlab.log({"train/loss": running_loss}, step=epoch)
running_loss = 0
def validate(model, test_loader, criterion, epoch):
model.eval()
val_loss = 0
with torch.no_grad():
for _, batch in enumerate(test_loader):
x_batch, y_batch = batch[0].to(device), batch[1].to(device)
y_pred = model(x_batch)
loss = criterion(y_pred, y_batch)
val_loss += loss.item()
avg_val_loss = val_loss / len(test_loader)
print(f'Epoch: {epoch}, Validation Loss: {avg_val_loss}')
swanlab.log({"val/loss": avg_val_loss}, step=epoch)
def inverse_transform_and_extract(scaler, data, lookback):
dummies = np.zeros((data.shape[0], lookback + 1))
dummies[:, 0] = data.flatten()
return dc(scaler.inverse_transform(dummies)[:, 0])
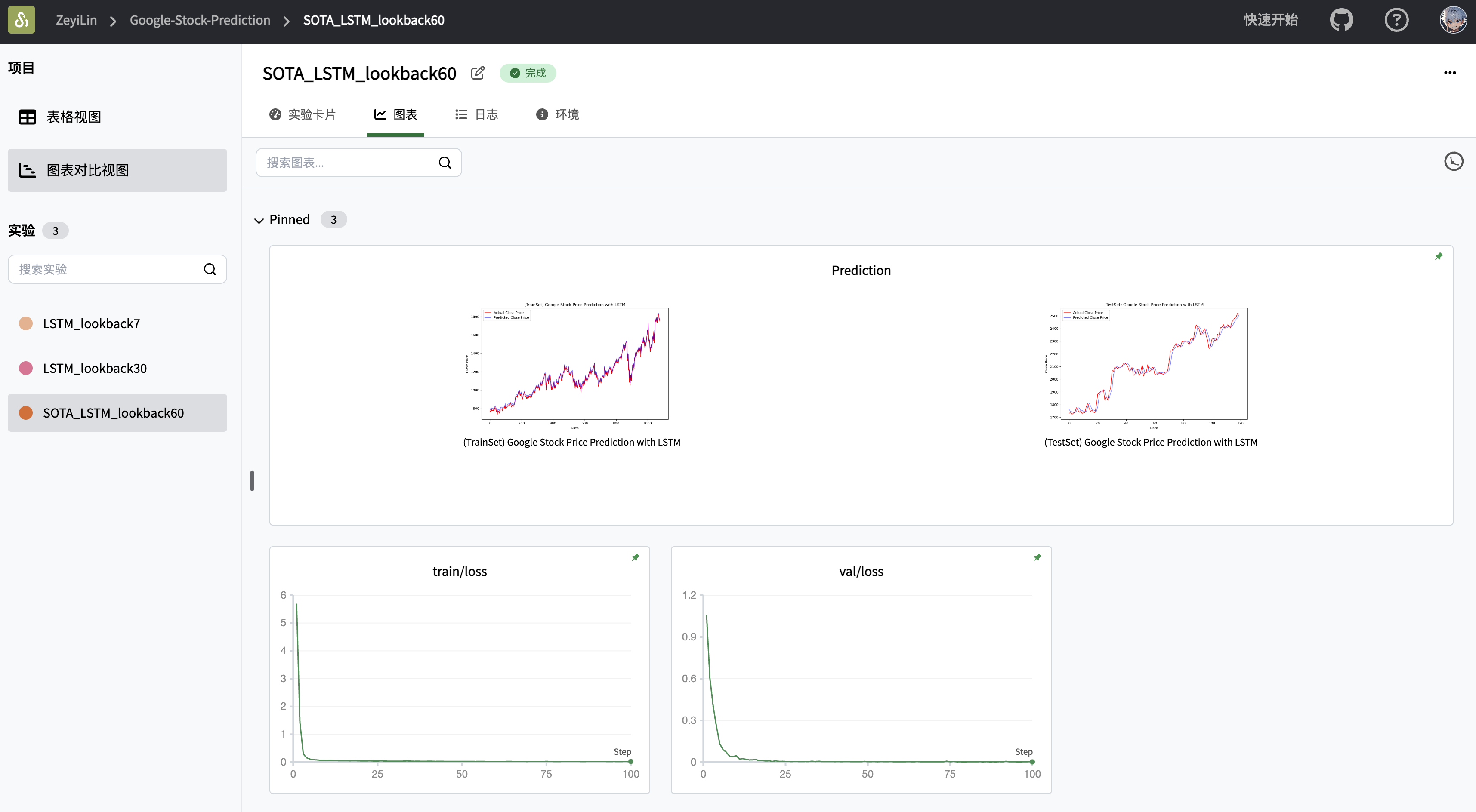
def plot_predictions(actual, predicted, title, xlabel='Date', ylabel='Close Price'):
"""
绘制最后的股价预测与真实值的对比图
"""
plt.figure(figsize=(10, 6))
plt.plot(actual, color='red', label='Actual Close Price')
plt.plot(predicted, color='blue', label='Predicted Close Price', alpha=0.5)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.title(title)
plt.legend()
return swanlab.Image(plt, caption=title)
def visualize_predictions(train_predictions, val_predictions, scaler, y_train, y_test, lookback):
train_predictions = inverse_transform_and_extract(scaler, train_predictions, lookback)
val_predictions = inverse_transform_and_extract(scaler, val_predictions, lookback)
new_y_train = inverse_transform_and_extract(scaler, y_train, lookback)
new_y_test = inverse_transform_and_extract(scaler, y_test, lookback)
plt_image = []
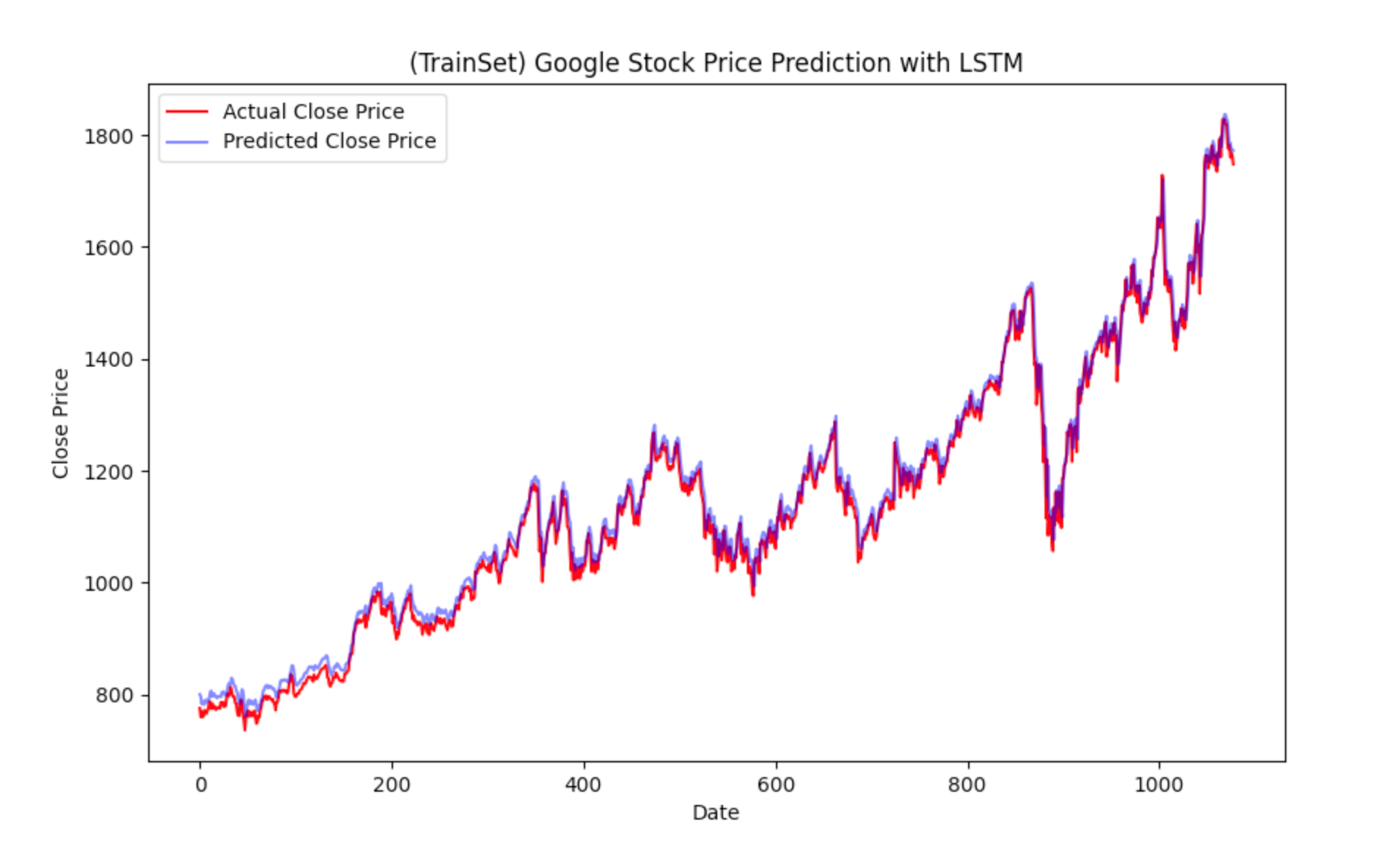
plt_image.append(plot_predictions(new_y_train, train_predictions, '(TrainSet) Google Stock Price Prediction with LSTM'))
plt_image.append(plot_predictions(new_y_test, val_predictions, '(TestSet) Google Stock Price Prediction with LSTM'))
swanlab.log({"Prediction": plt_image})
if __name__ == '__main__':
# ------------------- 初始化一个SwanLab实验 -------------------
swanlab.init(
project='Google-Stock-Prediction',
experiment_name="LSTM",
description="根据前7天的数据预测下一日股价",
config={
"learning_rate": 1e-3,
"epochs": 100,
"batch_size": 32,
"lookback": 7,
"spilt_ratio": 0.9,
"save_path": "./checkpoint",
"optimizer": "Adam",
"device": 'cuda' if torch.cuda.is_available() else 'cpu',
},
)
config = swanlab.config
device = torch.device(config.device)
# ------------------- 定义数据集 -------------------
scaler, X_train, X_test, y_train, y_test = get_dataset(file_path='./GOOG.csv',
lookback=config.lookback,
split_ratio=config.spilt_ratio,)
train_dataset = TimeSeriesDataset(X_train, y_train)
test_dataset = TimeSeriesDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=config.batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=config.batch_size, shuffle=False)
# ------------------- 定义模型、超参数 -------------------
model = LSTMModel(input_size=1, output_size=1)
model = model.to(device)
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate)
criterion = nn.MSELoss()
# ------------------- 训练与验证 -------------------
for epoch in range(1, config.epochs+1):
train(model, train_loader, optimizer, criterion)
validate(model, test_loader, criterion, epoch)
# ------------------- 使用最佳模型推理,与生成可视化结果 -------------------
with torch.no_grad():
model.eval()
train_predictions = model(X_train.to(device)).to('cpu').numpy()
val_predictions = model(X_test.to(device)).to('cpu').numpy()
visualize_predictions(train_predictions, val_predictions, scaler, y_train, y_test, config.lookback)
# ------------------- 保存模型 -------------------
model_save_path = os.path.join(config.save_path, 'lstm.pth')
if not os.path.exists(config.save_path):
os.makedirs(config.save_path)
torch.save(model.state_dict(), model_save_path)演示效果