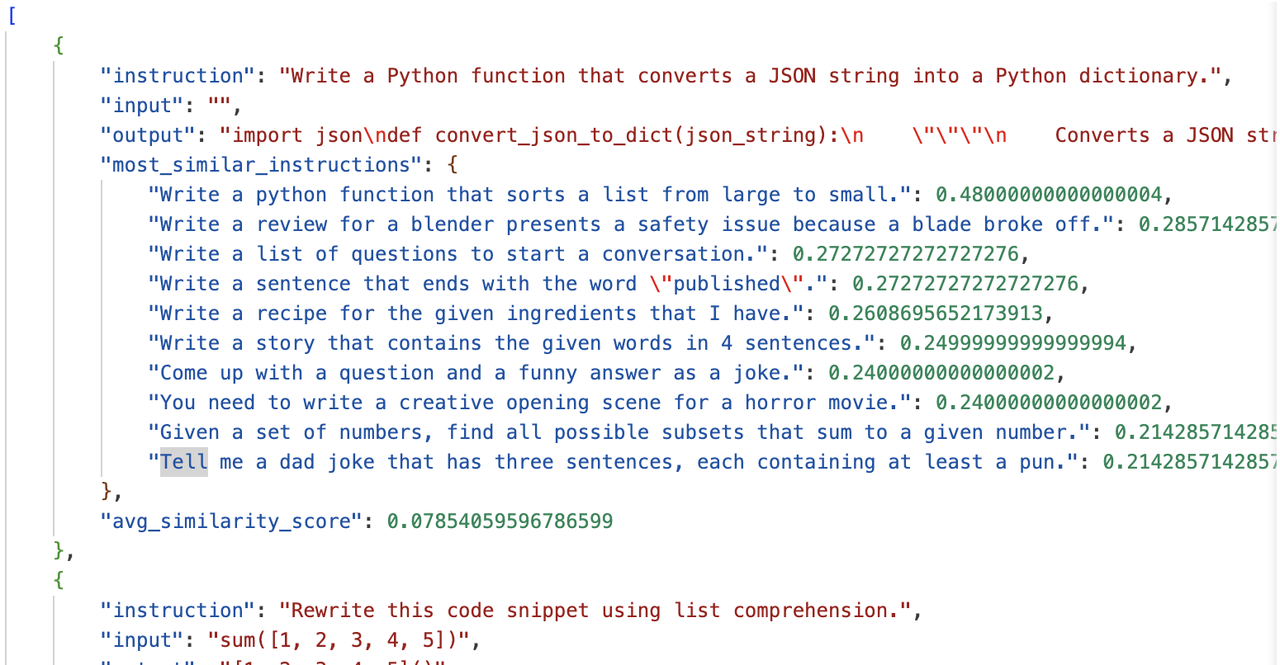
6.2 微调阶段的合成数据
微调阶段合成数据的重要性
理解微调阶段为什么需要合成数据,其实就是去了解为什么大模型需要微调、微调阶段需要什么样的数据。
大模型经过预训练后,已经具备了基础的语言理解和生成能力,但这些能力更多是通用层面的。在实际应用中,不同场景对模型的要求千差万别,比如企业需要模型能精准处理法律合同审查,金融机构希望模型能高效分析市场动态,医疗机构则期待模型能辅助疾病诊断。这时候,微调就成了让大模型 “术业有专攻” 的关键步骤,通过在特定任务或领域的数据上进一步训练,让模型适配具体需求,提升在目标场景下的性能。
而微调的效果,很大程度上取决于数据的质量和适配性。微调阶段对数据有着明确且严苛的要求。首先,数据质量必须足够高,需要准确、规范、无歧义,避免错误信息误导模型学习。其次,在格式上,微调数据基本以问答格式为主,因为这种格式能直接对应模型的交互场景,让模型学习到 “输入问题→输出答案” 的映射逻辑。对于更复杂的场景,多轮对话格式的数据也必不可少,它能帮助模型理解上下文关联,提升连续交互能力。
更重要的是,微调数据往往需要专注于某一特定领域,比如法律、金融、医学等。以法律领域为例,可能需要大量 “如何认定合同无效”“离婚财产分割的法律依据是什么” 这类专有问答数据;金融领域则需要 “股票期权的风险如何评估”“企业债券发行的流程是什么” 等专业内容。这些领域专有问答数据,是让模型掌握专业知识、形成领域思维的核心素材。
然而,现实情况是网上这类高质量的领域专有问答数据非常稀少。早期获得这类数据更多的依赖于人工标注,但是面对日益扩大的模型规模和任务需求,人工标注不仅耗时耗力,而且人工标注多多少少都会有偏向性从而无法保证数据的丰富度,因此最初大家都在往预训练阶段发力。
随着Stanford Alpaca: An Instruction-following LLaMA Model论文发布,由预训练GPT-3通过设定的提示词合成指令数据,然后清洗、去重等,最终用合成的指令数据对Llama模型进行微调,得到的Llama-Instruct模型在各个测试数据上都取得了不错的效果。
下面我们详细解释论文中数据是如何生成的。
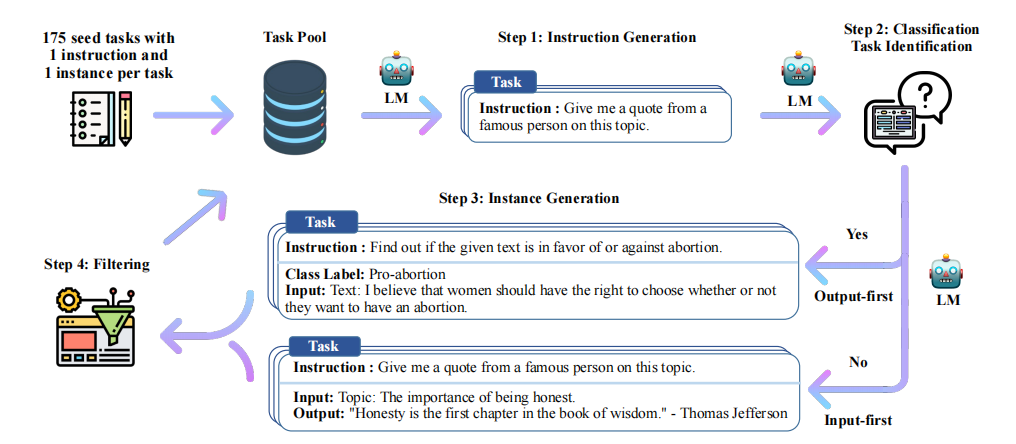
上图是Alpaca论文中的数据集合成完整流程[5],完整的数据合成流程分为四步,分别是1)生成任务指令,2)判断指令是否属于分类任务,3)采用输入优先或输出优先的方式进行实例生成,4)过滤低质量数据
- 生成任务指令:首先需要人工编写多个种子任务,这些种子任务其实就是正常的问答,不过要添加任务主题,还有任务类型,比如下面的例子:
{
"id": "seed_task_0",
"name": "breakfast_suggestion",
"instruction": "Is there anything I can eat for a breakfast that doesn't include eggs, yet includes protein, and has roughly 700-1000 calories?",
"instances": [
{
"input": "",
"output": "Yes, you can have 1 oatmeal banana protein shake and 4 strips of bacon. The oatmeal banana protein shake may contain 1/2 cup oatmeal, 60 grams whey protein powder, 1/2 medium banana, 1tbsp flaxseed oil and 1/2 cup watter, totalling about 550 calories. The 4 strips of bacon contains about 200 calories."
}
],
"is_classification": false
}name是主题,is_classification判断任务类型是否属于分类任务。论文中给出的种子数量仅有175条,这些种子任务目的是为了后续模型生成的时候有参照的模板,类似于few-shot的例子部分。由于任务种类较少,因此第一步是让大模型模仿并扩展任务指令,从任务池中采样8个任务,其中6个是种子任务的,2个是新生成的(任务池随着每次迭代更新数据,因此后续会有新生成的指令任务),

作为few-shot的例子部分,从task9开始让大模型生成新的task和instruction作为新的指令[5],然后生成、数据过滤、去重清洗、加入到任务池中反复执行,从而扩展了大量的任务指令。
判断指令是否属于分类任务:分类任务要先生成output,也就是标签,再生成input;不是分类任务的话先生成input再生成output(分类任务先生成标签是为了确保input不会偏离标签,因为本身由于instruction 的不同,模型生成的input有偏向,先生成了output确保生成的input不会偏离output标签;非分类任务由于output是跟着input走的,而不是像label一样是固定的,因此先生成input然后输出output)。这里需要注意的是,input和output都是GPT-3生成的,因为你的目标是生成数据集,而不是和模型问答。
采用输入优先或输出优先的方式进行实例生成:第二步判断了是否属于分类任务,当明确了任务类型后,就能使用大模型生成对应任务类型的数据,比如我们看个例子:
text# 分类任务 Given the classification task definition and the class labels, generate an input that corresponds to each of the class labels. If the task doesn’t require input, just generate the correct class label. Task: Classify the sentiment of the sentence into positive, negative, or mixed. Output(Class label): mixed Input(Sentence): I enjoy the flavor of the restaurant but their service is too slow. Output(Class label): Positive Input(Sentence): I had a great day today. The weather was beautiful and I spent time with friends. Output(Class label): Negative Input(Sentence): I was really disappointed by the latest superhero movie. I would not recommend it. # 非分类任务 Instruction: Given an address and city, come up with the zip code. Input: Address: 123 Main Street, City: San Francisco Output: 94105过滤低质量数据:这一步通过过滤、去重等操作,将新的数据投放到数据池作为后续的数据生成数据池。过滤用的是指令过滤,方法是计算新生成的指令与现有指令之间的相似性(如ROUGE-L相似度)。如果新指令与现有指令的相似度超过某个阈值(如0.7),则认为该指令是重复的,将其过滤掉;关键词过滤检查指令中是否包含某些特定关键词(如“image”、“picture”、“graph”等),这些关键词通常表示任务超出了语言模型的处理范围;重复性检查生成的实例是否与现有实例完全相同,或者输入相同但输出不同;质量检查通过启发式规则(如指令长度、输入长度、输出长度等)来识别无效或低质量的生成内容。例如,指令过长或过短,输出是输入的重复等。
微调数据举例
但是微调虽然要求的数据规模不大, 但是对质量的要求很高。我们在前文已经分析了生成微调数据的完整流程,而生成的数据集就是我们在入门大模型微调时经常使用的数据集Alpaca,总计52k条数据,所有的数据都是由GPT-3预训练模型生成,如果想复现生成数据集的代码,查看官方给的代码即可。
一般的,指令微调的数据集包含三个部分:指令、输入、输出:
instruction:指令
input:输入
output:输出我们看下经典的Alpaca数据集格式:
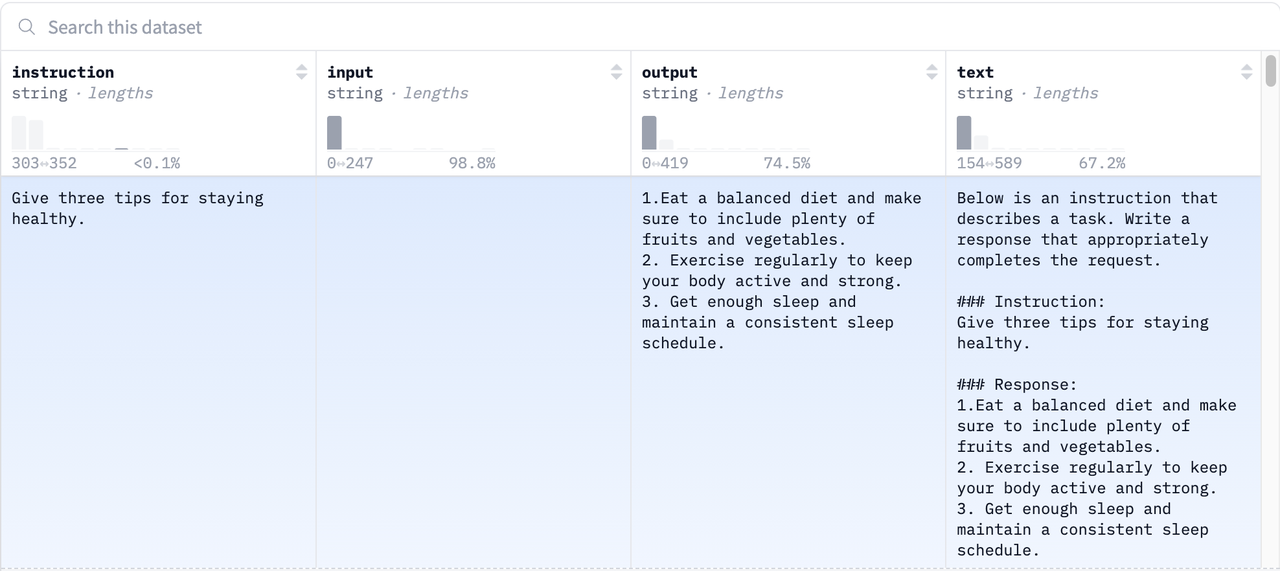
其中每一部分含义如下:
instruction:描述模型应执行的任务。52K 条指令中的每一条都是唯一的。input:可选的上下文或任务输入。例如,当指令为“总结以下文章”时,输入就是文章本身。大约 40% 的示例包含输入。output:由text-davinci-003(GPT-3)模型来生成的指令的答案。text:instruction,input并使用作者用于微调其模型的提示模板output进行格式化。
合成微调数据代码实践
关于微调数据的合成,提供了完整的合成instruct数据的代码,完整的生成流程我们在前文已经讲过,我们再简单总结下:
- 生成任务指令
- 判断指令是否属于分类任务
- 采用输入优先或输出优先的方式进行实例生成
- 过滤低质量数据
完整的四步在生成代码里,具体看generate_instruction_following_data部分,基本按照生成流程的顺序实现,openai对应的API接口处理代码在工具里,代码原理也很简单,我们就不再赘述。
我们提供了简易的生成代码,链接在这,代码构成如下:
instruct_data_gengeration/
├── generate_instruction.py # 数据生成
├── utils.py # openai接口设计以及其他工具等
├── prompt.txt # 生成instruction的提示词
├── seed_tasks.jsonl # 种子任务
└── data/ # 生成的数据保存地址不过因为我们仍然用vllm框架来实现高效生成数据的方法,而官方的代码时间有点久,很多包进行了更新,不一定适配原始的代码,因此我们把需要改动的地方着重强调下。
因为我们希望使用本地保存的模型,重点是model_name_or_path换成我们的本地的模型地址,无论是本地模型Qwen还是默认的GPT系列的text-davinci-003,其实都适配OpenAI的JSON输入接口,因此该函数的整体逻辑不需要进行修改,但是由于openai这个包有更新,细节部分需要修改。
- 首先是openai的Completion换成了
openai.OpenAI.completions,这里需要注意。 - 其次是我们没有走openai的调用API的方法,走的是本地服务器,因此需要把url改成本地的端口地址,一般情况下,默认是8000,代码如下:
client = openai.OpenAI(
# defaults to os.environ.get("OPENAI_API_KEY")
api_key="EMPTY",
base_url="http://127.0.0.1:8000/v1",
)因此第一步的completions需要改成如下形式:
completion_batch = client.completions.create(prompt=prompt_batch, **shared_kwargs)- 最后openai删掉了openai_object,不过这一步基本只是规定输出格式,因此直接删掉所有关联的代码即可
具体的修改好的代码可以参考👉ours
我们先开启vllm,模型采用本地保存的模型地址:
vllm serve /home/lixinyu/weights/Qwen2.5-3B然后我们运行下面的代码,就可以合成微调数据了:
python -m generate_instruction generate_instruction_following_data \
--output_dir ./data \
--num_instructions_to_generate 10 \
--model_name /home/lixinyu/weights/Qwen2.5-3B \
--request_batch_size 2合成的数据如下: