6.3 推理合成数据
推理合成数据的重要性
推理数据,其实可以叫做具备“思考能力”的数据。“思考能力”其实是近一年左右逐渐发展的概念,主要应用于后训练阶段,希望模型在具备基本的问答能力的同时,多加一个思考模块,这个思想是从DeepSeek-R1爆火开始。
具备“思考能力”数据集,顾名思义,在原始问答对基础上,增加了思考模块的数据。在前文我们提到随着模型规模的扩大,互联网数据几乎被全部用于预训练,即使有合成数据的帮助,在2024年也到了瓶颈,而2025年年初,DeepSeek凭借R1模型爆火了一把,R1凭借其独特的思考模块和能力,还有独特的训练方式,稳居当时开源模型的榜首,而也正是因为其思考能力,让合成数据再一次突破了数据规模的瓶颈,在原始问答对基础上只是增加think部分,模型性能就有很大的提升,尤其表现在数学推理等任务当中。
“思考型”数据基本只能由合成数据构成,因为互联网基本不会存在这种数据,而人工标注也基本不可能,简单的问答对或许还有实现的希望,增加或错或对的思考过程,基本只能由大模型本身的生成能力才能实现。
在DeepSeek-R1发布的技术报告中,R1的基线模型是DeepSeek-V3,经过多步合成数据,通过微调的方式对V3进行微调,从而获得R1,而合成的数据大部分是V3通过GRPO强化学习方式生成的推理数据,外加少部分非推理数据,使得V3具备思考能力,具体的流程可参考下图[6]:
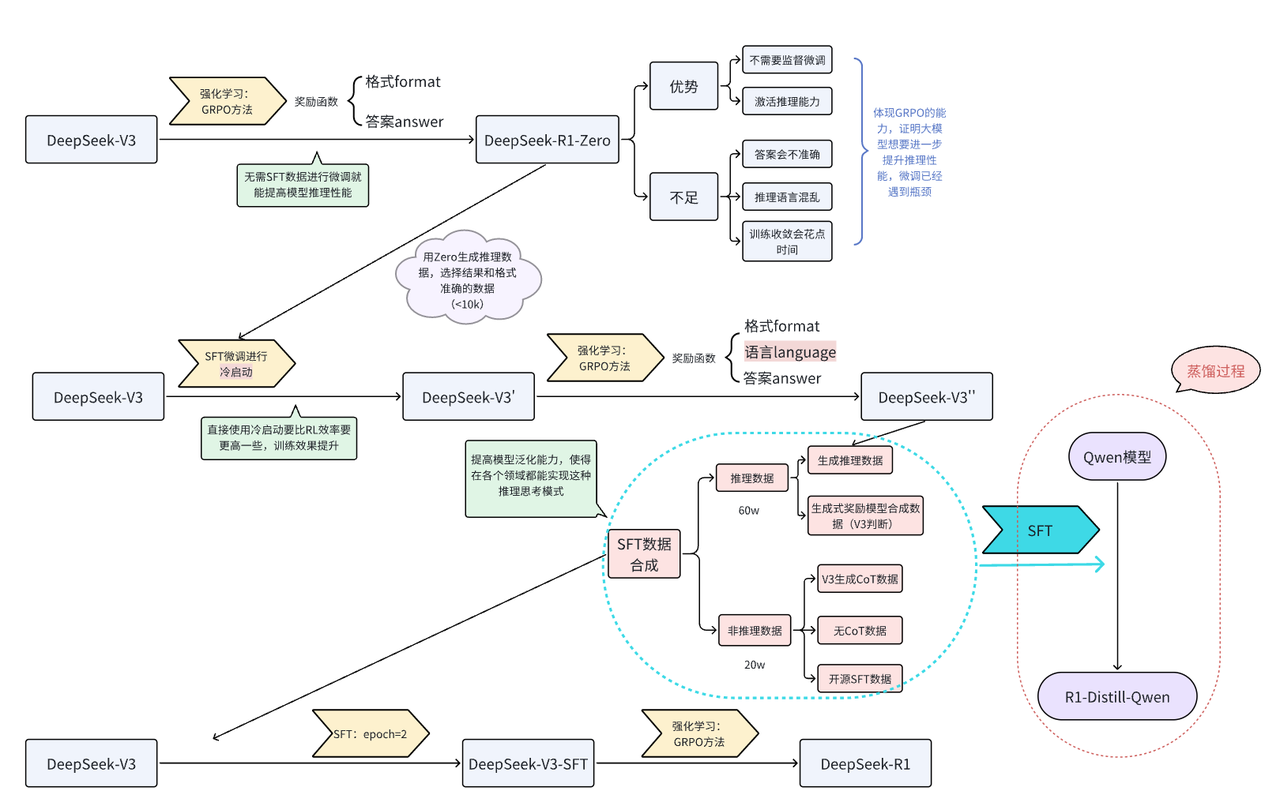
其中我们所说的“思考型”数据,在R1的整体生成流程中,GRPO强化学习阶段,模型生成而来,然后用生成的数据对V3进行微调,最终得到的R1。
在GRPO阶段,从V3到R1-Zero的过程中,DeepSeek团队对system提示词加以改造:

上图是GRPO过程中提示词的内容[7],可以看到,虽然提示中明确要求在 <think> 标签内写出推理过程,但并未对推理过程的具体形式做任何规定。
在强化学习阶段,他们基于规则设计了两类奖励:
- 准确度奖励(Accuracy rewards):通过测试答案的正确性来给予奖励。
- 格式奖励(Format rewards):对使用
<thinking>和<answer>标签的行为给予奖励。
对于那些导致答案正确的所有决策——无论是特定的 token 序列还是推理步骤——都会在训练中获得使其更有可能被采纳的权重调整。
而对于那些导致答案错误的所有决策,则会在训练中获得使其更不可能被采纳的权重调整。
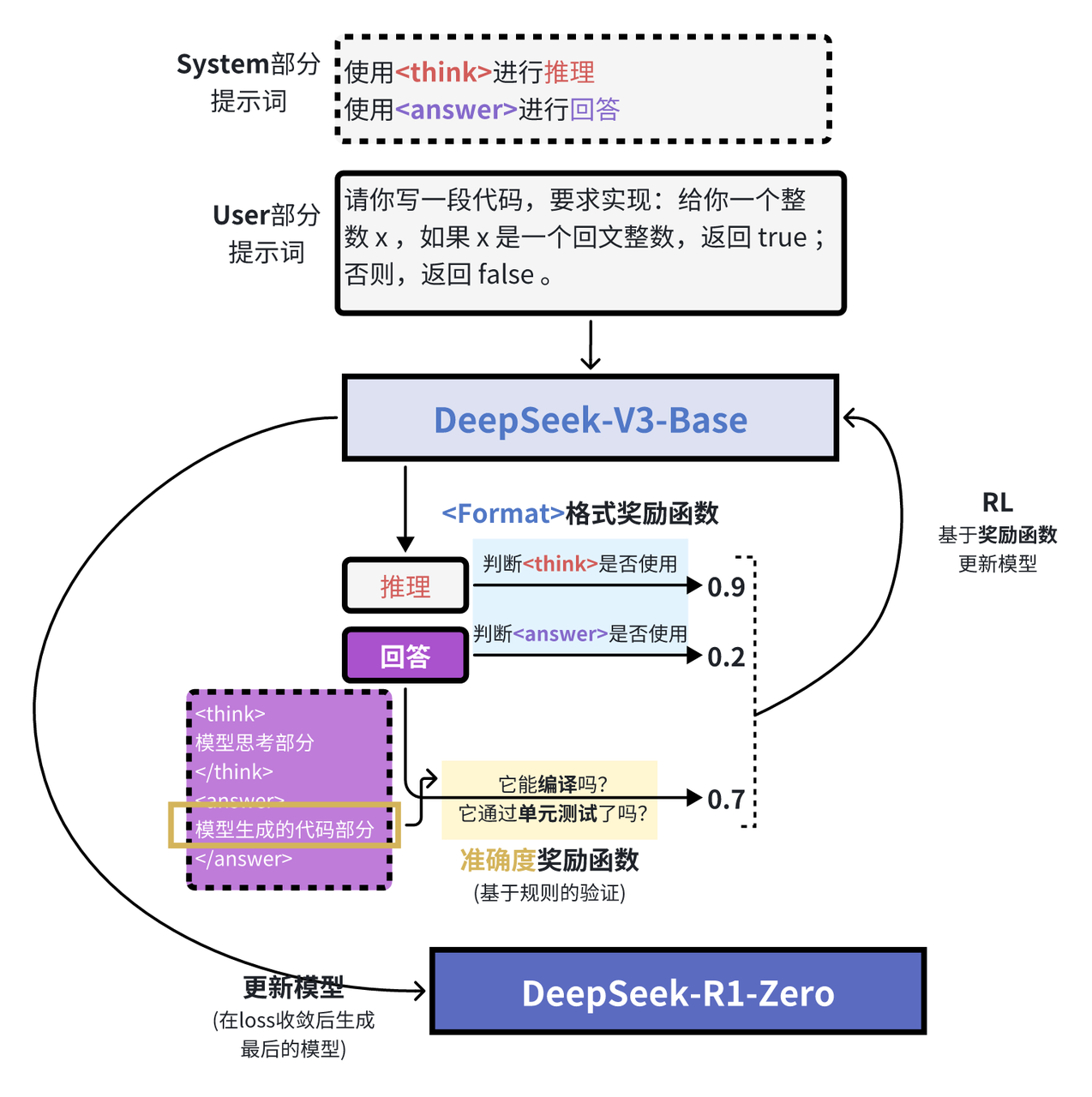
有意思的是,该提示并没有给出 <think> 过程应当如何呈现的示例,只是要求在 <think> 标签内进行思考,无需更多细节。通过向模型提供与思维链(Chain-of-Thought)相关的间接奖励,模型逐渐自主学会:当推理过程更长、更复杂时,答案更可能是正确的。
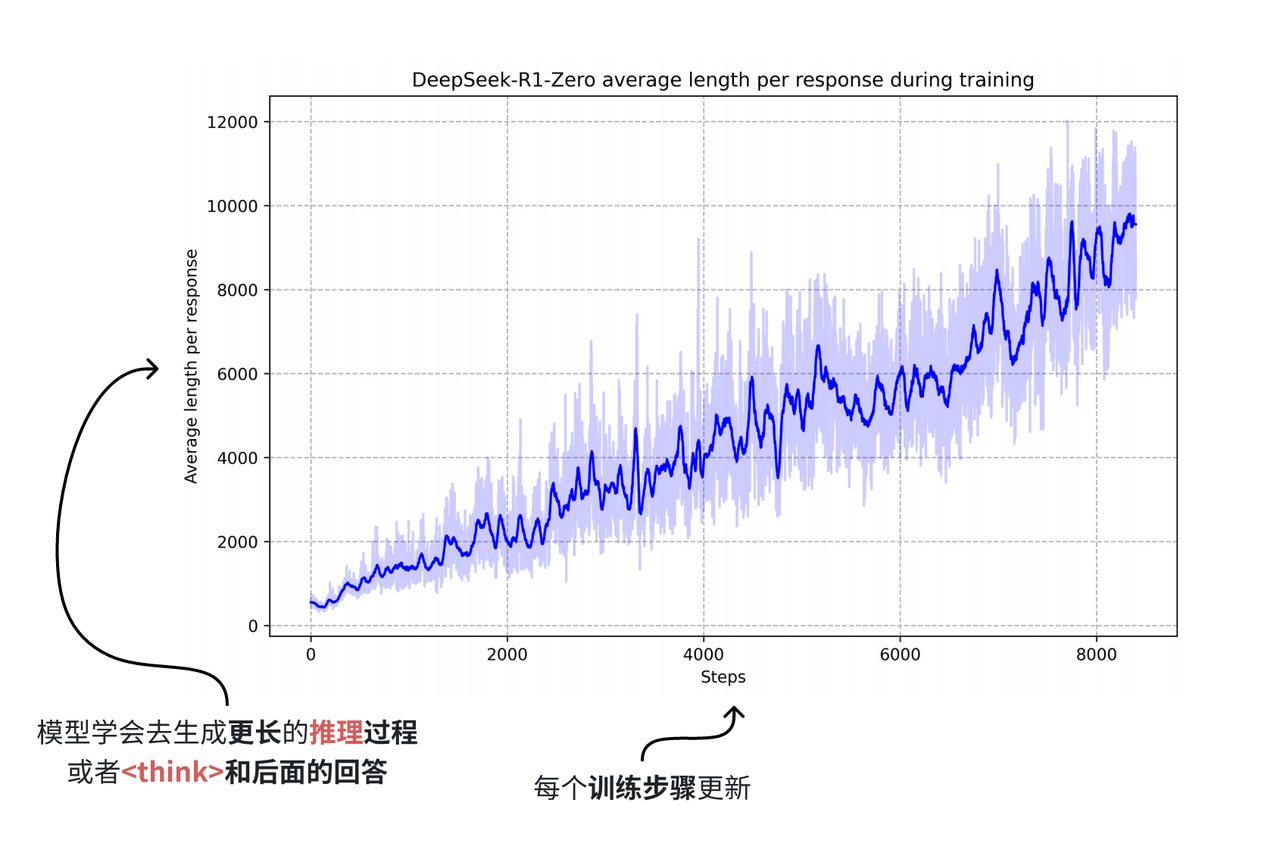
通过这样的训练流程,研究人员发现,模型能够自发地探索出最优的链式推理模式,并展现出如自我反思、自我验证等高级推理能力。
不过,这种做法仍存在一个显著缺陷:其输出的可读性不佳,而且有时会混用多种语言,这是仅用强化学习导致的弊端,没有微调阶段对回答模式加以限制,推理时错误的概率就会比较高。为了解决这个问题,团队转而研究另一种思路,在后续GRPO学习中添加了语言类的奖励信号,同时因为V3-Base强大的生成能力,通过V3-Base合成的“思考型”数据作为微调时所用的微调数据,对预训练模型进行微调,就能让模型快速学会这种思考方式。
总结下来,“思考型”数据只能由模型生成,当然质量问题是基础,不过可能模型生成的“思考型”数据也不一定质量很高,因为可能存在大量重复思考过程,更重要的是,现有的数据中基本没有包含思考过程的数据。
因此合成数据对于提高模型思考推理能力是必要的,想要让模型具备思考能力,要么通过强化训练自己合成数据自己微调,这对于模型的规模要求较高,因为小规模模型不一定有强大的能力;要么通过知识蒸馏,把大模型具备的思考能力迁移到小规模模型中。
推理合成数据举例
虽然DeepSeek技术报告中的80w条数据并未开源,但是训练数据的格式基本包含下面三个部分:
input:请说说三原色分别是什么
reasoning_content:好的,用户……
content:三原色分别是……其中:
input:问答对中的问题部分reasoning_content:这部分是模型的思考部分,其实在输出中由<think></think>特殊字符包裹的部分,里面包含模型的推理、反思等内容,是一段非常长的文本content:该部分是模型的最终输出内容,也包含在输出中,通常在</think>特殊字符后面,作为模型给出的标准回答,模型在输出的时候可以通过对话模板自动检测出特殊字符,从而提取模型最终的输出
我们可以在huggingface社区中找到开源的基于R1生成的SFT数据:
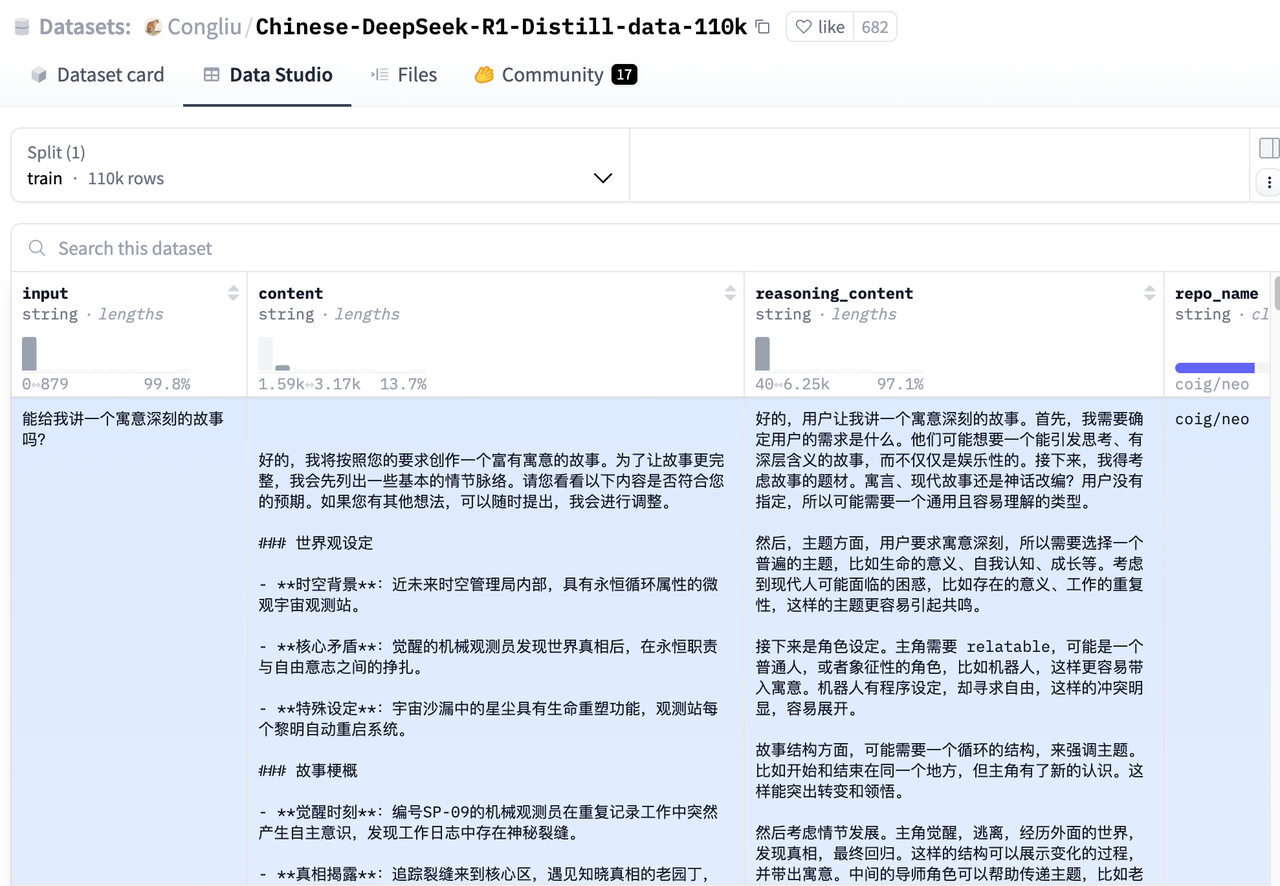
该数据集为中文开源蒸馏满血R1的数据集,数据集中不仅包含math数据,还包括大量的通用类型数据,总数量为110K。
由于强化学习对资源要求比较高,并且训练时间通常非常漫长,想要通过GPRO在小模型上复现R1其实不太现实,因此如果想快速实现R1的功能,可以采用蒸馏的方法,该数据集可以很好的实现在小模型上蒸馏R1的能力,有兴趣的朋友可以利用该数据集对小模型比如Qwen系列7B以下的模型进行SFT,从而让规模较小的模型实现思考推理能力。
推理合成数据代码实践
由于推理数据需要本身就具备思考过程的模型来实现,我们所熟悉的deepseek-r1还有Qwen3都有思考模块,我们选择Qwen3,为什么选择Qwen而不是DeepSeek,因为我们使用阿里百炼平台通过调用API的形式调用模型来生成数据,Qwen3能快点,DeeSeek-R1有点慢而已,用R1也绝对没有任何问题。
我们提供了简易的生成代码,链接在这,代码构成如下:
instruct_data_gengeration/
├── generate.py # 数据生成
└── data/ # 生成的数据保存地址为方便起见,我们直接选择alpaca中文版的指令和输入作为整体的输入数据,让Qwen3去生成思考+回答,作为我们的推理数据。我们简单分成下面两步:
- 下载Alpaca数据
- 调用Qwen3生成推理数据
我们直接运行下面的代码,就可以完整的生成推理数据:
python generation.py因为我们只是举例说明,我们只生成了10条数据,批量生成数据的话可以修改数量。
