Ascend NPU & MindSpore
SwanLab支持Ascend系列显卡的硬件检测和mindspore项目的训练跟踪。(计划20241215硬件监控上线)
SwanLab实验记录Ascend NPU信息截图:
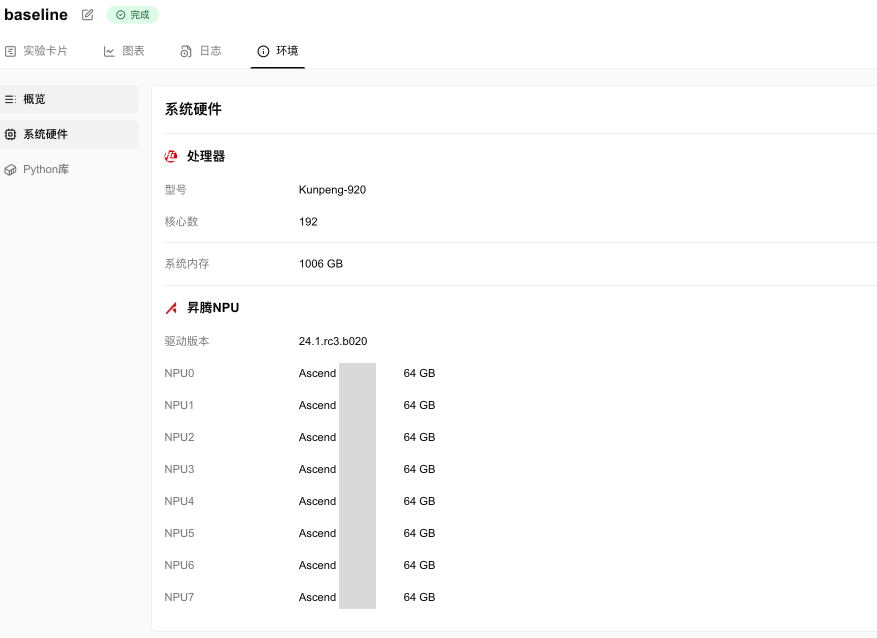
简介
本案例使用实现的IMDB数据集情感分类任务。并使用SwanLab跟踪模型训练进展。
任务介绍
IMDB情感分类任务是一种自然语言处理任务,旨在分析IMDB(Internet Movie Database)电影评论中的文本内容,以判断评论的情感倾向,通常分为正面(Positive)和负面(Negative)两类。该任务广泛用于研究情感分析技术,尤其是在监督学习和深度学习领域。
数据集中通常包含预处理好的评论文本及其对应的情感标签,每条评论均标注为正面或负面。如下图:

LSTM(Long Short-Term Memory)是一种改进的循环神经网络,专为处理和预测序列数据中的长距离依赖而设计。与传统RNN相比,LSTM通过引入记忆单元和门机制,能够有效缓解梯度消失和梯度爆炸问题,使其在长序列数据的建模中表现优异。使用LSTM能轻松完成IMDB的语言情感分类任务。关于LSTM的具体原理建议参考大神博客
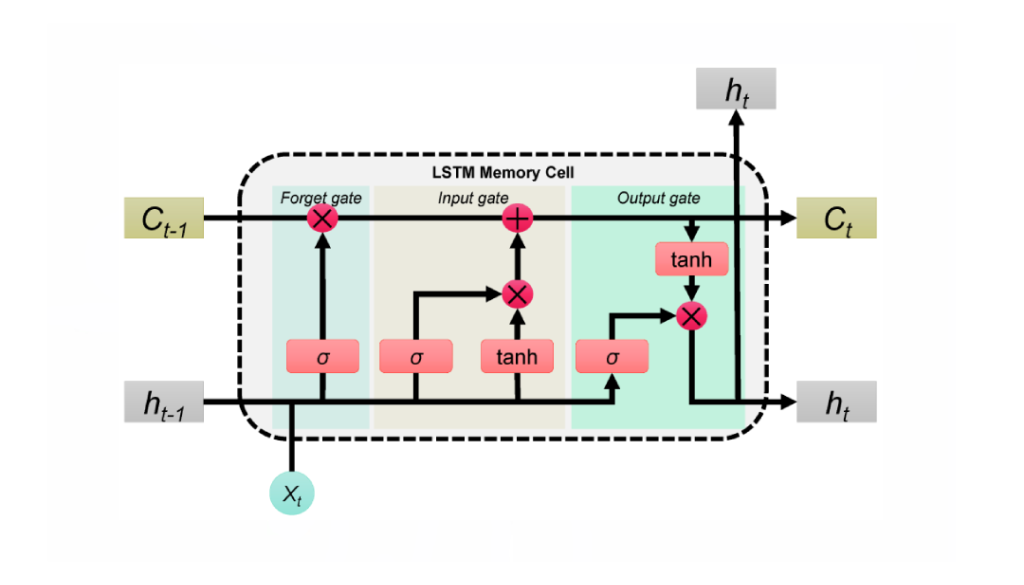
本代码参考MindSpore官方文档,进行整理并简化了部分实现.
环境安装
克隆项目
附上github项目链接和下载命令
git clone https://github.com/ShaohonChen/mindspore_imdb_train.git如果访问不了github可在本博客后文找到代码章节
推荐还是用github 😉
CPU环境安装
可以在CPU环境下安装MindSpore,虽然看起来没有Pytorch那么好用,但实际上文档还是写的很细的,真的很细,看得出华为工程师的严谨orz。配合sheng腾卡使用的话是非常有潜力的框架(MAC死活打不出sheng字)。
官方安装文档link
也可以直接使用如下命令安装:
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.4.1/MindSpore/unified/x86_64/mindspore-2.4.1-cp311-cp311-linux_x86_64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple验证安装成功命令:
python -c "import mindspore;mindspore.set_context(device_target='CPU');mindspore.run_check()"如果输出如下信息说明MindSpore安装成功了:
MindSpore version: 2.4.1
The result of multiplication calculation is correct, MindSpore has been installed on platform [CPU] successfully!华为Ascend NPU显卡环境安装
由于华为Ascend环境安装较为复杂,建议参考MindSpore安装教程和踩坑记录教程完成MindSpore环境安装。下面简述MindSpore安装过程
本博客写的时间是2024年12月6日,安装的版本是MindSpore2.4.1,因为感觉MindSpore变动会比较大特意记录一下时间和版本。
驱动安装&验证
首先得确定有NPU卡和NPU相关驱动,驱动是8.0.RC3.beta1,如果没安装可以参考CANN官方安装教程
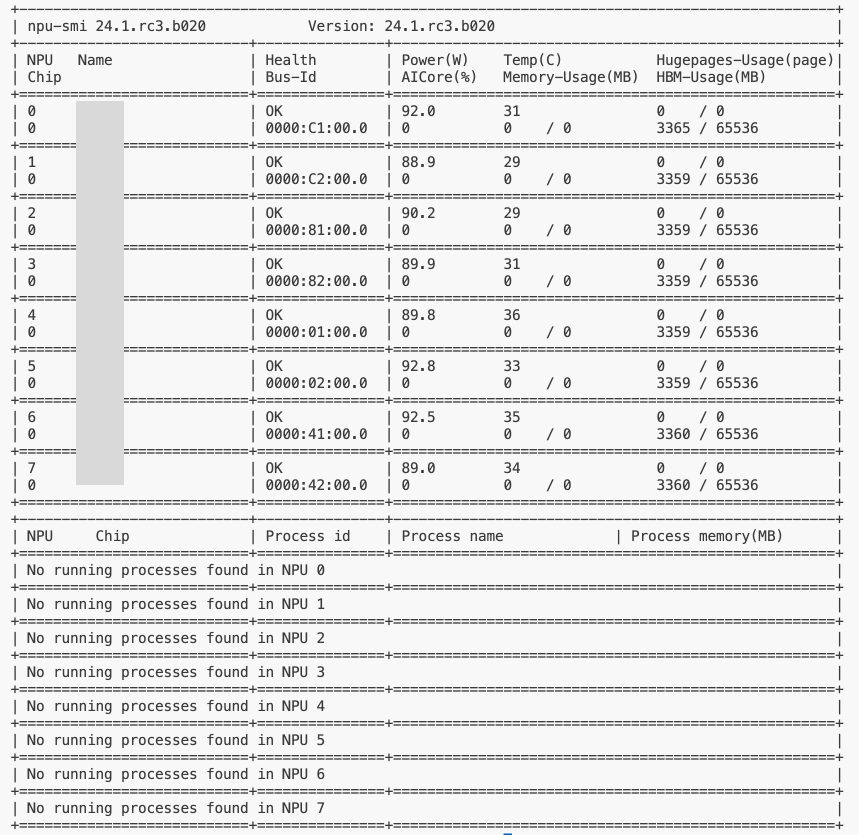
完成安装后检测方法是运行
npu-smi info可以看到如下信息的话就表示驱动已经安装完成了。
安装MindSpore
个人比较推荐使用conda安装,这样环境比较好管理,自动安装的依赖项也比较多
首先需要安装前置依赖的包:
pip install sympy
pip install "numpy>=1.20.0,<2.0.0"
pip install /usr/local/Ascend/ascend-toolkit/latest/lib64/te-*-py3-none-any.whl
pip install /usr/local/Ascend/ascend-toolkit/latest/lib64/hccl-*-py3-none-any.whl如果本地下载比较慢可以使用带国内源版本的命令
pip install sympy -i https://mirrors.cernet.edu.cn/pypi/web/simple
pip install "numpy>=1.20.0,<2.0.0" -i https://mirrors.cernet.edu.cn/pypi/web/simple
pip install /usr/local/Ascend/ascend-toolkit/latest/lib64/te-*-py3-none-any.whl -i https://mirrors.cernet.edu.cn/pypi/web/simple
pip install /usr/local/Ascend/ascend-toolkit/latest/lib64/hccl-*-py3-none-any.whl -i https://mirrors.cernet.edu.cn/pypi/web/simpleconda安装MindSpore方法如下:
conda install mindspore=2.4.1 -c mindspore -c conda-forge因为某些众所周知的原因,有时候conda源会失效,反应出来就是conda安装mindspore时会进度一直为0%,如下图:
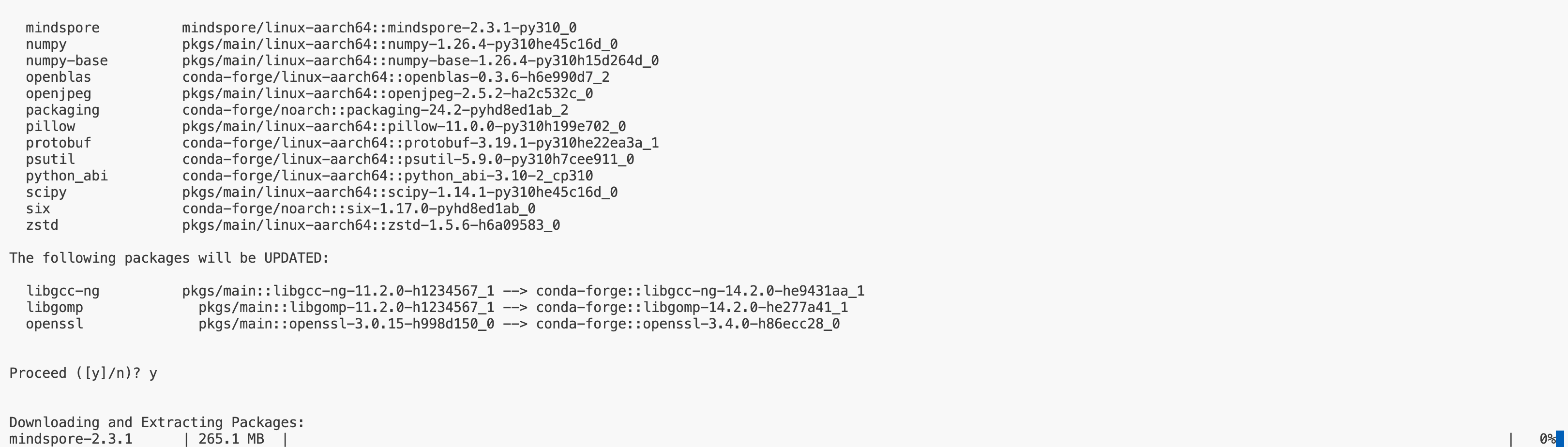
可以使用如下方法指定国内源:
conda install mindspore=2.4.1 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/MindSpore/ -c conda-forgepip安装MindSpore命令如下:
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.4.1/MindSpore/unified/aarch64/mindspore-2.4.1-cp311-cp311-linux_aarch64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple安装完成后可以使用如下命令进行测试
python -c "import mindspore;mindspore.set_context(device_target='Ascend');mindspore.run_check()"如果这步出现报错可以参考本文后面环境安装疑难杂症章节
出现版本号信息和计算验证便意味着安装成功
MindSpore version: 2.4.1
The result of multiplication calculation is correct, MindSpore has been installed on platform [Ascend] successfully!也附上官方安装教程链接mindspore官方安装教程,注意本教程使用的是Mindspore 2.4.1,建议环境与本教程保持一致。
此外本教程使用SwanLab进行训练过程跟踪,SwanLab支持对Ascend系列NPU进行硬件识别和跟踪。
记得安装SwanLab 😉
安装方法:
pip install swanlab数据集&词编码文件准备
数据集准备
Linux使用如下命令完成下载+解压
wget -P ./data/ https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
tar -xzvf data/aclImdb_v1.tar.gz -C data/如果下载太慢可以使用华为云提供的国内链接下载。并且在./data/目录下解压。
如果解压不了tar.gz推荐安装7zip解压器,开源且通用的解压器
词编码器准备
使用如下命令下载+解压词编码器文件
wget -P ./embedding/ https://nlp.stanford.edu/data/glove.6B.zip
unzip embedding/glove.6B.zip -d embedding/如果下载太慢可以使用华为云提供的国内链接下载。并且在./embedding/目录下解压。
开始训练
使用如下命令开始训练
python train.py可是这
如果提示登录swanlab,可以参考如何登录SwanLab,这样将能够使用云上看版随时查看训练过程与结果。
完成设置便可以在云上实时看到训练进展,我的实验记录可参考完整实验记录
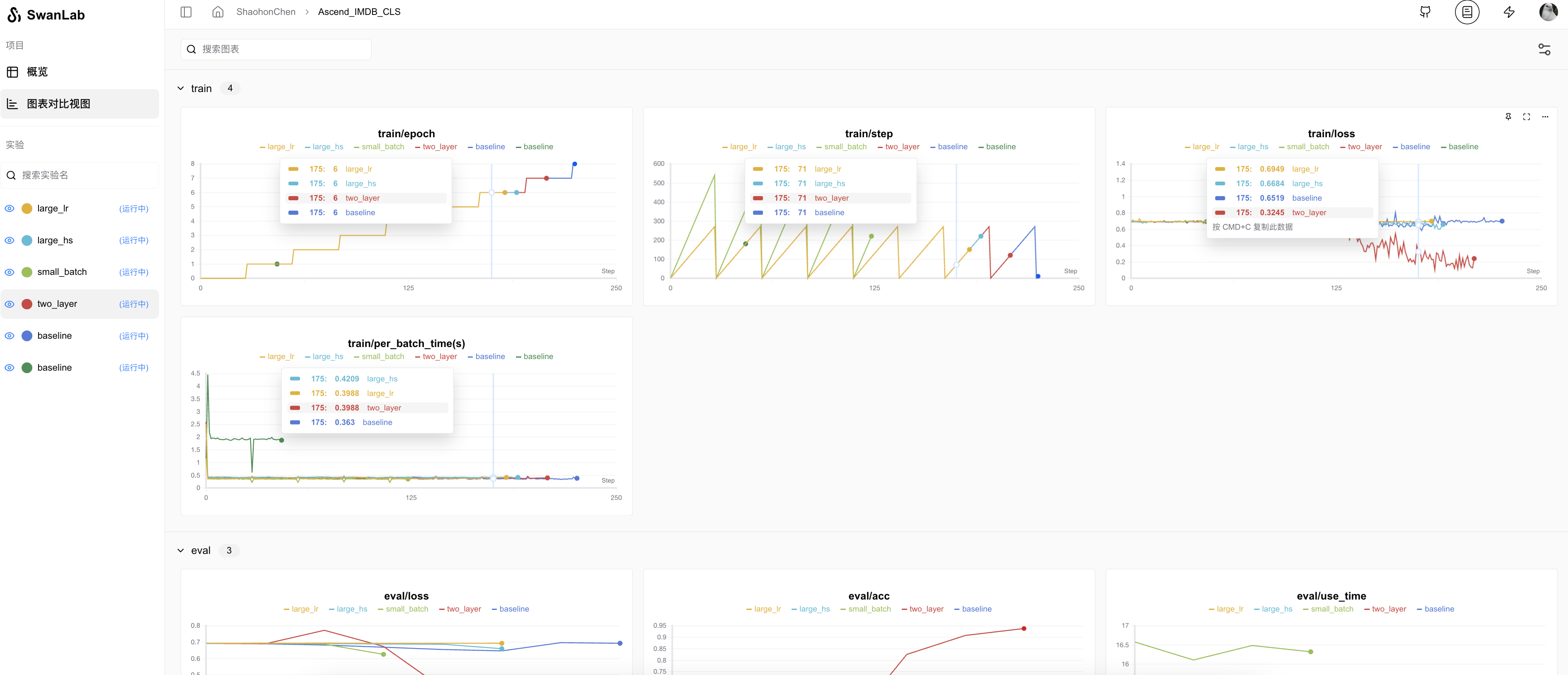
并且附上其他脚本与在线实验记录:
| 内容 | 训练命令 | 实验log |
|---|---|---|
| 基线 | python train.py configs/baseline.json | log |
| CPU运行 | python train.py configs/baseline.json CPU | log |
| 双层LSTM | python train.py configs/two_layer.json | log |
| 小batch数 | python train.py configs/small_batch.json | log |
| 隐藏层加大 | python train.py configs/large_hs.json | log |
| 学习率加大 | python train.py configs/large_hs.json | log |
相关超参数和最终结果可在图标视图查看
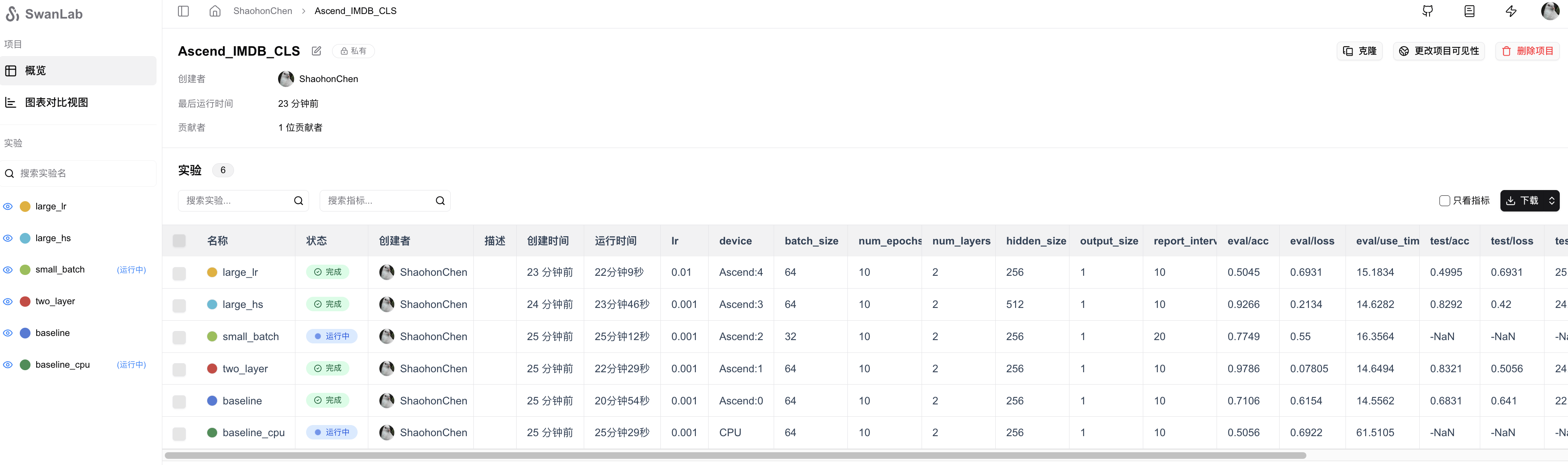
PS: 观察了下日志,发现还是训练量不足,应该增大些训练量(40-50epoch比较合适)
代码章节
如果访问不了github也提供一段测试代码,不过就是没法使用其他超参数了T_T
# 读取训练参数+初始化日志记录
import os
import sys
import json
import mindspore as ms
import swanlab
# ms.set_context(device_target="CPU") # 使用CPU
ms.set_context(device_target="Ascend") # 使用NPU
args={ # 超参数
"hidden_size": 256,
"output_size": 1,
"num_layers": 2,
"lr": 0.001,
"num_epochs": 10,
"batch_size": 64,
"report_interval": 10
}
exp_name = "baseline"
swanlab.init(project="Ascend_IMDB_CLS", experiment_name=exp_name, config=args)
# 构造数据集
import mindspore.dataset as ds
class IMDBData:
label_map = {"pos": 1, "neg": 0}
def __init__(self, path, mode="train"):
self.docs, self.labels = [], []
for label in self.label_map.keys():
doc_dir = os.path.join(path, mode, label)
doc_list = os.listdir(doc_dir)
for fname in doc_list:
with open(os.path.join(doc_dir, fname)) as f:
doc = f.read()
doc = doc.lower().split()
self.docs.append(doc)
self.labels.append([self.label_map[label]])
def __getitem__(self, idx):
return self.docs[idx], self.labels[idx]
def __len__(self):
return len(self.docs)
imdb_path = "data/aclImdb"
imdb_train = ds.GeneratorDataset(
IMDBData(imdb_path, "train"), column_names=["text", "label"], shuffle=True
)
imdb_test = ds.GeneratorDataset(
IMDBData(imdb_path, "test"), column_names=["text", "label"], shuffle=False
)
# 构造embedding词表
import numpy as np
def load_glove(glove_path):
embeddings = []
tokens = []
with open(os.path.join(glove_path, "glove.6B.100d.txt"), encoding="utf-8") as gf:
for glove in gf:
word, embedding = glove.split(maxsplit=1)
tokens.append(word)
embeddings.append(np.fromstring(embedding, dtype=np.float32, sep=" "))
# 添加 <unk>, <pad> 两个特殊占位符对应的embedding
embeddings.append(np.random.rand(100))
embeddings.append(np.zeros((100,), np.float32))
vocab = ds.text.Vocab.from_list(
tokens, special_tokens=["<unk>", "<pad>"], special_first=False
)
embeddings = np.array(embeddings).astype(np.float32)
return vocab, embeddings
vocab, embeddings = load_glove("./embedding")
print(f"VOCAB SIZE: {len(vocab.vocab())}")
# 数据预处理
import mindspore as ms
lookup_op = ds.text.Lookup(vocab, unknown_token="<unk>")
pad_op = ds.transforms.PadEnd([500], pad_value=vocab.tokens_to_ids("<pad>"))
type_cast_op = ds.transforms.TypeCast(ms.float32)
imdb_train = imdb_train.map(operations=[lookup_op, pad_op], input_columns=["text"])
imdb_train = imdb_train.map(operations=[type_cast_op], input_columns=["label"])
imdb_test = imdb_test.map(operations=[lookup_op, pad_op], input_columns=["text"])
imdb_test = imdb_test.map(operations=[type_cast_op], input_columns=["label"])
imdb_train, imdb_valid = imdb_train.split([0.7, 0.3])
print(f"TRAIN SET SIZE: {len(imdb_train)}")
print(f"VALID SET SIZE: {len(imdb_valid)}")
print(f"TEST SET SIZE: {len(imdb_test)}")
imdb_train = imdb_train.batch(args["batch_size"], drop_remainder=True)
imdb_valid = imdb_valid.batch(args["batch_size"], drop_remainder=True)
# LSTM分类器实现
import math
import mindspore as ms
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore.common.initializer import Uniform, HeUniform
class LSTM_CLS(nn.Cell):
def __init__(self, embeddings, hidden_dim, output_dim, n_layers, pad_idx):
super().__init__()
vocab_size, embedding_dim = embeddings.shape
self.embedding = nn.Embedding(
vocab_size,
embedding_dim,
embedding_table=ms.Tensor(embeddings),
padding_idx=pad_idx,
)
self.rnn = nn.LSTM(
embedding_dim, hidden_dim, num_layers=n_layers, batch_first=True
)
weight_init = HeUniform(math.sqrt(5))
bias_init = Uniform(1 / math.sqrt(hidden_dim * 2))
self.fc = nn.Dense(
hidden_dim, output_dim, weight_init=weight_init, bias_init=bias_init
)
def construct(self, inputs):
embedded = self.embedding(inputs)
_, (hidden, _) = self.rnn(embedded)
hidden = hidden[-1, :, :]
output = self.fc(hidden)
return output
model = LSTM_CLS(
embeddings,
args["hidden_size"],
args["output_size"],
args["num_layers"],
vocab.tokens_to_ids("<pad>"),
)
# 损失函数与优化器
loss_fn = nn.BCEWithLogitsLoss(reduction="mean")
optimizer = nn.Adam(model.trainable_params(), learning_rate=args["lr"])
# 训练过程实现
from tqdm import tqdm
import time
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss
grad_fn = ms.value_and_grad(forward_fn, None, optimizer.parameters)
def train_step(data, label):
loss, grads = grad_fn(data, label)
optimizer(grads)
return loss
def train_one_epoch(model, train_dataset, epoch=0):
model.set_train()
total = train_dataset.get_dataset_size()
step_total = 0
last_time = time.time()
for i in train_dataset.create_tuple_iterator():
loss = train_step(*i)
step_total += 1
loss_item = loss.item()
if step_total % args["report_interval"] == 1:
now_time = time.time()
per_batch_time = (now_time - last_time) / args["report_interval"]
last_time = now_time
swanlab.log(
{
"train/epoch": epoch,
"train/step": step_total,
"train/loss": loss_item,
"train/per_batch_time(s)": per_batch_time,
}
)
print(
f"[train epoch-{epoch:2d} step-{step_total:4d}/{total:4d}] loss:{loss_item:.4f} use_time:{per_batch_time:10.4f}s"
)
# 评估过程实现
def binary_accuracy(preds, y):
rounded_preds = np.around(ops.sigmoid(preds).asnumpy())
correct = (rounded_preds == y).astype(np.float32)
acc = correct.sum() / len(correct)
return acc
def evaluate(model, test_dataset, criterion, epoch=0, mode="eval"):
last_time = time.time()
total = test_dataset.get_dataset_size()
epoch_loss = 0
epoch_acc = 0
model.set_train(False)
for i in test_dataset.create_tuple_iterator():
predictions = model(i[0])
loss = criterion(predictions, i[1])
epoch_loss += loss.asnumpy()
acc = binary_accuracy(predictions, i[1])
epoch_acc += acc
final_loss = float(epoch_loss / total)
final_acc = float(epoch_acc / total)
use_time = time.time() - last_time
swanlab.log(
{
f"{mode}/loss": final_loss,
f"{mode}/acc": final_acc,
f"{mode}/use_time": use_time,
}
)
print(
f"[{mode} epoch-{epoch:2d} loss:{final_loss:.4f} acc:{final_acc*100:.2f}% use_time:{use_time:10.4f}s"
)
return final_loss, final_acc
# 开启训练=
best_valid_loss = float("inf")
save_path = os.path.join("output", exp_name)
os.makedirs(save_path, exist_ok=True)
ckpt_file_name = os.path.join(save_path, "sentiment-analysis.ckpt")
for epoch in range(args["num_epochs"]):
train_one_epoch(model, imdb_train, epoch)
valid_loss, _ = evaluate(model, imdb_valid, loss_fn, epoch)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
ms.save_checkpoint(model, ckpt_file_name)
# 开始测试
param_dict = ms.load_checkpoint(ckpt_file_name)
ms.load_param_into_net(model, param_dict)
imdb_test = imdb_test.batch(64)
test_loss, test_acc = evaluate(model, imdb_test, loss_fn, mode="test")
# 开始预测
score_map = {1: "Positive", 0: "Negative"}
def predict_sentiment(model, vocab, sentence):
model.set_train(False)
tokenized = sentence.lower().split()
indexed = vocab.tokens_to_ids(tokenized)
tensor = ms.Tensor(indexed, ms.int32)
tensor = tensor.expand_dims(0)
prediction = model(tensor)
return score_map[int(np.round(ops.sigmoid(prediction).asnumpy()))]
predict_sentiment(model, vocab, "This film is great")
predict_sentiment(model, vocab, "This film is terrible")疑难杂症
可能出现的问题一:MindSpore和CANN版本不对应
务必确保MindSpore版本和驱动一致,否则会出现如下报错:
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:11.112.000 [mindspore/run_check/_check_version.py:357] MindSpore version 2.3.1 and Ascend AI software package (Ascend Data Center Solution)version 7.5 does not match, the version of software package expect one of ['7.2', '7.3']. Please refer to the match info on: https://www.mindspore.cn/install
/home/huawei/miniconda3/envs/mindspore231/lib/python3.10/site-packages/numpy/core/getlimits.py:549: UserWarning: The value of the smallest subnormal for <class 'numpy.float64'> type is zero.
setattr(self, word, getattr(machar, word).flat[0])
/home/huawei/miniconda3/envs/mindspore231/lib/python3.10/site-packages/numpy/core/getlimits.py:89: UserWarning: The value of the smallest subnormal for <class 'numpy.float64'> type is zero.
return self._float_to_str(self.smallest_subnormal)
/home/huawei/miniconda3/envs/mindspore231/lib/python3.10/site-packages/numpy/core/getlimits.py:549: UserWarning: The value of the smallest subnormal for <class 'numpy.float32'> type is zero.
setattr(self, word, getattr(machar, word).flat[0])
/home/huawei/miniconda3/envs/mindspore231/lib/python3.10/site-packages/numpy/core/getlimits.py:89: UserWarning: The value of the smallest subnormal for <class 'numpy.float32'> type is zero.
return self._float_to_str(self.smallest_subnormal)
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:13.700.000 [mindspore/run_check/_check_version.py:375] MindSpore version 2.3.1 and "te" wheel package version 7.5 does not match. For details, refer to the installation guidelines: https://www.mindspore.cn/install
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:13.701.000 [mindspore/run_check/_check_version.py:382] MindSpore version 2.3.1 and "hccl" wheel package version 7.5 does not match. For details, refer to the installation guidelines: https://www.mindspore.cn/install
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:13.702.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 3
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:14.703.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 2
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:15.704.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 1
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:18.608.000 [mindspore/run_check/_check_version.py:357] MindSpore version 2.3.1 and Ascend AI software package (Ascend Data Center Solution)version 7.5 does not match, the version of software package expect one of ['7.2', '7.3']. Please refer to the match info on: https://www.mindspore.cn/install
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:18.608.000 [mindspore/run_check/_check_version.py:375] MindSpore version 2.3.1 and "te" wheel package version 7.5 does not match. For details, refer to the installation guidelines: https://www.mindspore.cn/install
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:18.608.000 [mindspore/run_check/_check_version.py:382] MindSpore version 2.3.1 and "hccl" wheel package version 7.5 does not match. For details, refer to the installation guidelines: https://www.mindspore.cn/install
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:18.608.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 3
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:19.609.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 2
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:20.611.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 1
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:21.614.000 [mindspore/run_check/_check_version.py:357] MindSpore version 2.3.1 and Ascend AI software package (Ascend Data Center Solution)version 7.5 does not match, the version of software package expect one of ['7.2', '7.3']. Please refer to the match info on: https://www.mindspore.cn/install
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:21.614.000 [mindspore/run_check/_check_version.py:375] MindSpore version 2.3.1 and "te" wheel package version 7.5 does not match. For details, refer to the installation guidelines: https://www.mindspore.cn/install
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:21.614.000 [mindspore/run_check/_check_version.py:382] MindSpore version 2.3.1 and "hccl" wheel package version 7.5 does not match. For details, refer to the installation guidelines: https://www.mindspore.cn/install
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:21.615.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 3
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:22.616.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 2
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:23.617.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 1
MindSpore version: 2.3.1
Segmentation fault (core dumped)解决方法:装对版本即可解决。对于MindSpore2.4.1,安装8.0.RC3.beta1驱动
可能出现的问题二:少装了前置的包
这里面
[ERROR] ME(1051780:281473416683552,MainProcess):2024-12-06-12:39:02.460.00 [mindspore/run_check/_check_version.py:360] CheckFailed: cannot import name 'version' from 'te' (unknown location)
[ERROR] ME(1051780:281473416683552,MainProcess):2024-12-06-12:39:02.460.00 [mindspore/run_check/_check_version.py:361] MindSpore relies on whl packages of "te" and "hccl" in the "latest" folder of the Ascend AI software package (Ascend Data Center Solution). Please check whether they are installed correctly or not, refer to the match info on: https://www.mindspore.cn/install
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/huawei/miniconda3/envs/mindspore241/lib/python3.11/site-packages/mindspore/__init__.py", line 19, in <module>
from mindspore import common, dataset, mindrecord, train, log, amp
...
ImportError: cannot import name 'util' from 'tbe.tvm.topi.cce' (unknown location)
Fatal Python error: PyThreadState_Get: the function must be called with the GIL held, but the GIL is released (the current Python thread state is NULL)
Python runtime state: finalizing (tstate=0x00000000008aceb0)
Aborted (core dumped)可能出现的问题三:pip安装阶段报错opc-tool 0.1.0 requires attrs, which is not installed
若出现如下报错(之前安装的时候有概率pip会报如下错误):
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
auto-tune 0.1.0 requires decorator, which is not installed.
dataflow 0.0.1 requires jinja2, which is not installed.
opc-tool 0.1.0 requires attrs, which is not installed.
opc-tool 0.1.0 requires decorator, which is not installed.
opc-tool 0.1.0 requires psutil, which is not installed.
schedule-search 0.0.1 requires absl-py, which is not installed.
schedule-search 0.0.1 requires decorator, which is not installed.
te 0.4.0 requires attrs, which is not installed.
te 0.4.0 requires cloudpickle, which is not installed.
te 0.4.0 requires decorator, which is not installed.
te 0.4.0 requires ml-dtypes, which is not installed.
te 0.4.0 requires psutil, which is not installed.
te 0.4.0 requires scipy, which is not installed.
te 0.4.0 requires tornado, which is not installed.尝试使用如下命令解决:
pip install attrs cloudpickle decorator jinja2 ml-dtypes psutil scipy tornado absl-py可能出现的问题四:在测试或者实际训练的时候出现KeyError: 'op_debug_dir'
出现如下情况大概率是没有运行环境变量命令。
Traceback (most recent call last):
File "/home/huawei/miniconda3/envs/mindspore241/lib/python3.11/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/home/huawei/miniconda3/envs/mindspore241/lib/python3.11/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/home/huawei/.local/lib/python3.11/site-packages/te_fusion/parallel_compilation.py", line 249, in exec_compilation_task
check_dict_paras(dict_ops)
File "/home/huawei/.local/lib/python3.11/site-packages/te_fusion/parallel_compilation.py", line 183, in check_dict_paras
if dict_ops['op_debug_dir'] == None or dict_ops['op_debug_dir'] == '':
~~~~~~~~^^^^^^^^^^^^^^^^
KeyError: 'op_debug_dir'解决方法:使用如下命令设置环境变量
# control log level. 0-DEBUG, 1-INFO, 2-WARNING, 3-ERROR, 4-CRITICAL, default level is WARNING.
export GLOG_v=2
# environment variables
LOCAL_ASCEND=/usr/local/Ascend # 设置为软件包的实际安装路径
# set environmet variables using script provided by CANN, swap "ascend-toolkit" with "nnae" if you are using CANN-nnae package instead
source ${LOCAL_ASCEND}/ascend-toolkit/set_env.sh使用conda的时候发现似乎每次都要运行一次如上命令。如果想要永久解决这个问题,可以使用如下命令解决:
export LOCAL_ASCEND=/usr/local/Ascend # 设置为软件包的实际安装路径
echo "source ${LOCAL_ASCEND}/ascend-toolkit/set_env.sh" >> ~/.bashrc
source ~/.bashrc