Ascend NPU & MindSpore
SwanLab supports hardware detection for the Ascend series GPUs and training tracking for MindSpore projects. (Hardware monitoring is planned to be available by December 15, 2024.)
SwanLab experiment recording Ascend NPU information screenshot:
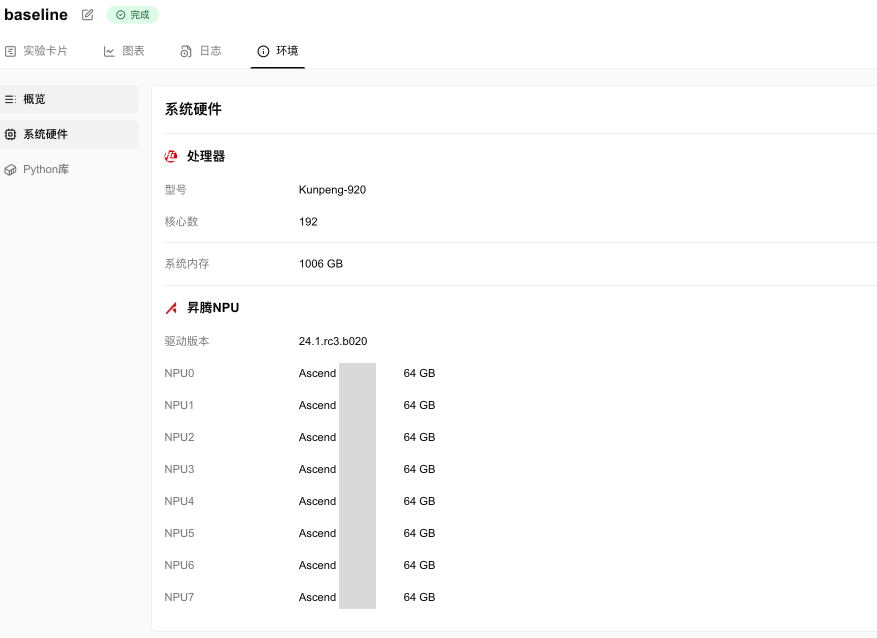
Introduction
This case implements an IMDB dataset sentiment classification task and uses SwanLab to track model training progress.
Task Overview
The IMDB sentiment classification task is a natural language processing task aimed at analyzing the text content of IMDB (Internet Movie Database) movie reviews to determine the sentiment tendency of the reviews, typically classified into positive (Positive) and negative (Negative) categories. This task is widely used in sentiment analysis research, especially in supervised learning and deep learning fields.
The dataset usually contains preprocessed review texts and their corresponding sentiment labels, with each review labeled as either positive or negative. As shown below:

LSTM (Long Short-Term Memory) is an improved recurrent neural network designed to handle and predict long-term dependencies in sequential data. Compared to traditional RNNs, LSTM introduces memory cells and gate mechanisms, effectively mitigating the vanishing and exploding gradient problems, making it perform well in modeling long-sequence data. Using LSTM, the IMDB sentiment classification task can be easily accomplished. For detailed principles of LSTM, it is recommended to refer to this expert blog.
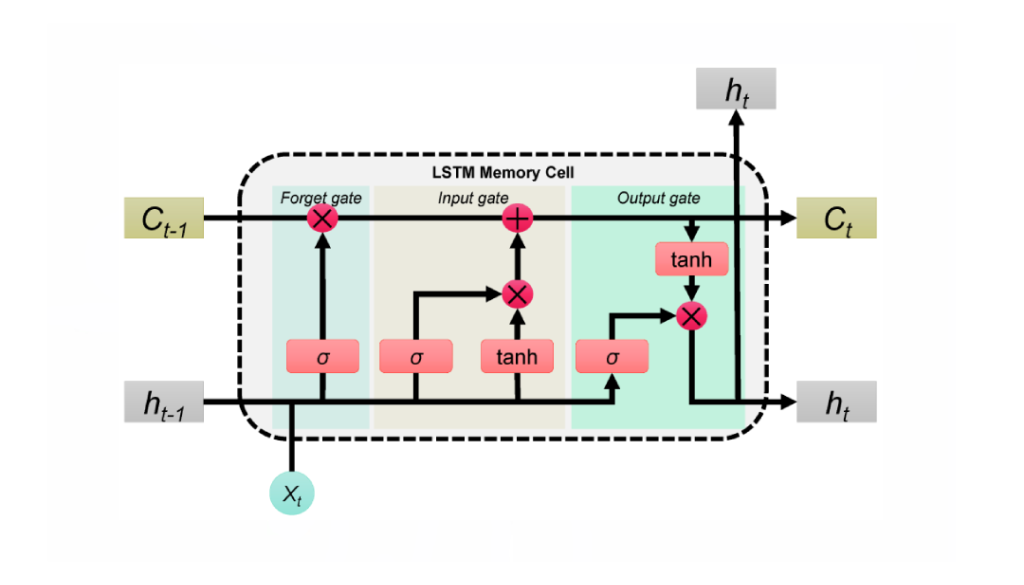
This code is based on the MindSpore official documentation, with some implementations simplified and organized.
Environment Setup
Clone the Project
Attached is the GitHub project link and the download command:
git clone https://github.com/ShaohonChen/mindspore_imdb_train.gitIf GitHub is inaccessible, you can find the code section later in this blog.
It is recommended to use GitHub 😉
CPU Environment Setup
You can install MindSpore in a CPU environment. Although it may not seem as user-friendly as PyTorch, the documentation is very detailed, reflecting the rigor of Huawei engineers. When used with Ascend GPUs, it is a very promising framework (MAC can't type the word "sheng" for some reason).
Official installation documentation link.
Alternatively, you can use the following command to install:
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.4.1/MindSpore/unified/x86_64/mindspore-2.4.1-cp311-cp311-linux_x86_64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simpleCommand to verify successful installation:
python -c "import mindspore;mindspore.set_context(device_target='CPU');mindspore.run_check()"If the following information is output, MindSpore has been successfully installed:
MindSpore version: 2.4.1
The result of multiplication calculation is correct, MindSpore has been installed on platform [CPU] successfully!Huawei Ascend NPU GPU Environment Setup
Due to the complexity of the Huawei Ascend environment setup, it is recommended to refer to the MindSpore Installation Tutorial and Pitfall Record to complete the MindSpore environment setup. Below is a brief overview of the MindSpore installation process.
This blog was written on December 6, 2024, and the installed version is MindSpore 2.4.1. Given the rapid changes in MindSpore, the time and version are specifically noted.
Driver Installation & Verification
First, ensure that the NPU card and NPU-related drivers are installed. The driver version is 8.0.RC3.beta1. If not installed, refer to the CANN Official Installation Tutorial.
After installation, the detection method is to run:
npu-smi infoIf the following information is displayed, the driver installation is complete.
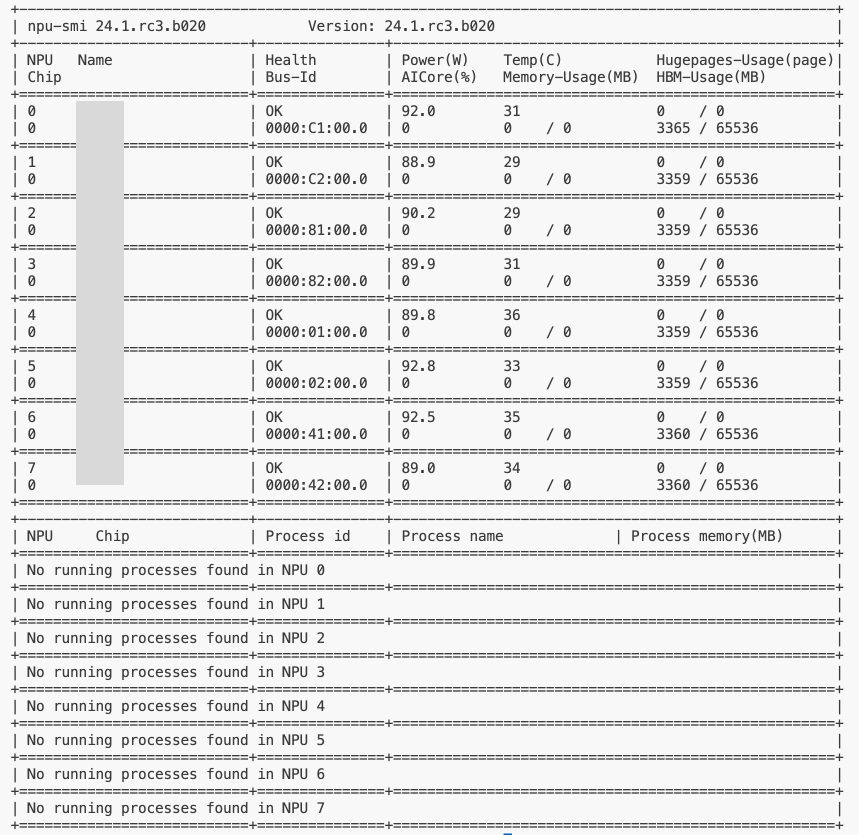
Install MindSpore
It is recommended to use conda for installation, as it is easier to manage environments and automatically installs more dependencies.
First, install the prerequisite packages:
pip install sympy
pip install "numpy>=1.20.0,<2.0.0"
pip install /usr/local/Ascend/ascend-toolkit/latest/lib64/te-*-py3-none-any.whl
pip install /usr/local/Ascend/ascend-toolkit/latest/lib64/hccl-*-py3-none-any.whlIf the local download is slow, you can use the following commands with domestic mirrors:
pip install sympy -i https://mirrors.cernet.edu.cn/pypi/web/simple
pip install "numpy>=1.20.0,<2.0.0" -i https://mirrors.cernet.edu.cn/pypi/web/simple
pip install /usr/local/Ascend/ascend-toolkit/latest/lib64/te-*-py3-none-any.whl -i https://mirrors.cernet.edu.cn/pypi/web/simple
pip install /usr/local/Ascend/ascend-toolkit/latest/lib64/hccl-*-py3-none-any.whl -i https://mirrors.cernet.edu.cn/pypi/web/simpleConda installation method for MindSpore:
conda install mindspore=2.4.1 -c mindspore -c conda-forgeDue to certain well-known reasons, the conda source may sometimes fail, resulting in the conda installation of MindSpore being stuck at 0% progress, as shown below:
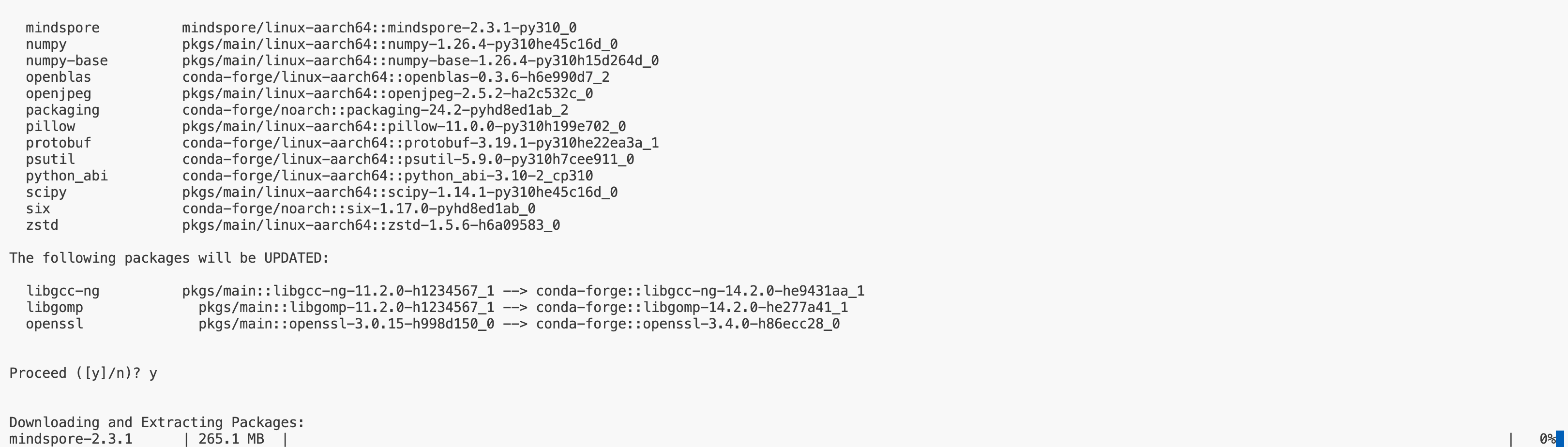
You can use the following method to specify a domestic mirror:
conda install mindspore=2.4.1 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/MindSpore/ -c conda-forgePip installation command for MindSpore:
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.4.1/MindSpore/unified/aarch64/mindspore-2.4.1-cp311-cp311-linux_aarch64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simpleAfter installation, you can use the following command to test:
python -c "import mindspore;mindspore.set_context(device_target='Ascend');mindspore.run_check()"If an error occurs at this step, refer to the Environment Installation Troubleshooting section later in this document.
If the version information and calculation verification are displayed, the installation is successful.
MindSpore version: 2.4.1
The result of multiplication calculation is correct, MindSpore has been installed on platform [Ascend] successfully!Also attached is the official installation tutorial link MindSpore Official Installation Tutorial. Note that this tutorial uses MindSpore 2.4.1, and it is recommended to keep the environment consistent with this tutorial.
Additionally, this tutorial uses SwanLab for training process tracking. SwanLab supports hardware identification and tracking for the Ascend series NPUs.
Don't Forget to Install SwanLab 😉
Installation method:
pip install swanlabDataset & Word Encoding File Preparation
Dataset Preparation
Use the following command to download and extract the dataset on Linux:
wget -P ./data/ https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
tar -xzvf data/aclImdb_v1.tar.gz -C data/If the download is too slow, you can use the Huawei Cloud provided domestic link to download. Extract it in the ./data/ directory.
If you can't extract tar.gz, it is recommended to install the 7zip extractor, an open-source and universal extractor.
Word Encoder Preparation
Use the following command to download and extract the word encoder file:
wget -P ./embedding/ https://nlp.stanford.edu/data/glove.6B.zip
unzip embedding/glove.6B.zip -d embedding/If the download is too slow, you can use the Huawei Cloud provided domestic link to download. Extract it in the ./embedding/ directory.
Start Training
Use the following command to start training:
python train.pyHowever, this
If prompted to log in to SwanLab, refer to How to Log in to SwanLab, which will allow you to use the cloud dashboard to view the training process and results in real-time.
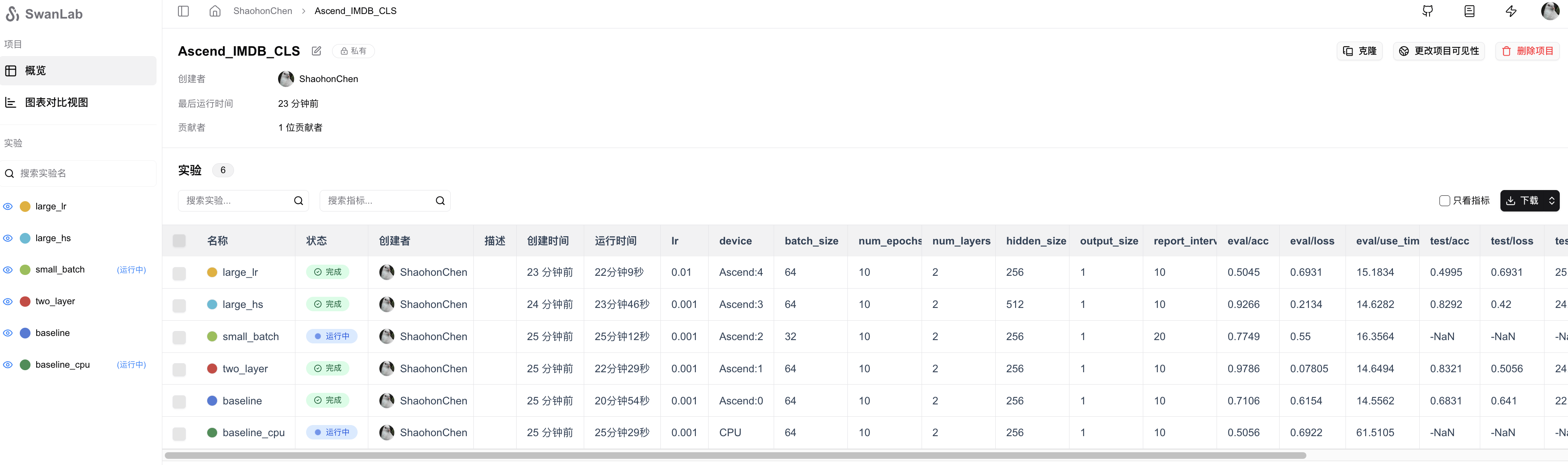
After setup, you can view the training progress in real-time on the cloud. My experiment record can be referenced at Complete Experiment Record.
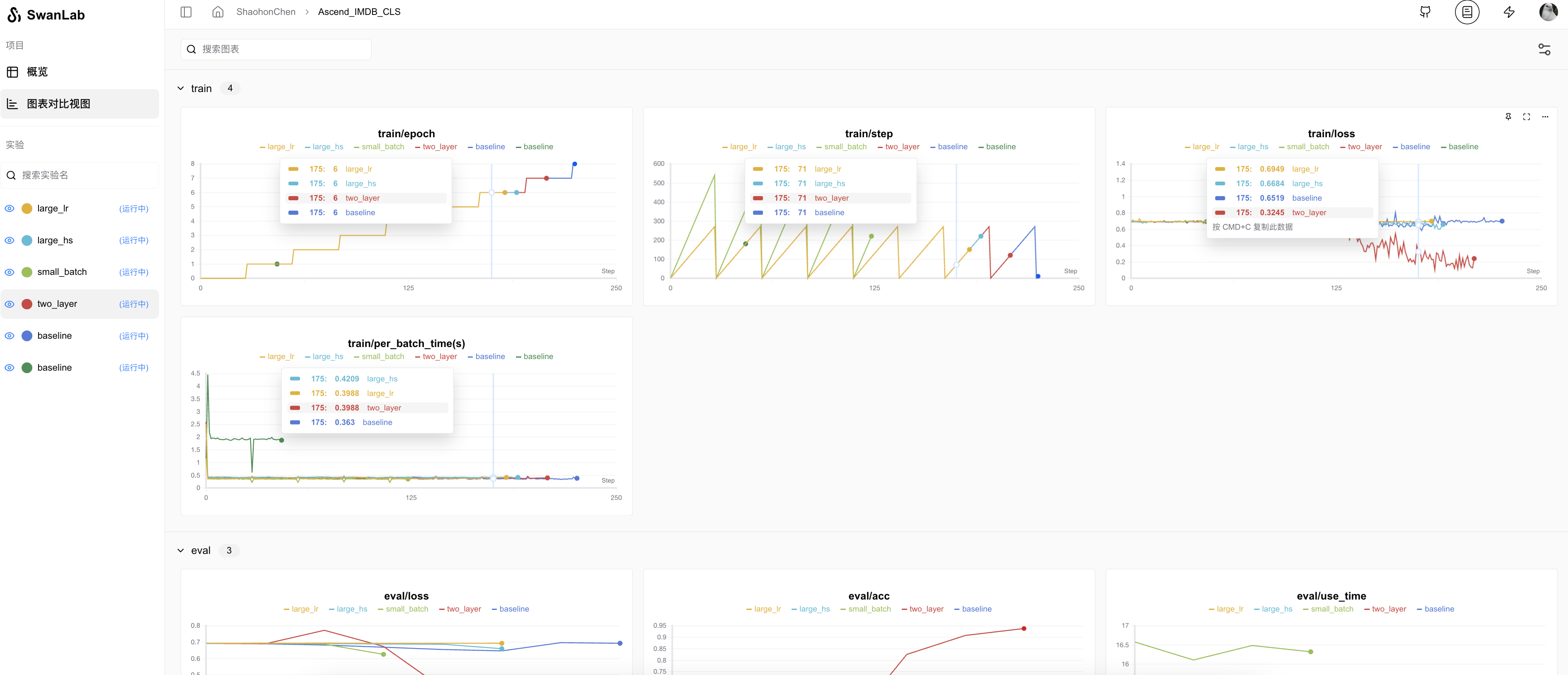
Also attached are other scripts and online experiment records:
| Content | Training Command | Experiment Log |
|---|---|---|
| Baseline | python train.py configs/baseline.json | log |
| CPU Run | python train.py configs/baseline.json CPU | log |
| Two-Layer LSTM | python train.py configs/two_layer.json | log |
| Small Batch Size | python train.py configs/small_batch.json | log |
| Larger Hidden Layer | python train.py configs/large_hs.json | log |
| Larger Learning Rate | python train.py configs/large_hs.json | log |
Related hyperparameters and final results can be viewed in the Chart View.
PS: After observing the logs, it seems that the training volume is insufficient. It is recommended to increase the training volume (40-50 epochs would be more appropriate).
Code Section
If GitHub is inaccessible, a test code snippet is provided below, although it cannot use other hyperparameters T_T.
# Read training parameters + initialize log recording
import os
import sys
import json
import mindspore as ms
import swanlab
# ms.set_context(device_target="CPU") # Use CPU
ms.set_context(device_target="Ascend") # Use NPU
args={ # Hyperparameters
"hidden_size": 256,
"output_size": 1,
"num_layers": 2,
"lr": 0.001,
"num_epochs": 10,
"batch_size": 64,
"report_interval": 10
}
exp_name = "baseline"
swanlab.init(project="Ascend_IMDB_CLS", experiment_name=exp_name, config=args)
# Construct dataset
import mindspore.dataset as ds
class IMDBData:
label_map = {"pos": 1, "neg": 0}
def __init__(self, path, mode="train"):
self.docs, self.labels = [], []
for label in self.label_map.keys():
doc_dir = os.path.join(path, mode, label)
doc_list = os.listdir(doc_dir)
for fname in doc_list:
with open(os.path.join(doc_dir, fname)) as f:
doc = f.read()
doc = doc.lower().split()
self.docs.append(doc)
self.labels.append([self.label_map[label]])
def __getitem__(self, idx):
return self.docs[idx], self.labels[idx]
def __len__(self):
return len(self.docs)
imdb_path = "data/aclImdb"
imdb_train = ds.GeneratorDataset(
IMDBData(imdb_path, "train"), column_names=["text", "label"], shuffle=True
)
imdb_test = ds.GeneratorDataset(
IMDBData(imdb_path, "test"), column_names=["text", "label"], shuffle=False
)
# Construct embedding vocabulary
import numpy as np
def load_glove(glove_path):
embeddings = []
tokens = []
with open(os.path.join(glove_path, "glove.6B.100d.txt"), encoding="utf-8") as gf:
for glove in gf:
word, embedding = glove.split(maxsplit=1)
tokens.append(word)
embeddings.append(np.fromstring(embedding, dtype=np.float32, sep=" "))
# Add <unk>, <pad> two special placeholders corresponding embedding
embeddings.append(np.random.rand(100))
embeddings.append(np.zeros((100,), np.float32))
vocab = ds.text.Vocab.from_list(
tokens, special_tokens=["<unk>", "<pad>"], special_first=False
)
embeddings = np.array(embeddings).astype(np.float32)
return vocab, embeddings
vocab, embeddings = load_glove("./embedding")
print(f"VOCAB SIZE: {len(vocab.vocab())}")
# Data preprocessing
import mindspore as ms
lookup_op = ds.text.Lookup(vocab, unknown_token="<unk>")
pad_op = ds.transforms.PadEnd([500], pad_value=vocab.tokens_to_ids("<pad>"))
type_cast_op = ds.transforms.TypeCast(ms.float32)
imdb_train = imdb_train.map(operations=[lookup_op, pad_op], input_columns=["text"])
imdb_train = imdb_train.map(operations=[type_cast_op], input_columns=["label"])
imdb_test = imdb_test.map(operations=[lookup_op, pad_op], input_columns=["text"])
imdb_test = imdb_test.map(operations=[type_cast_op], input_columns=["label"])
imdb_train, imdb_valid = imdb_train.split([0.7, 0.3])
print(f"TRAIN SET SIZE: {len(imdb_train)}")
print(f"VALID SET SIZE: {len(imdb_valid)}")
print(f"TEST SET SIZE: {len(imdb_test)}")
imdb_train = imdb_train.batch(args["batch_size"], drop_remainder=True)
imdb_valid = imdb_valid.batch(args["batch_size"], drop_remainder=True)
# LSTM classifier implementation
import math
import mindspore as ms
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore.common.initializer import Uniform, HeUniform
class LSTM_CLS(nn.Cell):
def __init__(self, embeddings, hidden_dim, output_dim, n_layers, pad_idx):
super().__init__()
vocab_size, embedding_dim = embeddings.shape
self.embedding = nn.Embedding(
vocab_size,
embedding_dim,
embedding_table=ms.Tensor(embeddings),
padding_idx=pad_idx,
)
self.rnn = nn.LSTM(
embedding_dim, hidden_dim, num_layers=n_layers, batch_first=True
)
weight_init = HeUniform(math.sqrt(5))
bias_init = Uniform(1 / math.sqrt(hidden_dim * 2))
self.fc = nn.Dense(
hidden_dim, output_dim, weight_init=weight_init, bias_init=bias_init
)
def construct(self, inputs):
embedded = self.embedding(inputs)
_, (hidden, _) = self.rnn(embedded)
hidden = hidden[-1, :, :]
output = self.fc(hidden)
return output
model = LSTM_CLS(
embeddings,
args["hidden_size"],
args["output_size"],
args["num_layers"],
vocab.tokens_to_ids("<pad>"),
)
# 损失函数与优化器
loss_fn = nn.BCEWithLogitsLoss(reduction="mean")
optimizer = nn.Adam(model.trainable_params(), learning_rate=args["lr"])
# 训练过程实现
from tqdm import tqdm
import time
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss
grad_fn = ms.value_and_grad(forward_fn, None, optimizer.parameters)
def train_step(data, label):
loss, grads = grad_fn(data, label)
optimizer(grads)
return loss
def train_one_epoch(model, train_dataset, epoch=0):
model.set_train()
total = train_dataset.get_dataset_size()
step_total = 0
last_time = time.time()
for i in train_dataset.create_tuple_iterator():
loss = train_step(*i)
step_total += 1
loss_item = loss.item()
if step_total % args["report_interval"] == 1:
now_time = time.time()
per_batch_time = (now_time - last_time) / args["report_interval"]
last_time = now_time
swanlab.log(
{
"train/epoch": epoch,
"train/step": step_total,
"train/loss": loss_item,
"train/per_batch_time(s)": per_batch_time,
}
)
print(
f"[train epoch-{epoch:2d} step-{step_total:4d}/{total:4d}] loss:{loss_item:.4f} use_time:{per_batch_time:10.4f}s"
)
# 评估过程实现
def binary_accuracy(preds, y):
rounded_preds = np.around(ops.sigmoid(preds).asnumpy())
correct = (rounded_preds == y).astype(np.float32)
acc = correct.sum() / len(correct)
return acc
def evaluate(model, test_dataset, criterion, epoch=0, mode="eval"):
last_time = time.time()
total = test_dataset.get_dataset_size()
epoch_loss = 0
epoch_acc = 0
model.set_train(False)
for i in test_dataset.create_tuple_iterator():
predictions = model(i[0])
loss = criterion(predictions, i[1])
epoch_loss += loss.asnumpy()
acc = binary_accuracy(predictions, i[1])
epoch_acc += acc
final_loss = float(epoch_loss / total)
final_acc = float(epoch_acc / total)
use_time = time.time() - last_time
swanlab.log(
{
f"{mode}/loss": final_loss,
f"{mode}/acc": final_acc,
f"{mode}/use_time": use_time,
}
)
print(
f"[{mode} epoch-{epoch:2d} loss:{final_loss:.4f} acc:{final_acc*100:.2f}% use_time:{use_time:10.4f}s"
)
return final_loss, final_acc
# 开启训练=
best_valid_loss = float("inf")
save_path = os.path.join("output", exp_name)
os.makedirs(save_path, exist_ok=True)
ckpt_file_name = os.path.join(save_path, "sentiment-analysis.ckpt")
for epoch in range(args["num_epochs"]):
train_one_epoch(model, imdb_train, epoch)
valid_loss, _ = evaluate(model, imdb_valid, loss_fn, epoch)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
ms.save_checkpoint(model, ckpt_file_name)
# 开始测试
param_dict = ms.load_checkpoint(ckpt_file_name)
ms.load_param_into_net(model, param_dict)
imdb_test = imdb_test.batch(64)
test_loss, test_acc = evaluate(model, imdb_test, loss_fn, mode="test")
# 开始预测
score_map = {1: "Positive", 0: "Negative"}
def predict_sentiment(model, vocab, sentence):
model.set_train(False)
tokenized = sentence.lower().split()
indexed = vocab.tokens_to_ids(tokenized)
tensor = ms.Tensor(indexed, ms.int32)
tensor = tensor.expand_dims(0)
prediction = model(tensor)
return score_map[int(np.round(ops.sigmoid(prediction).asnumpy()))]
predict_sentiment(model, vocab, "This film is great")
predict_sentiment(model, vocab, "This film is terrible")Troubleshooting
Possible Problem 1: Incompatible MindSpore and CANN Versions
Ensure that the MindSpore version is consistent with the driver version. Otherwise, the following error will occur:
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:11.112.000 [mindspore/run_check/_check_version.py:357] MindSpore version 2.3.1 and Ascend AI software package (Ascend Data Center Solution)version 7.5 does not match, the version of software package expect one of ['7.2', '7.3']. Please refer to the match info on: https://www.mindspore.cn/install
/home/huawei/miniconda3/envs/mindspore231/lib/python3.10/site-packages/numpy/core/getlimits.py:549: UserWarning: The value of the smallest subnormal for <class 'numpy.float64'> type is zero.
setattr(self, word, getattr(machar, word).flat[0])
/home/huawei/miniconda3/envs/mindspore231/lib/python3.10/site-packages/numpy/core/getlimits.py:89: UserWarning: The value of the smallest subnormal for <class 'numpy.float64'> type is zero.
return self._float_to_str(self.smallest_subnormal)
/home/huawei/miniconda3/envs/mindspore231/lib/python3.10/site-packages/numpy/core/getlimits.py:549: UserWarning: The value of the smallest subnormal for <class 'numpy.float32'> type is zero.
setattr(self, word, getattr(machar, word).flat[0])
/home/huawei/miniconda3/envs/mindspore231/lib/python3.10/site-packages/numpy/core/getlimits.py:89: UserWarning: The value of the smallest subnormal for <class 'numpy.float32'> type is zero.
return self._float_to_str(self.smallest_subnormal)
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:13.700.000 [mindspore/run_check/_check_version.py:375] MindSpore version 2.3.1 and "te" wheel package version 7.5 does not match. For details, refer to the installation guidelines: https://www.mindspore.cn/install
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:13.701.000 [mindspore/run_check/_check_version.py:382] MindSpore version 2.3.1 and "hccl" wheel package version 7.5 does not match. For details, refer to the installation guidelines: https://www.mindspore.cn/install
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:13.702.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 3
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:14.703.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 2
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:15.704.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 1
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:18.608.000 [mindspore/run_check/_check_version.py:357] MindSpore version 2.3.1 and Ascend AI software package (Ascend Data Center Solution)version 7.5 does not match, the version of software package expect one of ['7.2', '7.3']. Please refer to the match info on: https://www.mindspore.cn/install
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:18.608.000 [mindspore/run_check/_check_version.py:375] MindSpore version 2.3.1 and "te" wheel package version 7.5 does not match. For details, refer to the installation guidelines: https://www.mindspore.cn/install
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:18.608.000 [mindspore/run_check/_check_version.py:382] MindSpore version 2.3.1 and "hccl" wheel package version 7.5 does not match. For details, refer to the installation guidelines: https://www.mindspore.cn/install
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:18.608.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 3
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:19.609.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 2
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:20.611.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 1
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:21.614.000 [mindspore/run_check/_check_version.py:357] MindSpore version 2.3.1 and Ascend AI software package (Ascend Data Center Solution)version 7.5 does not match, the version of software package expect one of ['7.2', '7.3']. Please refer to the match info on: https://www.mindspore.cn/install
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:21.614.000 [mindspore/run_check/_check_version.py:375] MindSpore version 2.3.1 and "te" wheel package version 7.5 does not match. For details, refer to the installation guidelines: https://www.mindspore.cn/install
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:21.614.000 [mindspore/run_check/_check_version.py:382] MindSpore version 2.3.1 and "hccl" wheel package version 7.5 does not match. For details, refer to the installation guidelines: https://www.mindspore.cn/install
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:21.615.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 3
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:22.616.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 2
[WARNING] ME(1049852:281473041023008,MainProcess):2024-12-06-12:23:23.617.000 [mindspore/run_check/_check_version.py:396] Please pay attention to the above warning, countdown: 1
MindSpore version: 2.3.1
Segmentation fault (core dumped)Solution: Install the correct version. For MindSpore 2.4.1, install the 8.0.RC3.beta1 driver.
Possible Problem 2: Missing Prerequisite Packages
The following error may occur:
[ERROR] ME(1051780:281473416683552,MainProcess):2024-12-06-12:39:02.460.00 [mindspore/run_check/_check_version.py:360] CheckFailed: cannot import name 'version' from 'te' (unknown location)
[ERROR] ME(1051780:281473416683552,MainProcess):2024-12-06-12:39:02.460.00 [mindspore/run_check/_check_version.py:361] MindSpore relies on whl packages of "te" and "hccl" in the "latest" folder of the Ascend AI software package (Ascend Data Center Solution). Please check whether they are installed correctly or not, refer to the match info on: https://www.mindspore.cn/install
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/huawei/miniconda3/envs/mindspore241/lib/python3.11/site-packages/mindspore/__init__.py", line 19, in <module>
from mindspore import common, dataset, mindrecord, train, log, amp
...
ImportError: cannot import name 'util' from 'tbe.tvm.topi.cce' (unknown location)
Fatal Python error: PyThreadState_Get: the function must be called with the GIL held, but the GIL is released (the current Python thread state is NULL)
Python runtime state: finalizing (tstate=0x00000000008aceb0)
Aborted (core dumped)Possible Problem 3: Error in pip Installation Stage - opc-tool 0.1.0 requires attrs, which is not installed
If the following error occurs (there is a probability that pip may report the following error during previous installations):
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
auto-tune 0.1.0 requires decorator, which is not installed.
dataflow 0.0.1 requires jinja2, which is not installed.
opc-tool 0.1.0 requires attrs, which is not installed.
opc-tool 0.1.0 requires decorator, which is not installed.
opc-tool 0.1.0 requires psutil, which is not installed.
schedule-search 0.0.1 requires absl-py, which is not installed.
schedule-search 0.0.1 requires decorator, which is not installed.
te 0.4.0 requires attrs, which is not installed.
te 0.4.0 requires cloudpickle, which is not installed.
te 0.4.0 requires decorator, which is not installed.
te 0.4.0 requires ml-dtypes, which is not installed.
te 0.4.0 requires psutil, which is not installed.
te 0.4.0 requires scipy, which is not installed.
te 0.4.0 requires tornado, which is not installed.Try to solve it using the following command:
pip install attrs cloudpickle decorator jinja2 ml-dtypes psutil scipy tornado absl-pyPossible Problem 4: KeyError: 'op_debug_dir' Occurs During Testing or Actual Training
The following situation is likely to occur when the environment variable command has not been run.
Traceback (most recent call last):
File "/home/huawei/miniconda3/envs/mindspore241/lib/python3.11/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/home/huawei/miniconda3/envs/mindspore241/lib/python3.11/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/home/huawei/.local/lib/python3.11/site-packages/te_fusion/parallel_compilation.py", line 249, in exec_compilation_task
check_dict_paras(dict_ops)
File "/home/huawei/.local/lib/python3.11/site-packages/te_fusion/parallel_compilation.py", line 183, in check_dict_paras
if dict_ops['op_debug_dir'] == None or dict_ops['op_debug_dir'] == '':
~~~~~~~~^^^^^^^^^^^^^^^^
KeyError: 'op_debug_dir'Solution: Set the environment variables using the following commands
# control log level. 0-DEBUG, 1-INFO, 2-WARNING, 3-ERROR, 4-CRITICAL, default level is WARNING.
export GLOG_v=2
# environment variables
LOCAL_ASCEND=/usr/local/Ascend # Set to the actual installation path of the software package
# set environmet variables using script provided by CANN, swap "ascend-toolkit" with "nnae" if you are using CANN-nnae package instead
source ${LOCAL_ASCEND}/ascend-toolkit/set_env.shWhen using conda, it seems that the above commands need to be run every time. If you want to solve this problem permanently, you can use the following commands:
export LOCAL_ASCEND=/usr/local/Ascend # Set to the actual installation path of the software package
echo "source ${LOCAL_ASCEND}/ascend-toolkit/set_env.sh" >> ~/.bashrc
source ~/.bashrc