EasyR1
EasyR1 is an efficient, scalable, and multimodal reinforcement learning (RL) large language model (LLM) training framework based on veRL.
EasyR1 benefits from veRL's HybridEngine and vLLM 0.7's SPMD mode and is adapted for the Qwen2.5-VL model. On the multimodal geometry problem task Geometry3k, training with 30 batches of GRPO can improve the verification set accuracy by 5%.
Author hiyouga: EasyR1 aims to explore the difficulties in multimodal RL training. The framework's efficiency, algorithm performance, and scalability are iteratively improved by the team's algorithm and engineering members. In the future, it will support more RL algorithms and multimodal models.
You can use EasyR1 to train your multimodal RL model and use SwanLab to track and visualize the training curve.
1. Preparation
Before executing the following commands, please ensure that Python>=3.9, CUDA, and PyTorch are installed in your environment.
git clone https://github.com/hiyouga/EasyR1.git
cd EasyR1
pip install -e.
pip install git+https://github.com/hiyouga/MathRuler.git
pip install swanlabNote
The installation of flash-attn in EasyR1's dependencies is very slow. Please find the package corresponding to your Python and CUDA versions in the flash-attention precompiled package, download and install it.
2. Training Qwen2.5-7b Mathematical Model
In the EasyR1 directory, execute the following command to train the Qwen2.5-7b mathematical model using GRPO and track and visualize it with SwanLab:
bash examples/run_qwen2_5_7b_math_swanlab.sh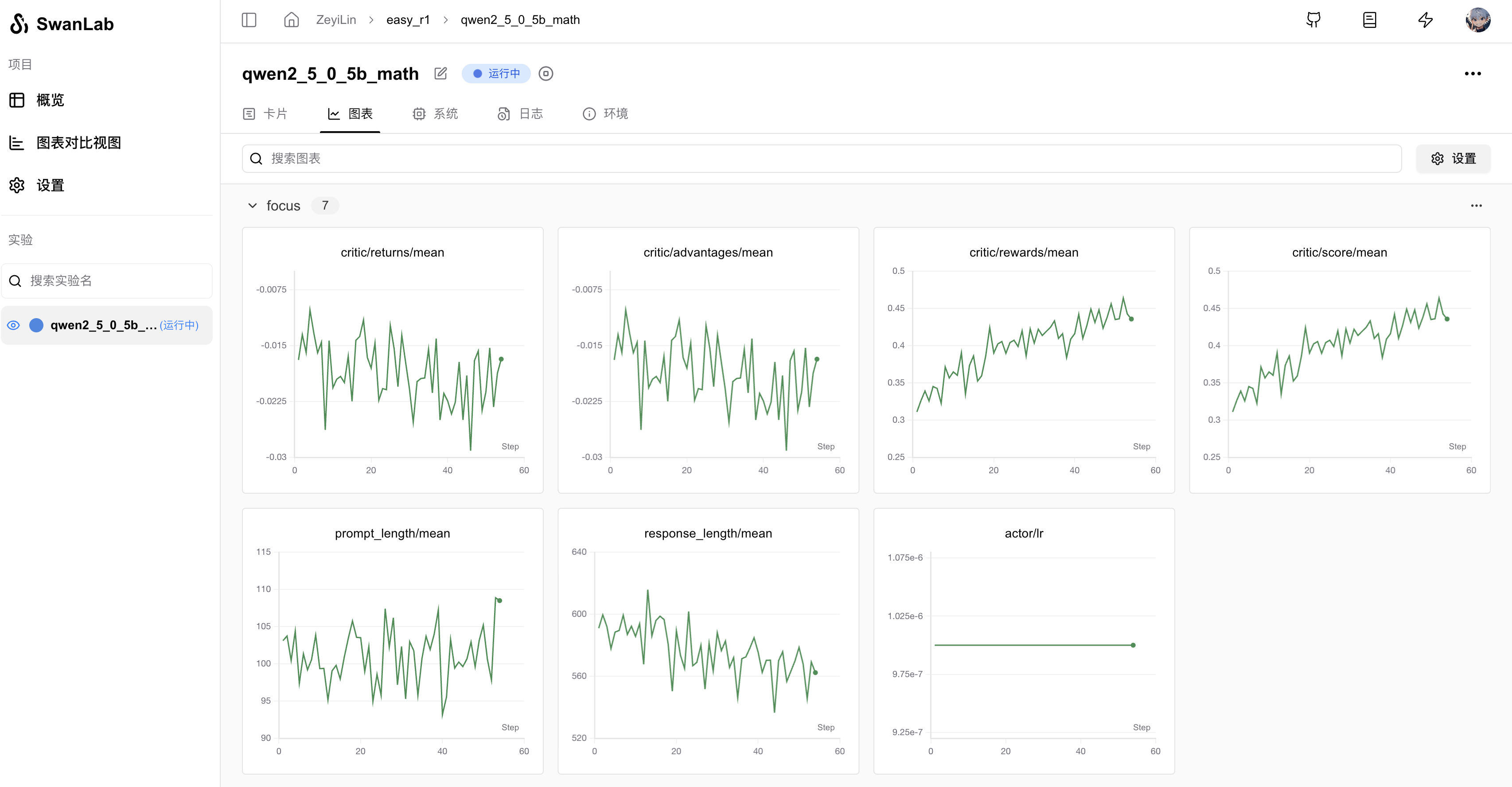
Of course, we can analyze that since EasyR1 is a clean fork of the original veRL project, it inherits the integration of veRL and SwanLab. Now let's take a look at the run_qwen2_5_7b_math_swanlab.sh file:
set -x
export VLLM_ATTENTION_BACKEND=XFORMERS
MODEL_PATH=Qwen/Qwen2.5-7B-Instruct # replace it with your local file path
python3 -m verl.trainer.main \
config=examples/grpo_example.yaml \
worker.actor.model.model_path=${MODEL_PATH} \
trainer.logger=['console','swanlab'] \
trainer.n_gpus_per_node=4By adding a line trainer.logger=['console','swanlab'] in the parameters of python3 -m verl.trainer.main, you can use SwanLab for tracking and visualization.
3. Training Qwen2.5-VL-7b Multimodal Model
In the EasyR1 directory, execute the following command to train the Qwen2.5-VL-7b multimodal model using GRPO and track and visualize it with SwanLab:
bash examples/run_qwen2_5_vl_7b_geo_swanlab.sh4. Record Generated Text During Each Evaluation Round
If you want to log the generated text to SwanLab during each evaluation round (val), simply add the line val_generations_to_log=1 in the command:
python3 -m verl.trainer.main \
config=examples/grpo_example.yaml \
worker.actor.model.model_path=${MODEL_PATH} \
trainer.logger=['console','swanlab'] \
trainer.n_gpus_per_node=4 \
val_generations_to_log=1Final Remarks
EasyR1 is a new open-source project by hiyouga, the author of LLaMA Factory, a reinforcement learning framework for multimodal large models. We thank hiyouga for his contributions to the global open-source ecosystem, and SwanLab will continue to accompany AI developers.