PaddleNLP大模型微调实战
作者:王超
机构:新疆大学丝路多语言认知计算国际合作联合实验室研究生、情感机器实习研究员
联系邮箱:akiyamaice@163.com
PaddleNLP是一款基于飞桨深度学习框架的大语言模型(LLM)开发套件,支持在多种硬件上进行高效的大模型训练、无损压缩以及高性能推理。PaddleNLP 具备简单易用和性能极致的特点,致力于助力开发者实现高效的大模型产业级应用。

🔧 核心特性
1. 丰富的预训练模型库
PaddleNLP提供了包括 BERT、ERNIE、RoBERTa、GPT 等在内的多种主流预训练模型,涵盖文本分类、序列标注、问答系统、文本生成等任务。这些模型可通过 paddlenlp.Taskflow 接口一键调用,简化了模型加载和预测流程。
2. 简洁易用的 API
提供统一的应用范式,支持数据加载、预处理、模型训练与推理的全流程开发。内置的模块如 Embedding、Transformer、CRF 等,方便用户快速构建和部署 NLP 应用。
3. 高性能分布式训练
支持多种并行训练策略(如数据并行、模型并行、流水线并行等),结合飞桨的 Fleet 分布式训练 API,可高效利用 GPU 集群资源,完成大规模预训练模型的训练任务。
4. 多硬件支持与推理优化
兼容多种硬件平台,包括英伟达 GPU、昆仑 XPU、昇腾 NPU 等,支持动态插入和全环节算子融合策略,提升推理速度和效率。
在本文中,我们会使用Qwen2.5-7B模型在 alpaca-gpt4-data-zh 数据集上做Lora微调训练。训练中用到了PaddleNLP等工具,同时使用SwanLab监控训练过程、评估模型效果。
1.环境安装
本案例Python==3.10.17,请在您的计算机上安装好Python;
首先,请确保您已安装好paddlepaddle-gpu或paddlepaddle(版本大于或等于3.0)。如果没有安装,请参考飞桨官网来进行安装。
CUDA11.8 可以参考下面的安装链接:
python -m pip install paddlepaddle-gpu==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/然后,安装PaddleNLP:
git clone https://github.com/PaddlePaddle/PaddleNLP.git
cd PaddleNLP
git checkout develop
pip install -e .此外,请保证环境内已安装了pytorch以及CUDA,同时请安装最新的swanlab:
pip install swanlab accelerate pandas addict2.准备数据集
本案例使用的是 alpaca-gpt4-data-zh数据集,该数据集为GPT-4生成的中文数据集,用于LLM的指令精调和强化学习等。
该数据集中每条数据包含Instruction、Input和Output三列:
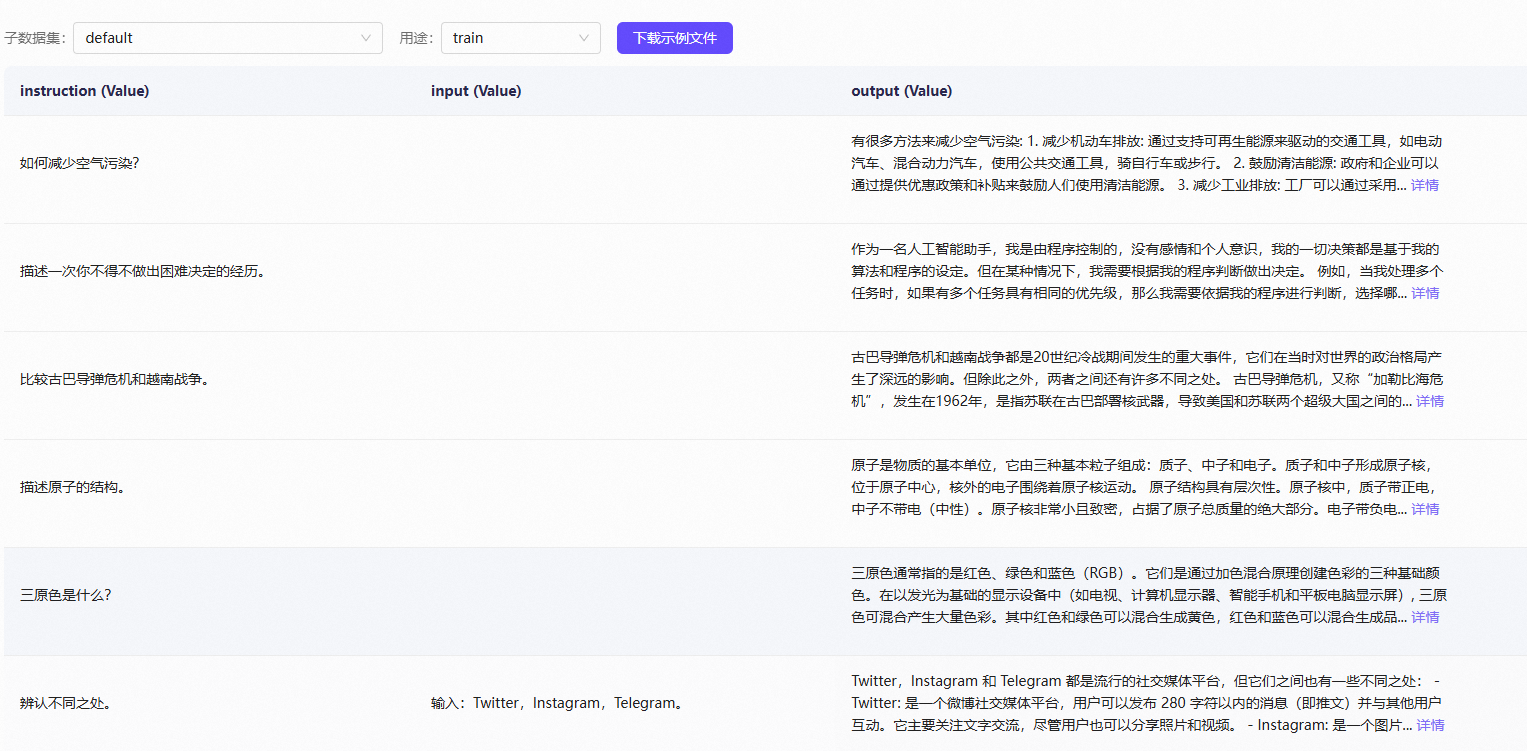
PaddleNLP支持的数据格式是每行包含一个字典,每个字典包含以下字段:
src:str, List(str), 模型的输入指令(instruction)、提示(prompt),模型应该执行的任务。tgt:str, List(str), 模型的输出。
样例数据如下:
{"src": "类型#裙*颜色#蓝色*风格#清新*图案#蝴蝶结", "tgt": "裙身处采用立体蝴蝶结装饰辅以蓝色条带点缀,令衣身造型饱满富有层次的同时为其注入一丝甜美气息。将女孩清新娇俏的一面衬托而出。"}
...因此需要对alpaca-gpt4-data-zh数据集进行处理。
您可以参考执行下面的代码:
import json
import random
def split_and_convert_json_dataset(input_file, train_output, test_output, train_paddlenlp_output, test_paddlenlp_output, ratio=0.9, seed=None):
# 设置随机种子保证可重复性
if seed is not None:
random.seed(seed)
# 读取原始JSON文件
with open(input_file, 'r', encoding='utf-8') as f:
full_data = json.load(f)
# 打乱数据顺序
random.shuffle(full_data)
# 计算分割点
split_index = int(len(full_data) * ratio)
train_data = full_data[:split_index]
test_data = full_data[split_index:]
# 保存原始格式的训练集和测试集
with open(train_output, 'w', encoding='utf-8') as f:
json.dump(train_data, f, indent=2, ensure_ascii=False)
with open(test_output, 'w', encoding='utf-8') as f:
json.dump(test_data, f, indent=2, ensure_ascii=False)
# 转换为 PaddleNLP 格式并保存
convert_alpaca_to_paddlenlp(train_data, train_paddlenlp_output)
convert_alpaca_to_paddlenlp(test_data, test_paddlenlp_output)
return len(train_data), len(test_data)
def convert_alpaca_to_paddlenlp(data, output_file):
# 初始化 PaddleNLP 格式的数据列表
paddlenlp_data = []
# 遍历每个 Alpaca 数据样本
for item in data:
# 获取字段值,设置默认值为空字符串
instruction = item.get('instruction', '')
input_text = item.get('input', '')
output = item.get('output', '')
# 如果 input 不为空,将 instruction 和 input 组合为 src
if input_text:
src = instruction + "\n" + input_text
else:
src = instruction
# 创建 PaddleNLP 格式的样本
paddlenlp_item = {
'src': src,
'tgt': output
}
paddlenlp_data.append(paddlenlp_item)
# 将转换后的数据写入新的 JSON 文件
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(paddlenlp_data, f, ensure_ascii=False, indent=4)
if __name__ == "__main__":
# 参数设置
input_json = "" # 输入数据集路径
train_json = "./datasets/alpaca_train.json" # 输出训练集路径(Alpaca 格式)
test_json = "./datasets/alpaca_dev.json" # 输出测试集路径(Alpaca 格式)
train_paddlenlp_json = "./datasets/train.json" # 输出训练集路径(PaddleNLP 格式)
test_paddlenlp_json = "./datasets/dev.json" # 输出测试集路径(PaddleNLP 格式)
split_ratio = 0.9 # 训练集比例
random_seed = 2025 # 随机种子
# 执行划分和转换
train_count, test_count = split_and_convert_json_dataset(
input_file=input_json,
train_output=train_json,
test_output=test_json,
train_paddlenlp_output=train_paddlenlp_json,
test_paddlenlp_output=test_paddlenlp_json,
ratio=split_ratio,
seed=random_seed,
)
print(f"数据集划分和转换完成!训练集:{train_count} 条,测试集:{test_count} 条")完成后,你的代码目录下会出现训练集train.jsonl和验证集dev.jsonl文件。
至此,数据集部分完成。
3. 加载模型
这里我们使用paddlenlp.transformers来下载和加载Qwen2.5-7B模型,使用从Hugging Face上面下载的模型在加载时会存在问题。
import os
from paddlenlp.transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "Qwen/Qwen2.5-7B"
cache_dir = "" # 替换为您希望的缓存目录路径
os.makedirs(cache_dir, exist_ok=True) # 确保目录存在
tokenizer = AutoTokenizer.from_pretrained(model_name, cache_dir=cache_dir)
model = AutoModelForCausalLM.from_pretrained(model_name, cache_dir=cache_dir, dtype="float16")4. 配置训练可视化工具
我们使用SwanLab来监控整个训练过程,并评估最终的模型效果。
SwanLab 是一款开源、轻量的 AI 模型训练跟踪与可视化工具,面向人工智能与深度学习开发者,提供了一个跟踪、记录、比较、和协作实验的平台,常被称为"中国版 Weights & Biases + TensorBoard"。SwanLab同时支持云端和离线使用,并适配了从PyTorch、Transformers、Lightning再到LLaMA Factory、veRL等30+ AI训练框架。
您可以参考下面的代码在paddlenlp上尝试使用swanlab:
"""
Tested on:
pip install paddlepaddle-gpu==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
pip install paddlenlp==3.0.0b4
"""
from paddlenlp.trl import SFTConfig, SFTTrainer
from datasets import load_dataset
dataset = load_dataset("ZHUI/alpaca_demo", split="train")
training_args = SFTConfig(
output_dir="Qwen/Qwen2.5-7B-SFT",
device="gpu",
per_device_train_batch_size=1,
logging_steps=20,
report_to="swanlab",
)
trainer = SFTTrainer(
args=training_args,
model="Qwen/Qwen2.5-7B",
train_dataset=dataset,
)
trainer.train()5. 完整代码
开始训练时的目录结构:
|--- configs
|--- qwen_config.json
|--- datasets
|--- train.jsonl
|--- dev.jsonl
|--- utils
|--- argument.py
|--- data.py
|--- run_finetune.pyqwen_config.json:
{
"model_name_or_path": "Qwen/Qwen2.5-7B",
"use_flash_attention": true,
"lora": true,
"lora_rank": 8,
"pissa": false,
"dataset_name_or_path": "./datasets",
"max_length": 512,
"zero_padding": false,
"output_dir": "./output",
"per_device_train_batch_size": 2,
"gradient_accumulation_steps": 1,
"per_device_eval_batch_size": 4,
"num_train_epochs": 3,
"max_steps": 2000,
"learning_rate": 1.0e-4,
"lr_scheduler_type": "cosine",
"warmup_ratio": 0.1,
"logging_steps": 2,
"evaluation_strategy": "steps",
"eval_steps": 200,
"save_strategy": "steps",
"save_steps": 200,
"load_best_model_at_end": true,
"metric_for_best_model": "eval_loss",
"save_total_limit": 1,
"seed": 2025,
"bf16": true,
"fp16_opt_level": "O2",
"disable_tqdm": true,
"eval_with_do_generation": false,
"tensor_parallel_degree": 1,
"pipeline_parallel_degree": 1,
"do_train": true,
"do_eval": true,
"use_mora": false,
"report_to": "swanlab"
}run_finetune.py:
import json
import logging
import os
import sys
from functools import partial
import paddle
from utils.argument import GenerateArgument, ReftArgument
from utils.data import convert_example_for_reft, get_convert_example
from swanlab.integration.paddlenlp import SwanLabCallback
from paddlenlp.data import DataCollatorForSeq2Seq
from paddlenlp.datasets import (
ZeroPaddingIterableDataset,
ZeroPaddingMapDataset,
load_dataset,
)
from paddlenlp.metrics import BLEU, Rouge1, Rouge2, RougeL
from paddlenlp.peft import (
LoKrConfig,
LoKrModel,
LoRAConfig,
LoRAModel,
PrefixConfig,
PrefixModelForCausalLM,
VeRAConfig,
VeRAModel,
)
from paddlenlp.peft.reft import (
ReFTConfig,
ReftDataCollator,
ReFTModel,
intervention_mapping,
)
from paddlenlp.trainer import PdArgumentParser, get_last_checkpoint, set_seed
from paddlenlp.trainer.trainer_callback import TrainerState
from paddlenlp.transformers import (
AutoConfig,
AutoModelForCausalLM,
AutoModelForCausalLMPipe,
AutoTokenizer,
DeepseekV2ForCausalLM,
DeepseekV2ForCausalLMPipe,
DeepseekV3ForCausalLM,
DeepseekV3ForCausalLMPipe,
Llama3Tokenizer,
LlamaForCausalLM,
LlamaForCausalLMPipe,
LlamaTokenizer,
Qwen2ForCausalLM,
Qwen2ForCausalLMPipe,
Qwen2MoeForCausalLM,
Qwen2MoeForCausalLMPipe,
)
from paddlenlp.transformers.configuration_utils import LlmMetaConfig
from paddlenlp.transformers.longlora import replace_llama_attn, set_group_size
from paddlenlp.trl import DataConfig, ModelConfig, SFTConfig, SFTTrainer
from paddlenlp.trl.llm_utils import (
ZeroPaddingIterDatasetCallback,
compute_metrics,
get_lora_target_modules,
get_prefix_tuning_params,
init_chat_template,
)
from paddlenlp.utils.log import logger
from paddlenlp.utils.tools import get_env_device
# Fine-tune Environment Variables to support sharding stage1 overlap optimization.
os.environ["USE_CASUAL_MASK"] = "False"
flash_mask_support_list = [
DeepseekV2ForCausalLM,
DeepseekV2ForCausalLMPipe,
DeepseekV3ForCausalLM,
DeepseekV3ForCausalLMPipe,
LlamaForCausalLM,
LlamaForCausalLMPipe,
Qwen2ForCausalLM,
Qwen2ForCausalLMPipe,
Qwen2MoeForCausalLM,
Qwen2MoeForCausalLMPipe,
]
def paddlenlp_verison_check():
import paddlenlp
from paddlenlp.utils.tools import compare_version
if not compare_version(paddlenlp.__version__, "3.0.0.b2"):
raise ValueError(
"This scripts require paddlenlp >= 3.0.0b3, please reinstall: pip install paddlenlp >= 3.0.0b3 "
)
def main():
paddlenlp_verison_check()
parser = PdArgumentParser((GenerateArgument, ModelConfig, ReftArgument, DataConfig, SFTConfig))
if len(sys.argv) >= 2 and sys.argv[1].endswith(".json"):
gen_args, model_args, reft_args, data_args, training_args = parser.parse_json_file_and_cmd_lines()
elif len(sys.argv) >= 2 and sys.argv[1].endswith(".yaml"):
gen_args, model_args, reft_args, data_args, training_arg = parser.parse_yaml_file_and_cmd_lines()
else:
gen_args, model_args, reft_args, data_args, training_args = parser.parse_args_into_dataclasses()
training_args.print_config(model_args, "Model")
training_args.print_config(data_args, "Data")
training_args.print_config(gen_args, "Generation")
# Setup GPU & distributed training
paddle.set_device(training_args.device)
set_seed(seed=training_args.seed)
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, world_size: {training_args.world_size}, "
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16 or training_args.bf16}"
)
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
if get_env_device() == "xpu" and training_args.gradient_accumulation_steps > 1:
try:
from paddle_xpu.layers.nn.linear import LinearConfig # noqa: F401
LinearConfig.enable_accumulate_steps_opt()
LinearConfig.set_accumulate_steps(training_args.gradient_accumulation_steps)
except ImportError:
# It's OK, not use accumulate_steps optimization
pass
# Load model
if training_args.fp16_opt_level == "O2":
if training_args.fp16:
dtype = "float16"
elif training_args.bf16:
dtype = "bfloat16"
else:
raise ValueError("Please specific dtype: --fp16 or --bf16")
else:
dtype = "float32"
model_config = AutoConfig.from_pretrained(
model_args.model_name_or_path,
dtype=dtype,
from_aistudio=model_args.from_aistudio,
# quantization_config=quantization_config,
)
if training_args.use_ssa:
assert (
training_args.ssa_group_size_ratio is not None
), "ssa_group_size_ratio must be specified when use_ssa is True"
set_group_size(training_args.ssa_group_size_ratio)
replace_llama_attn()
architectures_to_check = {"Qwen2Moe", "DeepseekV2", "DeepseekV3"}
if (
any(architecture in str(model_config.architectures) for architecture in architectures_to_check)
and training_args.data_parallel_degree > 1
and not training_args.use_expert_parallel
):
raise ValueError("Please set use_expert_parallel to true in expert parallel mode.")
# (Liuting) Not support acc calculation now due to MTP.
if "DeepseekV3" in str(model_config.architectures):
training_args.prediction_loss_only = True
LlmMetaConfig.set_llm_config(model_config, training_args)
model_config.use_fast_layer_norm = model_args.use_fast_layer_norm
# Config for model using dropout, such as GPT.
if hasattr(model_config, "hidden_dropout_prob"):
model_config.hidden_dropout_prob = model_args.hidden_dropout_prob
if hasattr(model_config, "attention_probs_dropout_prob"):
model_config.attention_probs_dropout_prob = model_args.attention_probs_dropout_prob
if hasattr(model_config, "ignore_index"):
model_config.ignore_index = -100
if model_args.fuse_attention_qkv is not None:
model_config.fuse_attention_qkv = model_args.fuse_attention_qkv
if model_args.fuse_attention_ffn is not None:
model_config.fuse_attention_ffn = model_args.fuse_attention_ffn
model_config.seq_length = data_args.max_length
# Config for model using long sequence strategy
if model_args.use_long_sequence_strategies:
scaled_max_length = (
int(data_args.max_length * model_args.rope_scaling_factor)
if data_args.use_pose_convert
else data_args.max_length
)
data_args.scaled_max_length = int(data_args.max_length * model_args.rope_scaling_factor)
model_config.use_long_sequence_strategies = True
model_config.long_sequence_strategy_type = model_args.strategy_type
model_config.long_sequence_strategy_name = model_args.strategy_name
model_config.rope_scaling_factor = model_args.rope_scaling_factor
model_config.long_sequence_init_args = {
"dim": int(model_config.hidden_size / model_config.num_attention_heads),
"max_position_embeddings": scaled_max_length, # extended context window
"base": model_config.rope_theta,
"scaling_factor": model_args.rope_scaling_factor,
}
if model_args.strategy_name == "YaRNScalingRotaryEmbedding":
model_config.long_sequence_init_args["original_max_position_embeddings"] = data_args.max_length
logger.info(f"Final model config: {model_config}")
logger.info("Creating model")
model_class = AutoModelForCausalLM
if training_args.pipeline_parallel_degree > 1:
if data_args.eval_with_do_generation and training_args.do_eval:
raise ValueError("Please set eval_with_do_generation to false in pipeline parallel mode.")
model_class = AutoModelForCausalLMPipe
if model_args.continue_training and not training_args.autotuner_benchmark:
model = model_class.from_pretrained(
model_args.model_name_or_path,
config=model_config,
from_aistudio=model_args.from_aistudio,
)
else:
# NOTE(gongenlei): new add autotuner_benchmark
model = model_class.from_config(model_config, dtype=dtype)
if model_args.flash_mask and (not data_args.zero_padding or not model.config.use_flash_attention):
logger.warning("`flash_mask` must use with zero padding and flash attention.")
data_args.zero_padding = True
model.config.use_flash_attention = True
if model_args.flash_mask and not any(isinstance(model, cls) for cls in flash_mask_support_list):
raise NotImplementedError(f"{model.__class__} not support flash mask.")
if training_args.do_train and model_args.neftune:
# Inspired by https://github.com/neelsjain/NEFTune
if hasattr(model, "get_input_embeddings"):
def neft_post_hook(module, input, output):
if module.training:
mag_norm = model_args.neftune_noise_alpha / paddle.sqrt(
paddle.to_tensor(output.shape[0] * output.shape[1], dtype="float32")
)
output = output + paddle.uniform(
shape=output.shape, dtype=output.dtype, min=-mag_norm, max=mag_norm
)
return output
neft_post_hook_handle = model.get_input_embeddings().register_forward_post_hook(neft_post_hook)
else:
raise NotImplementedError("Only support neftune for model with get_input_embeddings")
# Load tokenizer & dataset
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, from_aistudio=model_args.from_aistudio)
reft_layers = None
if model_args.reft:
# reft requires padding side right
tokenizer.padding_side = "right"
layers = reft_args.layers
if reft_args.layers != "all":
layers = [int(l) for l in layers.split(";")]
else:
layers = [l for l in range(model_config.num_hidden_layers)]
reft_layers = layers
logging.info("Using ReFT with layers: ", reft_layers)
# init chat_template for tokenizer
init_chat_template(tokenizer, model_args.model_name_or_path, data_args.chat_template)
# if using chat_template, data_args.eval_with_do_generation must be false
if tokenizer.chat_template is not None:
data_args.eval_with_do_generation = False
if isinstance(tokenizer, LlamaTokenizer) or isinstance(tokenizer, Llama3Tokenizer):
tokenizer.pad_token_id = tokenizer.eos_token_id
train_ds, dev_ds, test_ds = create_dataset(data_args, training_args)
# TODO(ZHUI & sijunhe): Temporary implementation. Generalize this logic and move to Trainer later.
if training_args.resume_from_checkpoint is not None and data_args.lazy:
logger.info(
f"Loading from '{training_args.resume_from_checkpoint}' with `lazy=True`, manually skipping dataset and setting `ignore_data_skip` to True."
)
training_args.ignore_data_skip = True
state = TrainerState.load_from_json(os.path.join(training_args.resume_from_checkpoint, "trainer_state.json"))
if state.trial_params is not None and "zero_padding_global_step" in state.trial_params:
consumed_samples = state.trial_params["zero_padding_global_step"]
else:
consumed_samples = (
state.global_step
* training_args.per_device_train_batch_size
* training_args.gradient_accumulation_steps
* training_args.dataset_world_size
)
logger.info(
f"Skipping the first {consumed_samples} samples to warmup the dataset from checkpoint '{training_args.resume_from_checkpoint}'."
)
train_ds = train_ds.skip(consumed_samples)
if training_args.pipeline_parallel_degree > 1:
from utils.data import convert_example_common
trans_func = partial(convert_example_common, tokenizer=tokenizer, data_args=data_args)
elif model_args.reft:
trans_func = partial(
convert_example_for_reft,
tokenizer=tokenizer,
data_args=data_args,
positions=reft_args.position,
num_interventions=len(reft_layers),
)
else:
trans_func = partial(get_convert_example(model), tokenizer=tokenizer, data_args=data_args)
eval_zero_padding = data_args.zero_padding
if data_args.zero_padding and data_args.eval_with_do_generation:
logger.warning(
"`zero_padding` conflicts with `eval_with_do_generation`. Setting zero_padding to False for the eval_dataset."
)
eval_zero_padding = False
logger.info("Trans the dataset text into token ids, please wait for a moment.")
train_ds, dev_ds, test_ds = trans_dataset_to_ids(
train_ds, dev_ds, test_ds, model_args, data_args, trans_func, eval_zero_padding
)
if data_args.zero_padding:
if data_args.lazy:
intoken_dataset = ZeroPaddingIterableDataset
else:
intoken_dataset = ZeroPaddingMapDataset
logger.info("Creating Zero Padding Data Stream. This may take a few minutes.")
if train_ds is not None:
train_ds = intoken_dataset(
train_ds,
tokenizer=tokenizer,
max_length=data_args.max_length,
greedy_zero_padding=data_args.greedy_zero_padding,
)
if eval_zero_padding and dev_ds is not None:
dev_ds = intoken_dataset(dev_ds, tokenizer=tokenizer, max_length=data_args.max_length)
if eval_zero_padding and test_ds is not None:
test_ds = intoken_dataset(test_ds, tokenizer=tokenizer, max_length=data_args.max_length)
model = create_peft_model(model_args, reft_args, training_args, dtype, model_config, model, reft_layers)
def compute_metrics_do_generation(eval_preds):
rouge1 = Rouge1()
rouge2 = Rouge2()
rougel = RougeL()
bleu4 = BLEU(n_size=4)
predictions = [x[x != -100].tolist() for x in eval_preds.predictions]
references = [x[x != -100].tolist() for x in eval_preds.label_ids]
predictions = tokenizer.batch_decode(predictions, skip_special_tokens=True, clean_up_tokenization_spaces=False)
references = tokenizer.batch_decode(references, skip_special_tokens=True, clean_up_tokenization_spaces=False)
if data_args.save_generation_output:
with open(os.path.join(training_args.output_dir, "generated_output.json"), "w", encoding="utf-8") as f:
for pred, ref in zip(predictions, references):
out = {"output": pred, "tgt": ref}
f.write(json.dumps(out, ensure_ascii=False) + "\n")
# for pred in predictions:
rouge1_score = rouge1.score(predictions, references)
rouge2_score = rouge2.score(predictions, references)
for pred, ref in zip(predictions, references):
rougel.add_inst(pred, [ref])
bleu4.add_inst(pred, [ref])
return {
"rouge1": rouge1_score,
"rouge2": rouge2_score,
"rougel": rougel.score(),
"bleu4": bleu4.score(),
}
# Create trainer
if (
training_args.pipeline_parallel_degree > 1
or training_args.sequence_parallel
or training_args.autotuner_benchmark
or data_args.zero_padding
or data_args.pad_to_max_length
):
# NOTE(gongenlei): new add autotuner_benchmark
max_length = data_args.max_length
padding = "max_length"
else:
max_length = None
padding = True
if training_args.pipeline_parallel_degree > 1:
metrics = None
elif data_args.eval_with_do_generation:
metrics = compute_metrics_do_generation
else:
metrics = compute_metrics
data_collator_fn = DataCollatorForSeq2Seq(
tokenizer=tokenizer,
max_length=max_length,
padding=padding,
max_label_length=max_length,
return_tensors="np",
return_attention_mask=not model_args.flash_mask,
pad_to_multiple_of=data_args.pad_to_multiple_of,
)
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=train_ds,
eval_dataset=dev_ds,
tokenizer=tokenizer,
compute_metrics=metrics,
data_collator=data_collator_fn if not model_args.reft else ReftDataCollator(data_collator=data_collator_fn),
do_generation=data_args.eval_with_do_generation,
callbacks=[ZeroPaddingIterDatasetCallback()] if isinstance(train_ds, ZeroPaddingIterableDataset) else None,
gen_args=gen_args,
data_args=data_args,
)
trainable_parameters = [p for p in model.parameters() if not p.stop_gradient]
trainer.set_optimizer_grouped_parameters(trainable_parameters)
# Train
if training_args.do_train:
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
if model_args.neftune:
neft_post_hook_handle.remove()
if training_args.benchmark:
total_effective_tokens = (
sum([len(i["input_ids"]) for i in trainer.train_dataset]) * train_result.metrics["progress_or_epoch"]
)
effective_tokens_per_second = total_effective_tokens / train_result.metrics["train_runtime"]
logger.info(f"Effective_Tokens_per_second: {effective_tokens_per_second} ")
logger.info("Benchmark done.")
else:
if model_args.save_to_aistudio:
save_to_aistudio(model_args, training_args, trainer)
if not training_args.autotuner_benchmark:
trainer.save_model(merge_tensor_parallel=training_args.tensor_parallel_degree > 1)
trainer.log_metrics("train", train_result.metrics)
trainer.save_metrics("train", train_result.metrics)
trainer.save_state()
# Evaluation test set
if training_args.do_predict:
eval_result = trainer.predict(test_ds).metrics
trainer.log_metrics("test", eval_result)
# Evaluation dev set
if training_args.do_eval:
logger.info("*** Evaluate result after train ***")
eval_result = trainer.evaluate(dev_ds)
trainer.log_metrics("eval", eval_result)
def save_to_aistudio(model_args, training_args, trainer):
kwargs = {}
if model_args.aistudio_token is not None:
kwargs["token"] = model_args.aistudio_token
# PEFT Model only save PEFT parameters, if pretrained model obtains from aistudio
if model_args.from_aistudio and (model_args.lora or model_args.prefix_tuning):
kwargs["base_model"] = model_args.model_name_or_path
else:
trainer.tokenizer.save_to_aistudio(
repo_id=model_args.aistudio_repo_id,
private=model_args.aistudio_repo_private,
license=model_args.aistudio_repo_license,
exist_ok=True,
**kwargs,
)
trainer.model.save_to_aistudio(
repo_id=model_args.aistudio_repo_id,
private=model_args.aistudio_repo_private,
license=model_args.aistudio_repo_license,
merge_tensor_parallel=training_args.tensor_parallel_degree > 1,
exist_ok=True,
**kwargs,
)
def create_peft_model(model_args, reft_args, training_args, dtype, model_config, model, reft_layers):
if model_args.prefix_tuning:
if training_args.pipeline_parallel_degree > 1:
raise NotImplementedError("Prefix tuning is not implemented for pipeline parallelism.")
prefix_tuning_params = get_prefix_tuning_params(model)
prefix_config = PrefixConfig(
num_prefix_tokens=model_args.num_prefix_tokens,
num_attention_heads=prefix_tuning_params["num_attention_heads"],
num_hidden_layers=prefix_tuning_params["num_hidden_layers"],
hidden_size=prefix_tuning_params["hidden_size"],
multi_query_group_num=prefix_tuning_params["multi_query_group_num"],
dtype=dtype,
)
if model_args.prefix_path is None:
model = PrefixModelForCausalLM(
model=model,
prefix_config=prefix_config,
postprocess_past_key_value=prefix_tuning_params["postprocess_past_key_value"],
)
else:
model = PrefixModelForCausalLM.from_pretrained(
model=model,
prefix_path=model_args.prefix_path,
postprocess_past_key_value=prefix_tuning_params["postprocess_past_key_value"],
)
model.print_trainable_parameters()
if model_args.lora:
if training_args.sharding_parallel_degree > 1:
assert (
"enable_stage1_overlap" not in training_args.sharding_parallel_config
), "Currently not support enabling sharding_stage1_overlap in lora mode."
if model_args.lora_path is None:
target_modules = get_lora_target_modules(model)
lora_config = LoRAConfig(
target_modules=target_modules,
r=model_args.lora_rank,
lora_alpha=4 * model_args.lora_rank if not model_args.rslora else 4,
rslora=model_args.rslora,
lora_plus_scale=model_args.lora_plus_scale,
pissa=model_args.pissa,
merge_weights=False,
tensor_parallel_degree=training_args.tensor_parallel_degree,
dtype=dtype,
base_model_name_or_path=model_args.model_name_or_path,
use_quick_lora=model_args.use_quick_lora,
lora_use_mixer=model_args.lora_use_mixer,
use_mora=model_args.use_mora,
lora_dropout=0.1
)
model = LoRAModel(model, lora_config)
else:
model = LoRAModel.from_pretrained(model=model, lora_path=model_args.lora_path)
model.print_trainable_parameters()
if model_args.lokr:
if model_args.lokr_path is None:
target_modules = get_lora_target_modules(model)
lokr_config = LoKrConfig(
target_modules=target_modules,
lokr_dim=model_args.lokr_dim,
dtype=dtype,
base_model_name_or_path=model_args.model_name_or_path,
)
model = LoKrModel(model, lokr_config)
else:
model = LoKrModel.from_pretrained(model=model, lokr_path=model_args.lokr_path)
if model_args.reft:
intervention_dtype = dtype
intervention_params = {
"embed_dim": model_config.hidden_size,
"low_rank_dimension": reft_args.rank,
"dropout": reft_args.dropout,
"dtype": intervention_dtype,
"act_fn": reft_args.act_fn,
"device": "gpu",
"add_bias": reft_args.add_bias,
}
representations = [
{
"layer": l,
"component": "block_output",
"low_rank_dimension": reft_args.rank,
"intervention": intervention_mapping[reft_args.intervention_type](**intervention_params),
}
for l in reft_layers
]
reft_config = ReFTConfig(
representations=representations, intervention_params=intervention_params, position=reft_args.position
)
# get reft model
model = ReFTModel(reft_config, model)
# disable original model gradients
model.disable_model_gradients()
model.print_trainable_parameters()
if model_args.vera:
target_modules = get_lora_target_modules(model)
vera_config = VeRAConfig(
target_modules=target_modules,
r=model_args.vera_rank,
vera_alpha=model_args.vera_rank,
dtype=dtype,
base_model_name_or_path=model_args.model_name_or_path,
pissa_init=True,
)
model = VeRAModel(model, vera_config)
model.mark_only_vera_as_trainable(notfreezeB=True)
model.print_trainable_parameters()
return model
def trans_dataset_to_ids(train_ds, dev_ds, test_ds, model_args, data_args, trans_func, eval_zero_padding):
if train_ds is not None:
train_ds = train_ds.map(
partial(
trans_func,
is_test=False,
zero_padding=data_args.zero_padding,
flash_mask=model_args.flash_mask,
)
)
if dev_ds is not None:
dev_ds = dev_ds.map(
partial(
trans_func,
is_test=data_args.eval_with_do_generation,
zero_padding=eval_zero_padding,
flash_mask=model_args.flash_mask,
)
)
if test_ds is not None:
test_ds = test_ds.map(partial(trans_func, is_test=data_args.eval_with_do_generation))
return train_ds, dev_ds, test_ds
def create_dataset(data_args, training_args):
if data_args.dataset_name_or_path is None:
raise ValueError(f"Please specific dataset name or path (got {data_args.dataset_name_or_path})")
train_ds = None
dev_ds = None
test_ds = None
if os.path.exists(os.path.join(data_args.dataset_name_or_path, "train.json")) or os.path.exists(
os.path.join(data_args.dataset_name_or_path, "dev.json")
):
logger.info("load train")
if training_args.do_train:
train_ds = load_dataset(
"json",
data_files=os.path.join(data_args.dataset_name_or_path, "train.json"),
lazy=data_args.lazy,
)[0]
logger.info("load eval")
if training_args.do_eval:
dev_ds = load_dataset(
"json",
data_files=os.path.join(data_args.dataset_name_or_path, "dev.json"),
lazy=data_args.lazy,
)[0]
logger.info("load test")
if training_args.do_predict:
test_ds = load_dataset(
"json",
data_files=os.path.join(data_args.dataset_name_or_path, "test.json"),
lazy=data_args.lazy,
)[0]
elif os.path.exists(os.path.join(data_args.dataset_name_or_path, "train")) or os.path.exists(
os.path.join(data_args.dataset_name_or_path, "dev")
):
import glob
if training_args.do_train:
train_ds = load_dataset(
"json",
data_files=glob.glob(os.path.join(data_args.dataset_name_or_path, "train", "*.json")),
lazy=data_args.lazy,
)[0]
if training_args.do_eval:
dev_ds = load_dataset(
"json",
data_files=glob.glob(os.path.join(data_args.dataset_name_or_path, "dev", "*.json")),
lazy=data_args.lazy,
)[0]
if training_args.do_predict:
test_ds = load_dataset(
"json",
data_files=glob.glob(os.path.join(data_args.dataset_name_or_path, "test", "*.json")),
lazy=data_args.lazy,
)[0]
else:
if training_args.do_train:
train_ds = load_dataset(data_args.dataset_name_or_path, splits=["train"])[0]
if training_args.do_eval:
dev_ds = load_dataset(data_args.dataset_name_or_path, splits=["dev"])[0]
if training_args.do_predict:
test_ds = load_dataset(data_args.dataset_name_or_path, splits=["test"])[0]
return train_ds, dev_ds, test_ds
if __name__ == "__main__":
main()上面的代码参考PaddleNLP提供的微调代码并进行修改,其他相关的代码可以在PaddleNLP-FINETUNE项目中找到。
看到下面的信息即代表训练开始:
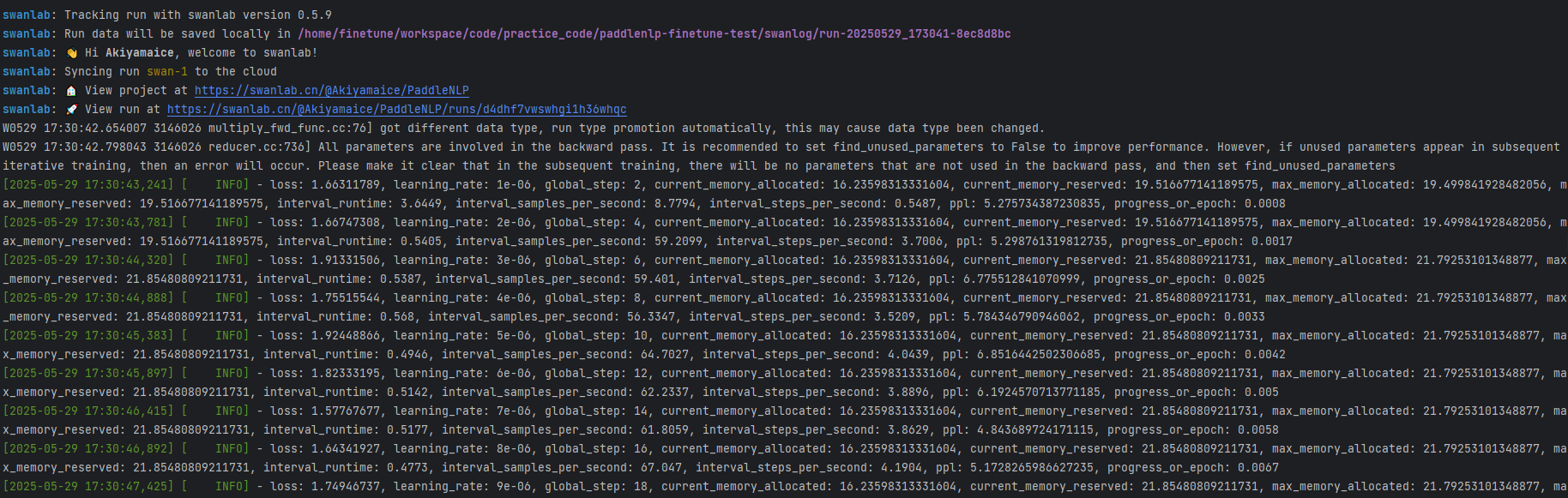
6. 训练结果演示
使用SwanLab查看最终的训练结果:
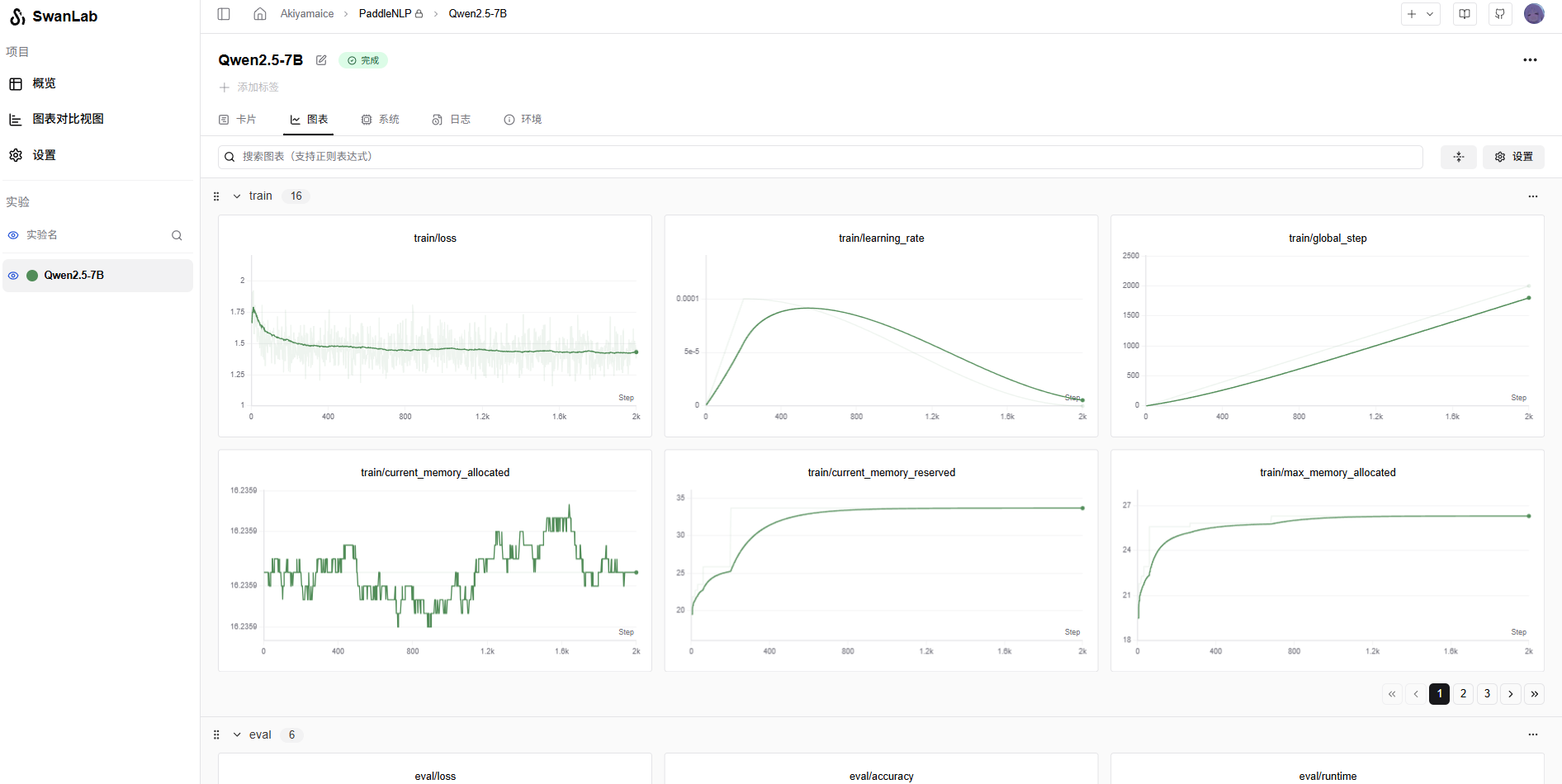
至此,使用PaddleNLP进行大模型的微调已经完成。
相关链接
- 代码:PaddleNLP-FINETUNE
- 实验日志过程:训练日志
- 模型:Qwen2.5-7B
- 数据集:alpaca-gpt4-data-zh
- SwanLab:https://swanlab.cn