玩转扩散语言模型——教你学会如何用LLaDA模型做训练任务
作者信息:情感机器实验室研究员-李馨雨
邮箱:wind.340171@gmail.com
📚资料
- 代码:llada-npu
- 数据集:C4(pretrain),alpaca(sft)
- 模型:llada-8b
- 框架:dllm
- SwanLab:llada-swanlab
本教程基于昇腾910B3-64GB复现LLaDA模型的训练,代码使用dllm框架。框架中有完整的llada模型预训练以及微调方法,在此感谢作者开源的diffusion模型训练框架🙏。
✍️ 写在前面
在我们的印象中,语言是离散的,所以适合用自回归模型来生成;而图像是连续的,所以适合用扩散模型来生成。
在生成模型发展早期,这种刻板印象广泛存在于很多研究者的脑海中。但最近,这种印象正被打破。更多的研究者开始探索在图像生成中引入自回归(如 GPT-4o),在语言生成中引入扩散。
以迭代去噪为核心的扩散模型正在迅速崛起,二者性能相当,逐渐成为重要的生成范式。其通过逐步添加和去除噪声来生成数据,在图像、音频甚至跨模态任务上展现出卓越能力。
举几个例子:Dream-7B、LLaDA-8B、openPangu-R-7B-Diffusion等等
1. 在数据受限场景下表现更稳健
当我们难以获取足够多的高质量训练数据时,扩散模型通过在训练过程中对 tokens 进行随机掩码,实现隐式的数据增强。这有助于模型更全面地理解每个 token 的语义,提升泛化能力。
2. 推理过程具备纠错与容错能力
得益于双向生成机制,扩散模型在推理时能够动态调整生成路径,避免像自回归模型那样一旦出现错误即持续累积的情况。这一特点不仅提高了生成结果的可靠性,也减少了因错误路径导致的无效计算,从而提升推理效率。
Dream-7B
香港大学和华为诺亚方舟实验室的一项研究就是其中之一。他们发布的扩散推理模型Dream 7B拿下了开源扩散语言模型的新SOTA,在各方面都大幅超越现有的扩散语言模型。
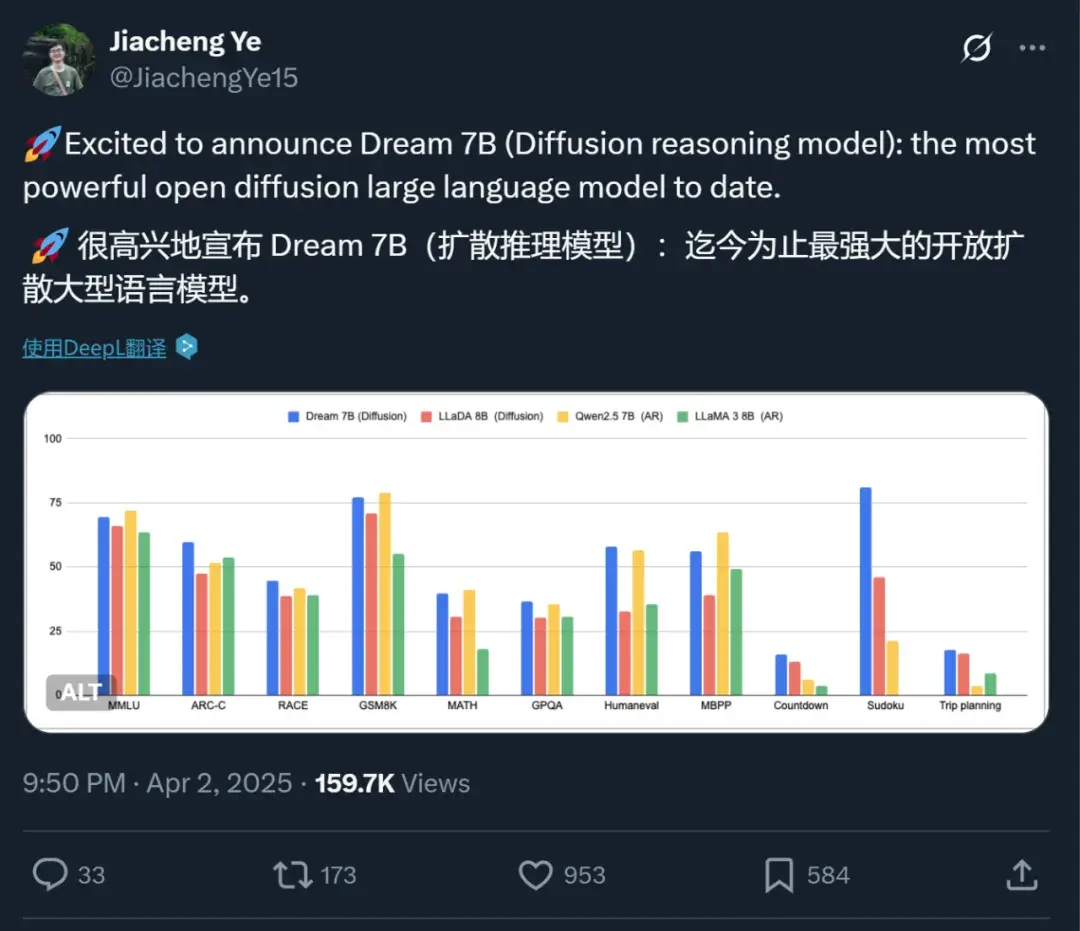
在通用能力、数学推理和编程任务上,这个模型展现出了与同等规模顶尖自回归模型(Qwen2.5 7B、LLaMA3 8B)相媲美的卓越性能,在某些情况下甚至优于最新的 Deepseek V3 671B(0324)。
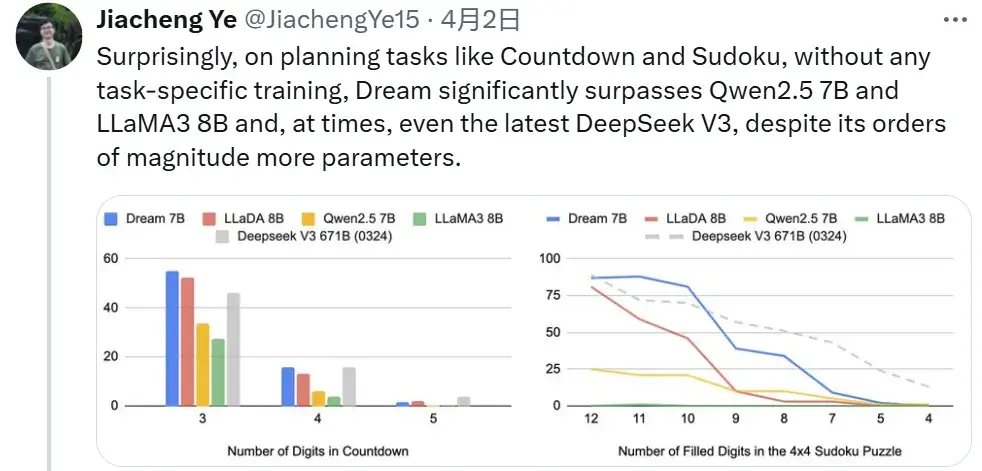
同时,它还在规划能力和推理灵活性方面表现出独特优势,彰显了扩散建模在自然语言处理领域的广阔前景。
LLaDA-8B
人大高瓴人工智能研究院、蚂蚁共同提出LLaDA(a Large Language Diffusion with mAsking)。
LLaDA-8B在上下文学习方面与LLaMA3-8B能力相当,而且在反转诗歌任务中超越GPT-4o。
在大语言模型领域,反转诗歌是一个特殊任务,它用来评估模型在处理语言模型的双向依赖关系和逻辑推理能力。
比如让大模型写出“一行白鹭上青天”的上一句。
通常情况,自回归模型(如GPT)根据下文推断上文的表现上总是不够好。这是因为自回归模型的原理就是利用序列中前面的元素来预测当前元素,即预测下一个token。
而LLaDA是基于扩散模型的双向模型,天然能够更好捕捉文本的双向依赖关系。
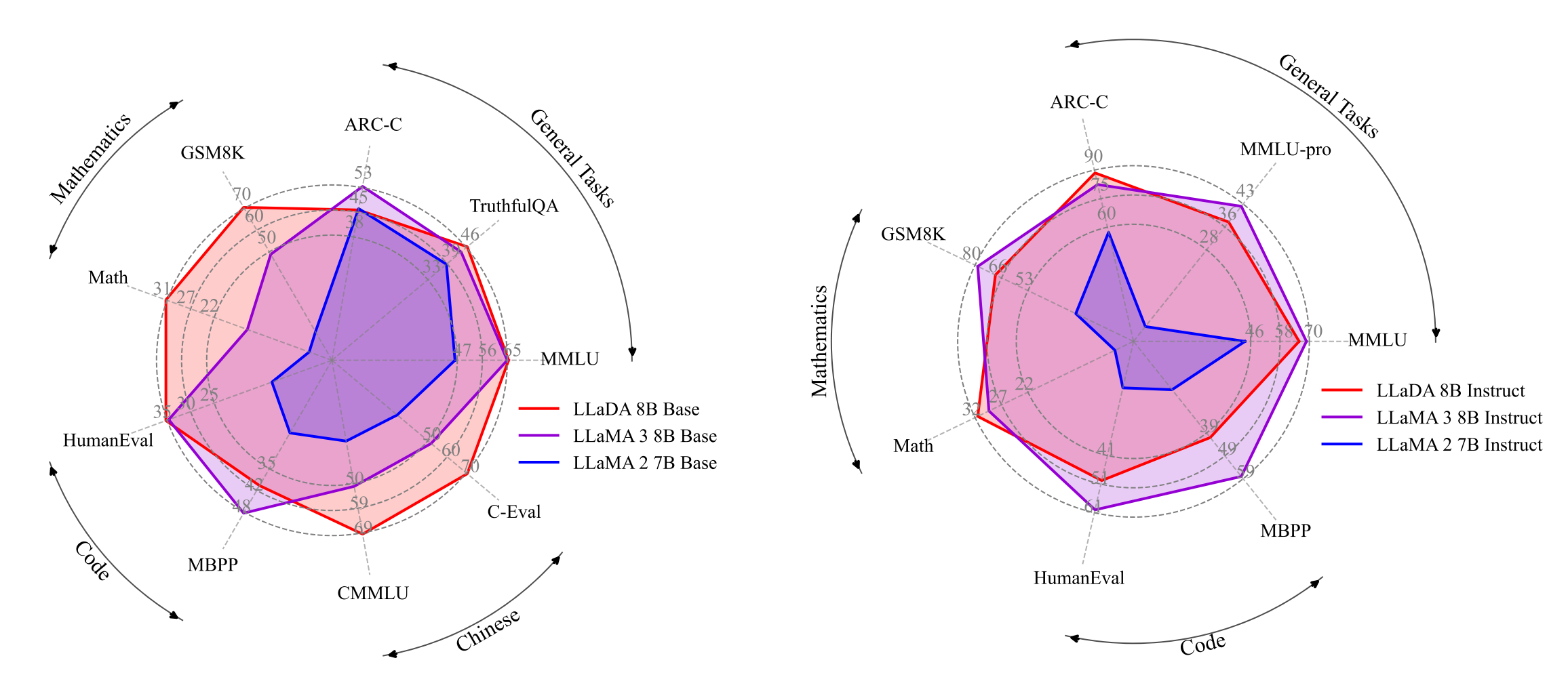
在语言理解、数学、代码和中文等多样化任务中,表现如下:
强大可扩展性:LLaDA 能够有效扩展到10²³ FLOPs计算资源上,在六个任务(例如MMLU和GSM8K)上,与在相同数据上训练的自建自回归基线模型结果相当。
上下文学习:值得注意的是,LLaDA-8B 在几乎所有 15 个标准的零样本/少样本学习任务上都超越了 LLaMA2-7B,并且与 LLaMA3-8B表现相当。
指令遵循:LLaDA在SFT后显著增强了指令遵循能力,这在多轮对话等案例研究中得到了展示。
反转推理:LLaDA有效地打破了反转诅咒,在正向和反转任务上表现一致。特别是在反转诗歌完成任务中,LLaDA 的表现优于 GPT-4o。
LLaDA使用Transformer架构作为掩码预测器。与自回归模型不同,LLaDA的transformer不使用因果掩码(Causal Mask),因此它可以同时看到输入序列中的所有token。
模型参数量与传统大语言模型(如GPT)相当,但架构细节(如多头注意力的设置)略有不同,以适应掩码预测任务。
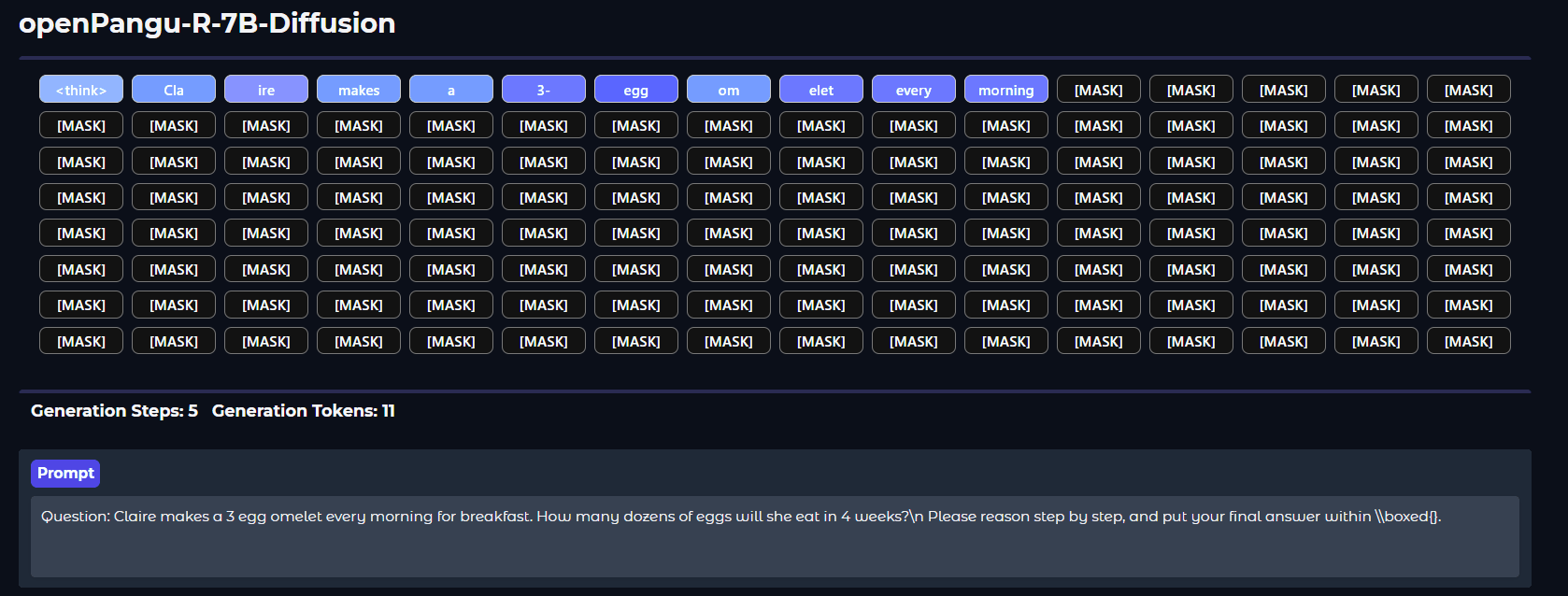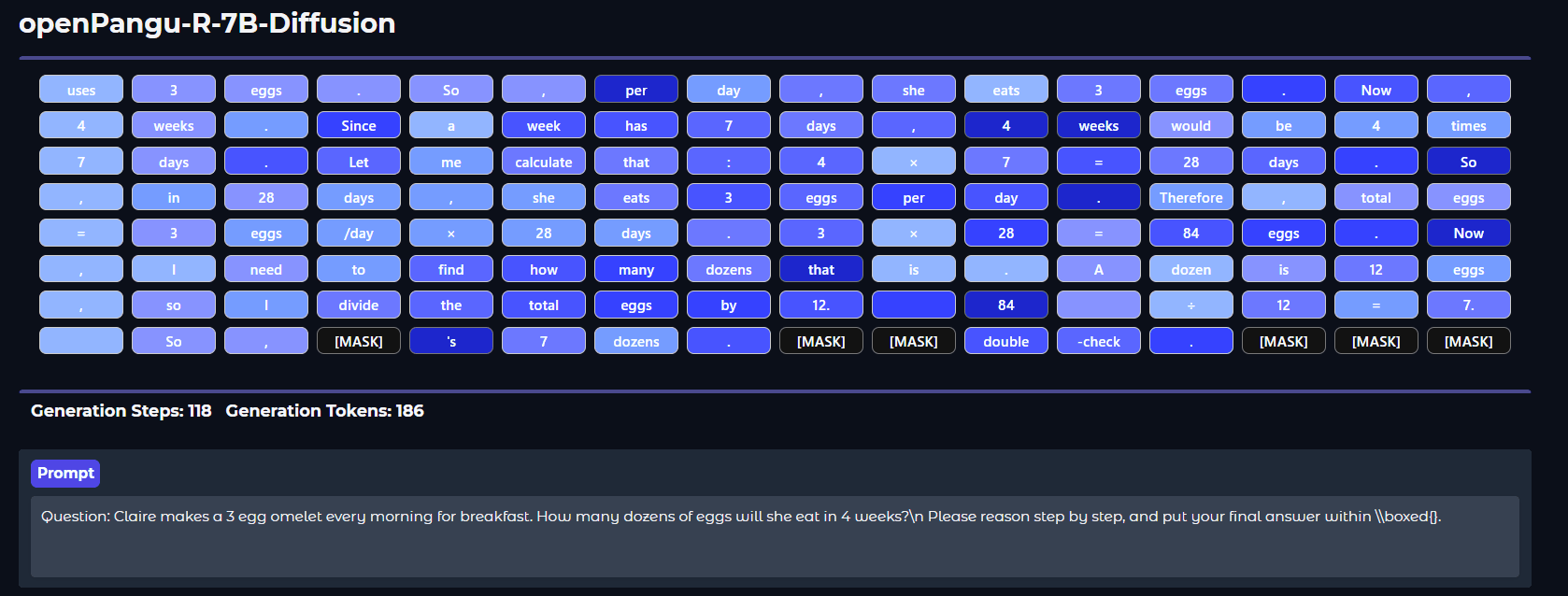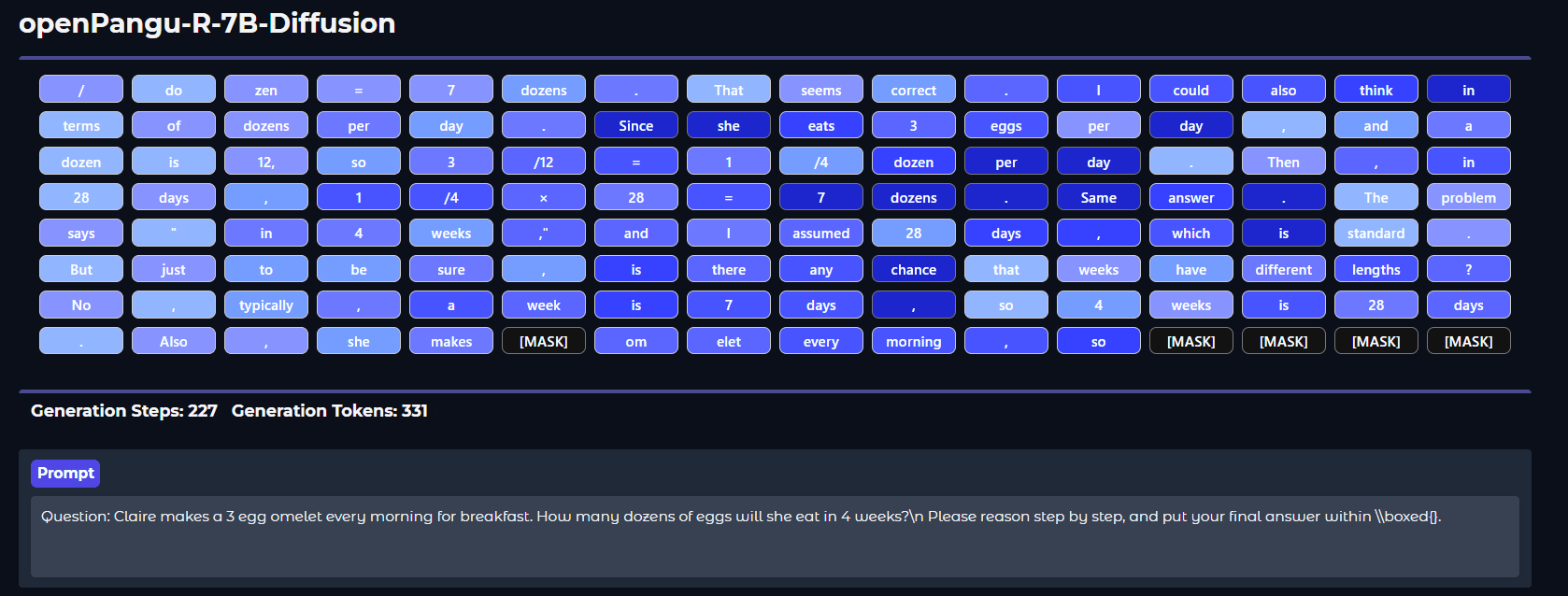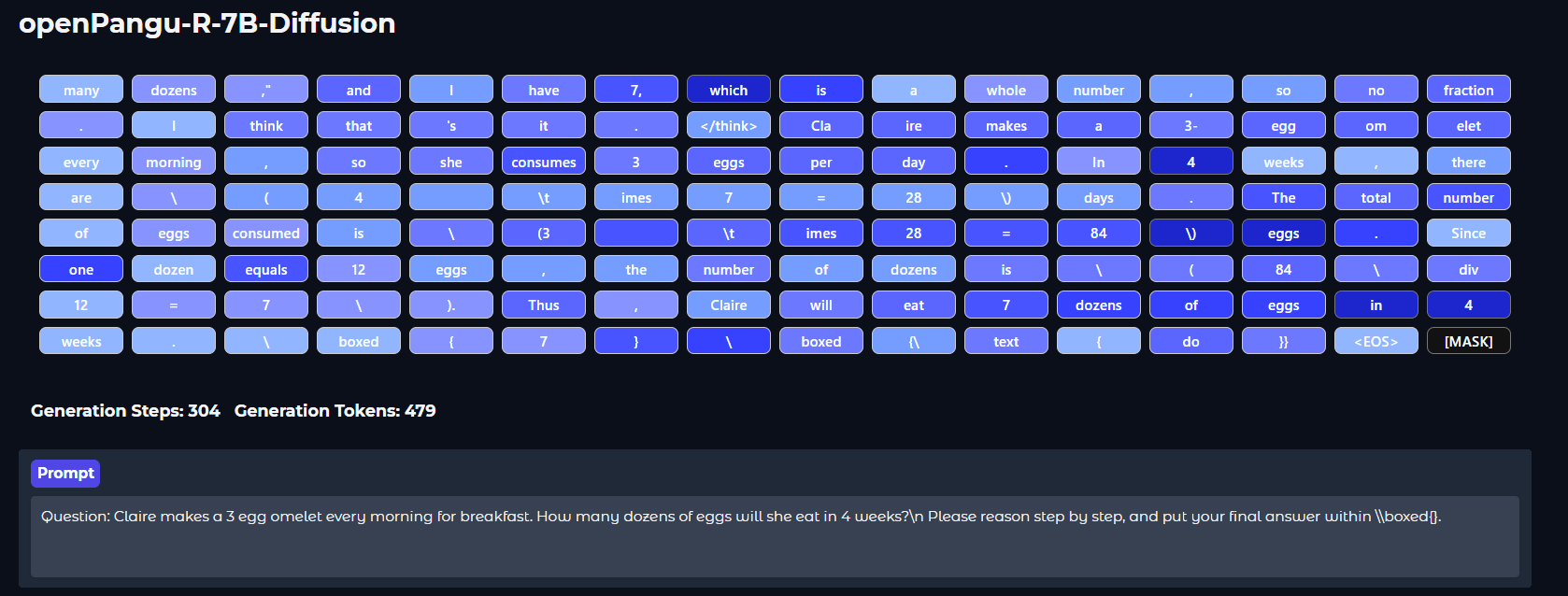
openPangu-R-7B-Diffusion
华为近日正式发布openPangu-R-7B-Diffusion,基于openPangu-Embedded-7B进行少量数据(800B tokens)续训练,成功将扩散语言模型的上下文长度扩展至 32K。
在「慢思考」能力的加持下,该模型在多个权威基准中创下了 7B 参数量级的全新 SOTA 纪录:
多学科知识(MMLU-Pro):超越 16B 参数量的 LLaDA 2.0-mini-preview 22%。数学推理(MATH):得分 84.26,大幅领先同类模型。代码生成(MBPP):得分 84.05,展现出卓越的逻辑泛化能力。
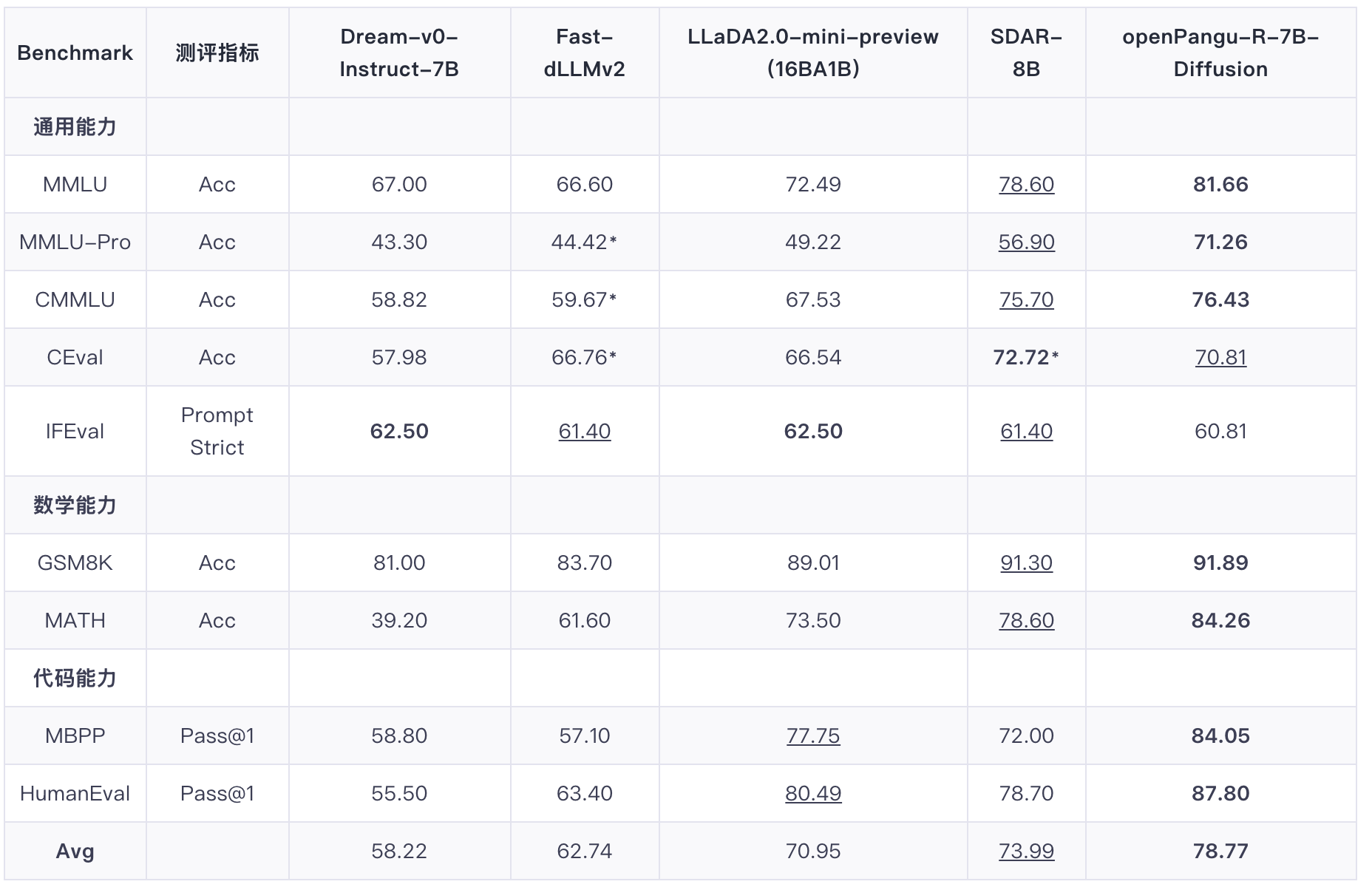
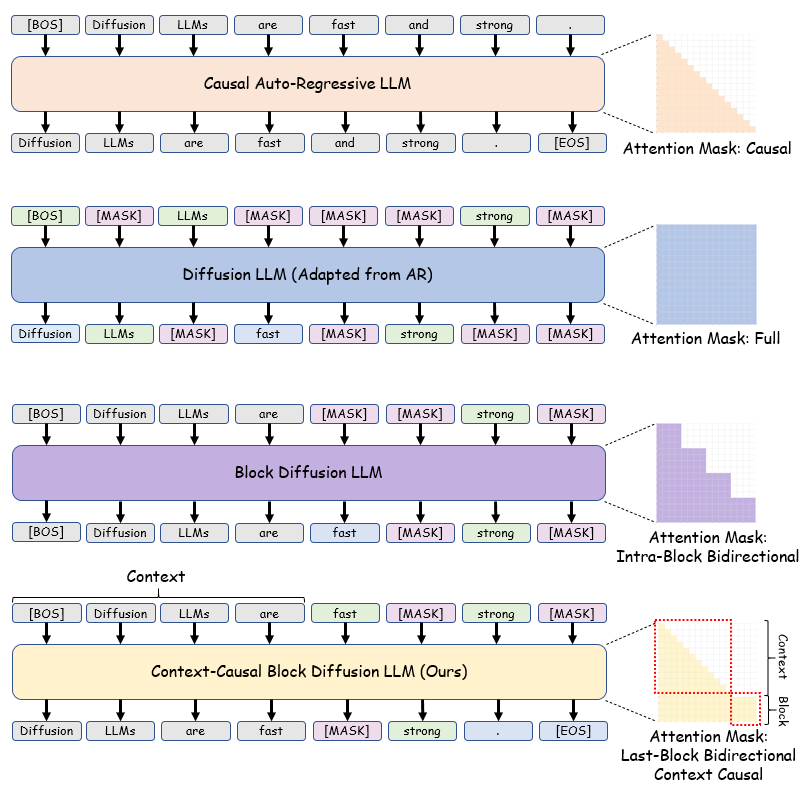
它在注意力机制上创新性地融合了自回归的前文因果注意力掩码,从架构层面解决了适配难题。训练策略上延续了BlockDiffusion的思路,但进行了关键优化,拼接带掩码的Block与无掩码的Context,展现出更强的适应性和效率。
目录
简介
在前面的章节中,我们展示了很多关于自回归模型的训练方法,哪怕是多模态模型,其中LLM部分也是基于自回归模型的(第六章)。在我们的课程里并没有完整的关于diffusion模型,也就是扩散模型的训练方法。本次教程我们就来实现diffusion模型的预训练以及微调,其中微调为核心,预训练仅做尝试即可。
其中扩散模型我们选择LLaDA模型,微调数据集还是采用经典的instruct数据集alpaca,预训练数据集经过多次试验,我们采用C4数据集来进行训练。
LLaDA原理
本次教程我们使用LLaDA模型作为基座模型来实现预训练和微调,我在实验的时候查看了下面的这些论文,有兴趣的小伙伴可以看看原文:
- Large Language Diffusion Models
- Diffusion Beats Autoregressive in Data-Constrained Settings
- Scaling Data-Constrained Language Models
关于扩散模型,我们最常用的还是图像领域的扩散模型,通常来说,图像领域的扩散模型有两个过程,分别是反向加噪过程和正向扩散过程
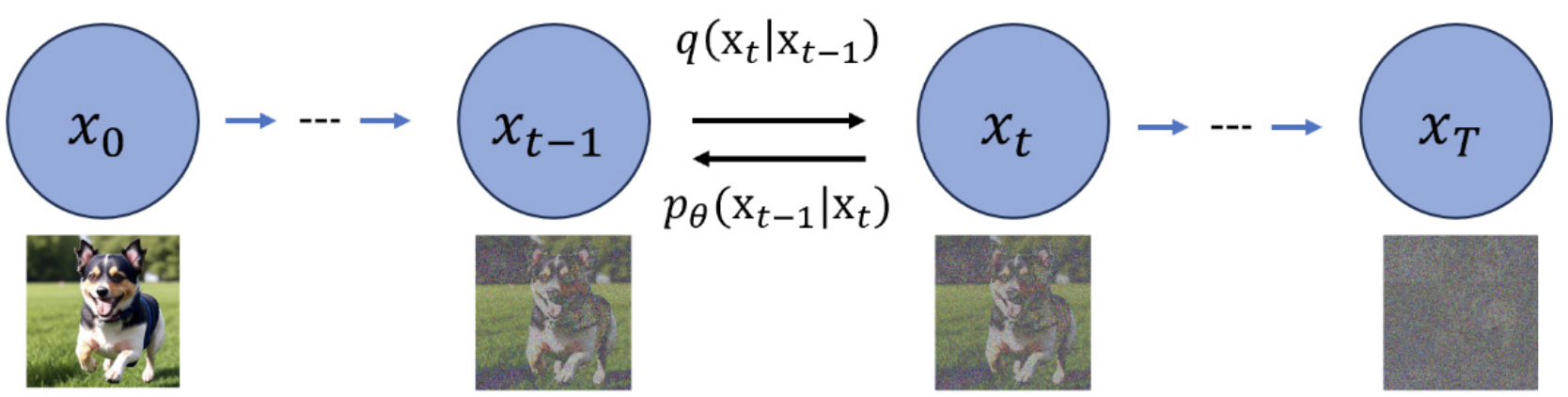
图像领域都是像素级的扩散,并且加噪过程会根据时间随机添加高斯噪声,但是在文本领域,扩散模型很少应用,传统的以及最新的、SOTA模型基本都是自回归架构,因此论文作者思考扩散模型是否能够应用到文本领域。
事实上,作者认为,自回归模型表现出的强大的指令遵从和上下文学习能力应该并不是自回归模型的专属,其他模型也可以做到,但是由于自回归模型体现出的性能太超模了,导致下意识的以为“指令遵从和上下文学习”是自回归模型带来的,因此作者验证了扩散模型在指令遵从和上下文学习能力上也可以做到自回归模型能做到的。
和图像领域的扩散模型相似,LLaDA在训练过程中也是反向加噪以及正向去噪的过程,不过有所区别的是,LLaDA无论是预训练还是微调,加噪过程都是一次性完成的,而且和图像加噪不同,LLaDA是针对tokens来进行随机加噪,或者说覆盖[MASK]标签,论文中给出的原理图已经很清晰的描述了出来:
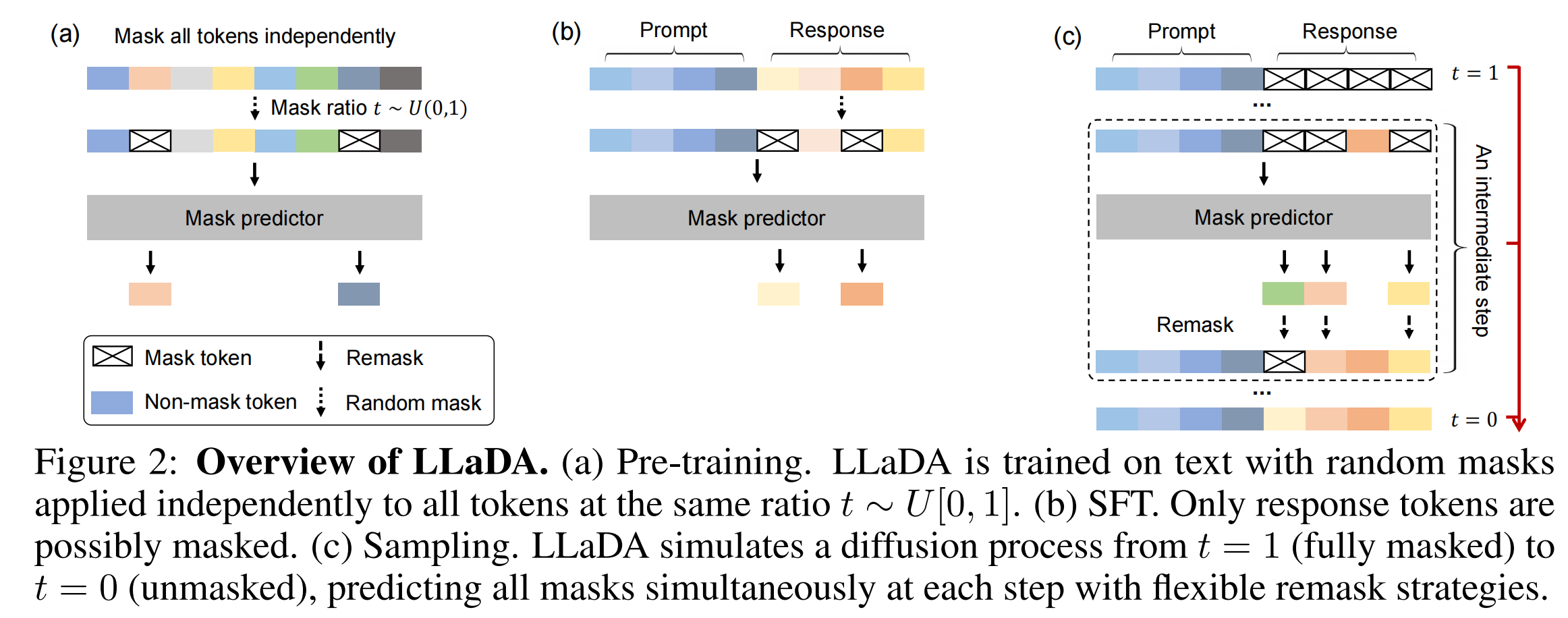
下面我们分别按照预训练、微调以及推理部分详细说明其原理:
预训练
我们知道对于自回归模型,LLMs 的目标是通过最大似然估计优化模型分布
主流方法依赖于自回归建模(ARM)—— 通常被称为 “下一个 token 预测” 的范式 —— 来定义模型分布,其表达式为:
LLaDA核心是一个掩码预测器,是一个参数化模型[MASK]的,按照t的比例掩码后的文本,预训练对应图Figure 2中的是text,微调则是response部分,该部分可同时预测所有被掩码的标记(记为 M)。
简单概括预训练的过程就是:
- 前向掩码过程:
,从原始数据 出发,按照随机比例t独立掩码每个token,得到部分掩码的序列 。 - 反向生成过程:
,模型 根据 预测所有被掩码的token,通过优化变分下界损失 来更新参数。
前向掩码过程就是随机比例的掩码,主要注意如果随机的数为0需要特殊处理,在采样t时,如果t=0,则
剩下的就一次性完成掩码过程即可。
对于反向生成过程,Loss的计算需要特别关注,模型仅在被掩码标记上计算的交叉熵损失进行训练,公式如下:
其中,
训练过程中,对于训练序列
⚠️需要注意的是,LLaDA模型训练的时候,掩码比例是在
2. 能够避免固定特定比例掩码导致的训练过拟合,而且BERT目标是学习上下文表示,不是生成完整文本,因此不需要模拟从噪声到数据的连续生成过程;
3.
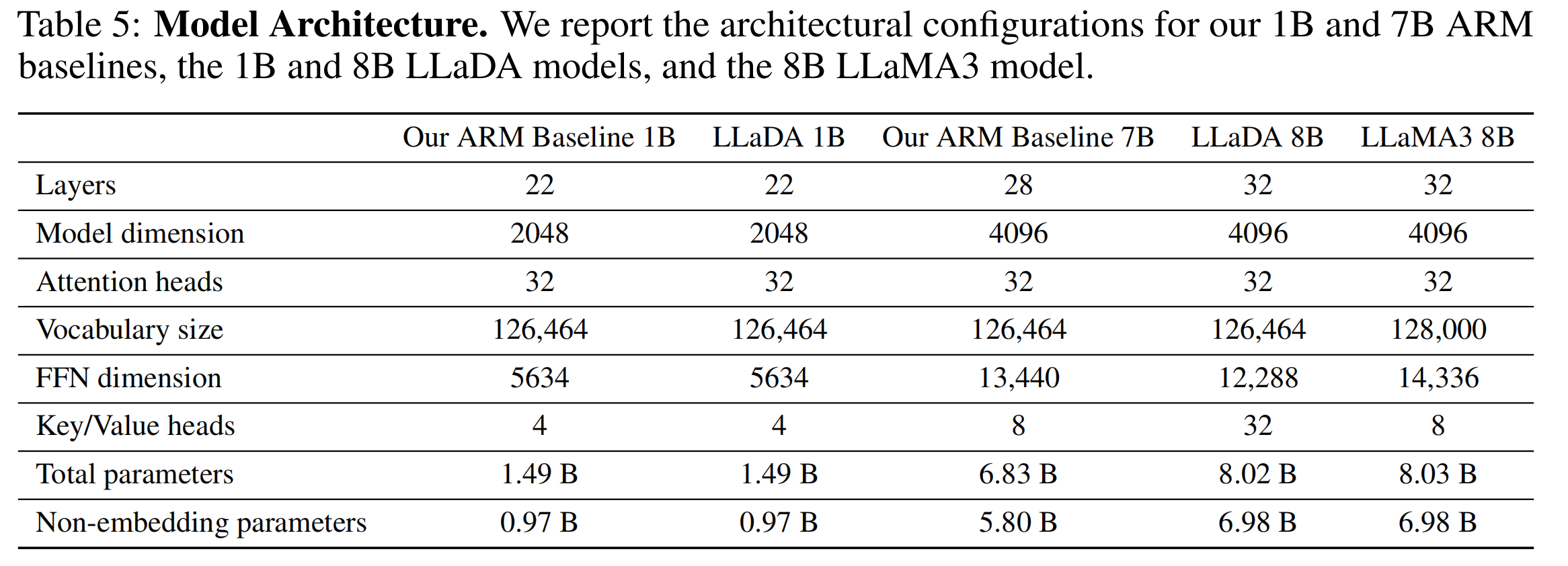
LLaDA 的损失函数是一个变分下界,它优化的是数据似然的近似,这个损失是在所有掩码比例上的期望,因此模型必须学习如何在不同掩码程度下预测被掩码的token,这与扩散模型的最大似然训练一致。对于预训练模型的参数设置,论文中给出了明确的参数配置,当然也可以在模型的config.json中查看,我们看下论文中的结果即可:
微调
对于监督微调过程,整体的核心逻辑和预训练相似,有几个区别:
- 预训练掩码和预测的tokens是完整的数据
和 ;而微调总共包含两个部分,分别是 和 ,其中 是提示词, 是对应的回答,微调阶段是掩码的 部分,提示词 部分不变。 - 微调的变分下界损失
有点区别
如图Figure 2(b)所示,保持提示词不变,对响应中的token进行独立掩码处理(处理方式与
其中
推理
推理采用的掩码和扩散生成和训练阶段有所不同,训练阶段掩码是随机比例掩码,但是推理的时候是全掩码,然后扩散生成。
对于扩散生成部分,作者做了多个实验,这里我们直接讨论结论:
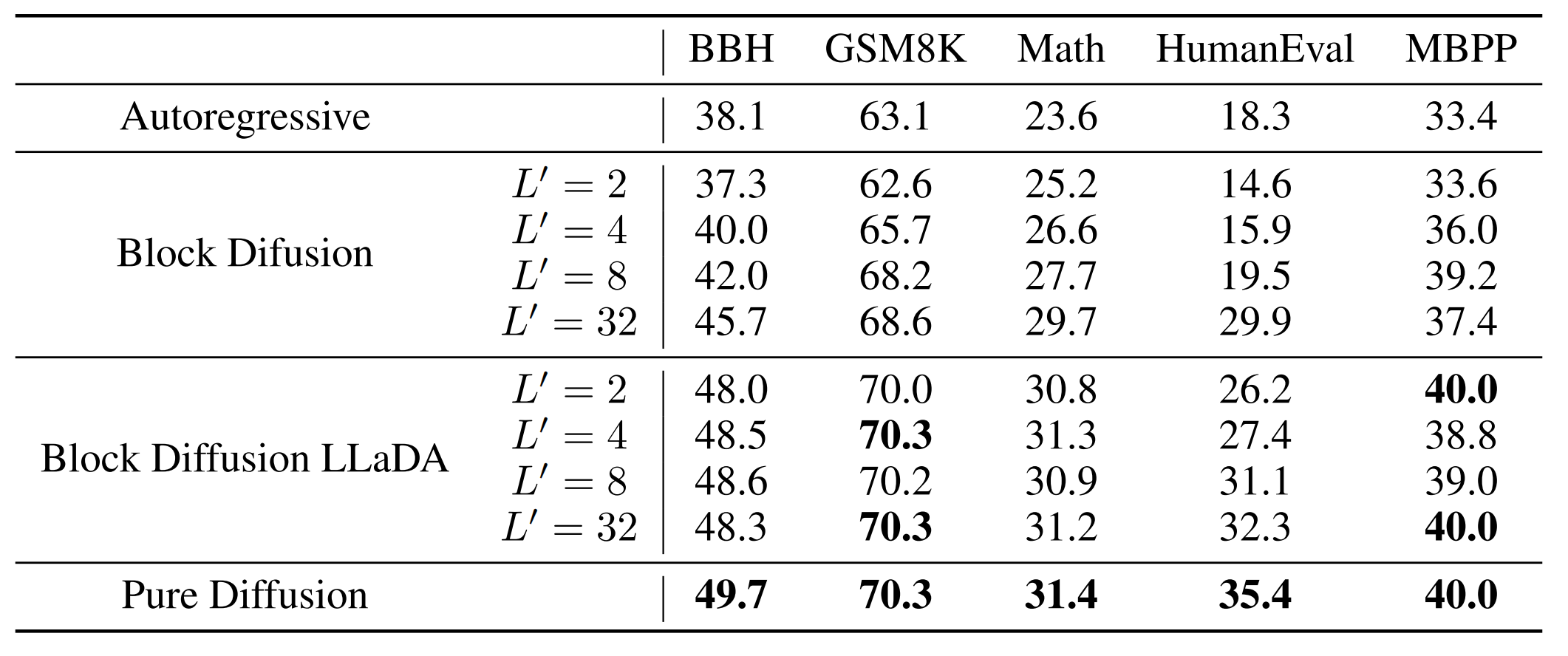
LLaDA模型使用纯扩散采样效果最好,如果使用块扩散采样,那么采用Block Diffusion LLaDA的方式最好。块内部的生成方式采用低置信度重掩码的方式生成。
低置信度重掩码简单来说就是每个step生成的tokens会计算其置信度,即使历史steps中生成的tokens也会因为置信度不符合要求会被要求重新生成,也就是我们说的纠错,这是自回归架构做不到的。
我们举个例子,生成的内容是:人工智能正在改变世界。
假如blocks有两个,分别是人工智能正在改变和世界。[<EOS>][<EOS>]
每个块里要生成4个tokens,那么我们假设迭代2次:
第一块
第一轮迭代(t=1.0)
| 步骤 | 内容 |
|---|---|
| 输入 | [M] [M] [M] [M] [M] [M] [M] [M] |
| 模型预测 | [人类] [智能] [在] [改变] [M] [M] [M] [M] |
| 采样策略 | 置信度阈值低,采纳 Top-2 |
| 采纳结果 | 位置1: 智能 (0.9), |
位置3: 改变 (0.85) | |
| 当前状态 | [M] [智能] [M] [改变] [M] [M] [M] [M] |
第一轮迭代(t=0.5)
| 步骤 | 内容 |
|---|---|
| 输入 | [M] [智能] [M] [改变] [M] [M] [M] [M] |
| 模型预测 | [人工] [智能] [在] [改变] [M] [M] [M] [M] |
| 采样策略 | 采纳置信度>0.7的 |
| 采纳结果 | 位置0: 人工 (0.85) |
位置1: 智能 (0.9) | |
位置2: 正在 (0.8) | |
位置3: 改变 (0.85) | |
| 当前状态 | [人工] [智能] [正在] [改变] [M] [M] [M] [M] |
第二块
第一轮迭代(t=1.0)
| 步骤 | 内容 |
|---|---|
| 输入 | [人工] [智能] [正在] [改变] [M] [M] [M] [M] |
| 模型预测 | [人类] [智能] [在] [改变] [世界] [。] [M] [M] |
| 采样策略 | 采纳置信度>0.8 |
| 采纳结果 | 位置0: 世界 (0.9), |
位置1: 。 (0.85) | |
| 当前状态 | [人工] [智能] [正在] [改变] [世界] [。] [M] [M] |
第一轮迭代(t=0.5)
| 步骤 | 内容 |
|---|---|
| 输入 | [人工] [智能] [正在] [改变] [世界] [。] [M] [M] |
| 模型预测 | [人工] [智能] [正在] [改变] [世界] [。] [<EOS>] [<EOS>] |
| 采样策略 | 采纳置信度>0.8的 |
| 采纳结果 | 位置0: 世界 (0.9), |
位置1: 。 (0.85) | |
位置2: <EOS> (0.85) | |
位置3: <EOS> (0.85) | |
| 当前状态 | [人工] [智能] [正在] [改变] [世界] [。] [<EOS>] [<EOS>] |
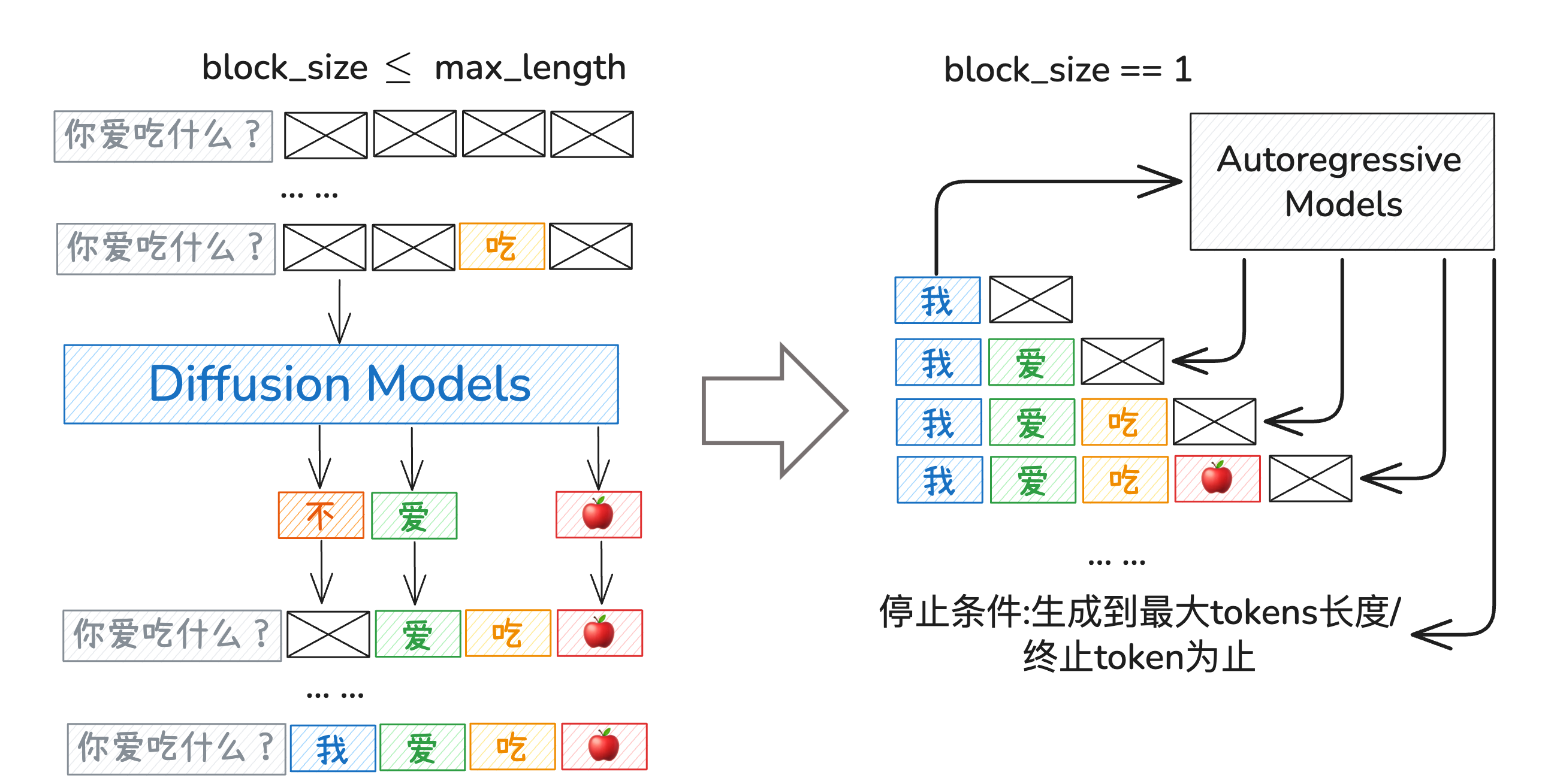
对于推理,同时预测所有被掩码的标记并不意味着一次性会全部预测,事实上,这是一个循序渐进的过程,经过多轮steps之后,消除[MASK],不过每一轮step具体预测哪一个[MASK]并不固定,这是和自回归不一样的,因为我们知道自回归模型只会预测下一个token。
论文中给出了详细的原理图:
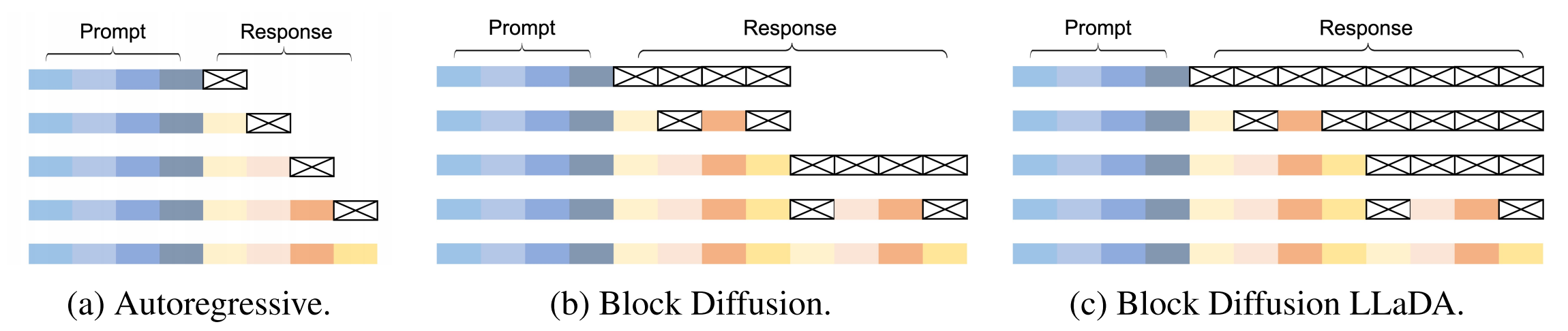
而在我们的实际代码中,对应有些参数:
max_new_length=8:生成8个tokens的文本steps=2:进行两轮迭代,从全掩码到无掩码block_size=4:表示的是每一块中有多少tokens,正好对应我们给的例子
而根据上述例子中给的结果,总共的block数量为

完整训练
1. 环境安装
- 克隆代码
git clone https://atomgit.com/windytina1/llada-npu.git
cd llada-npu- 安装环境
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple- 硬件要求
Pytorch2.7,我们要用到 torch_npu来适应NPU的使用,和torch版本要配套
假设我安装的是2.9.0版本的torch,那么运行下面的代码:
pip install torch==2.9.0 torchvision==0.24.0 torchaudio==2.9.0然后要找对应配套版本的torch_npu,也就是2.9.0版本的torch_npu,点击这里👉torch_npu
这里需要注意下载torch_npu的时候看清楚python版本
然后在实际使用的时候,直接import torch_npu就行,代码如下:
...
import torch
import torch_npu
...2. 数据处理
在简介中我们强调,SFT是核心,因此我会按照SFT需要的数据集格式来讲述,预训练其实遵循的是同样的步骤,只不过预训练需要的是text数据而已。
首先我们需要下载数据集,我希望用本地的数据集来完成本次微调,参考了datasets关于数据保存和使用的代码,觉得以 Arrow 格式保存到本地磁盘然后读取的方式更方便,Arrow 是未压缩的,因此重新加载速度更快,非常适合本地磁盘使用和临时缓存。
上述过程主要使用save_to_disk和load_from_disk保存和加载数据集,不过如果磁盘空间有限,建议还是直接用load_dataset。
SFT训练
下载数据格式参考Alpaca数据集格式:
Dataset({
features: ['instruction', 'input', 'output'],
num_rows: 48818
})然后需要转换成gpt的对话格式,也就是messages:
{
"messages": [
{"role": "user", "content": prompt},
{"role": "assistant", "content": response},
]
}最后用tokenizer转换成tokens形式:
Dataset({
features: ['input_ids', 'labels', 'prompt_len'],
num_rows: 48818
})然后保存成Arrow格式到本地磁盘,等训练时可以直接调用。
预训练
对于预训练数据集,只要下载的数据集里有text标签,可以直接保存到本地不用转换,代码如下:
from datasets import load_dataset
data_path='/data/lxy/diffusion/data/c4-en/en.noblocklist'
c4_dataset=load_dataset(data_path,split='train')
output_path='/data/lxy/diffusion/data/c4-en-train'
c4_dataset.save_to_disk(output_path)预训练之所以可以直接保存text形式内容,是因为在数据预处理阶段直接自动转换成tokens格式,而SFT由于我有个参数load_preprocessed_data设置为True了(官方默认为False),意思是提前处理好了,所以不会自动转换tokens,我不想改源代码,因此直接把数据集在下载阶段就转换好保存的。
我们看下dllm的关于数据处理部分的代码:
pretrain
dataset = dllm.data.load_pt_dataset(
data_args.dataset_args,
streaming=data_args.streaming,
load_preprocessed_data=data_args.load_preprocessed_data,
)
dataset = dataset.map(
functools.partial(
dllm.utils.tokenize_and_group,
tokenizer=tokenizer,
text_field=data_args.text_field,
seq_length=data_args.max_length,
insert_eos=data_args.insert_eos,
drop_tail=data_args.drop_tail,
),
batched=True,
remove_columns=dataset["train"].column_names,
**({} if data_args.streaming else {"num_proc": data_args.num_proc}),
**({} if data_args.streaming else {"desc": "Mapping dataset to PT format"}),
)SFT
dataset = dllm.data.load_sft_dataset(
data_args.dataset_args,
load_preprocessed_data=data_args.load_preprocessed_data,
)
if not data_args.load_preprocessed_data:
map_fn = partial(
dllm.utils.default_mdlm_sft_map_fn,
tokenizer=tokenizer,
mask_prompt_loss=data_args.mask_prompt_loss,
)
dataset = dataset.map(
map_fn,
num_proc=data_args.num_proc,
desc="Mapping dataset to SFT format",
)3. 训练代码
本次教程核心是学会微调,数据集采用经典Alpaca数据集,预训练采用部分C4英文数据集。我们希望教程能够教会完整的训练流程以及测试流程,因此数据集均采用经典通用的数据集。
我将分成两个模块来,为了符合正常的训练流程,教程依次是预训练和微调,代码地址👉ours
另外,如果有小伙伴想对比自回归模型和掩码扩散模型的区别,可以训练llama模型或者qwen模型作为对比。之所以可以训练llama模型来对比是因为llada的主体部分其实是llama结构,然后掩码不采用自回归模型的上三角形式,我们在模型文件中可以看到:
# Modify: MDM set causal to False.
return F.scaled_dot_product_attention(
q,
k,
v,
attn_mask=attn_mask,
dropout_p=dropout_p,
is_causal=False,
)其中is_causal设置为False,不采用自回归模型的掩码形式。
并且我们还可以从参数配置文件中看到:
"block_group_size": 1,
"block_type": "llama",
"d_model": 4096,主体的block采用llama结构,那么采用llama模型对比是很合适的。
而qwen作为比较通用的模型,我们经常使用,采用标准自回归模型结构,因此也可以作为对比模型测试对比效果。本次教程我们使用的就是Qwen模型作为对比模型。
那么接下来我们就开始训练吧,由于我已经整理过代码,因此可以直接运行脚本文件实现,下面简要说下每个文件的含义和用法:
├── configs
│ ├── llada-100M-pt-npu.yaml # llada预训练超参数设置
│ ├── llada-8b-sft-npu.yaml # llada微调超参数设置
│ ├── qwen2.5-100M-pt-npu.yaml # qwen预训练超参数设置
│ ├── qwen2.5-7b-alpaca-npu.yaml # qwen微调超参数设置
│ ├── ddp.yaml # 数据并行分布式训练参数设置
│ ├── zero2.yaml
│ ├── multi-npu.yaml # NPU分布式训练参数设置
│ └── ...
├── dllm
├── scripts
│ ├── train-llada-pt-multinpu.sh # llada预训练启动
│ ├── train-llada-sft-multinpu.sh # llada微调训练启动
│ ├── train-qwen-pt-multinpu.sh # qwen预训练启动
│ ├── train-qwen-sft-multinpu.sh # qwen微调训练启动
│ ├── eval-llada.sh # llada批量测试启动
│ └── eval-qwen.sh # qwen批量测试启动
├── examples
│ ├── llada
│ │ ├── pt.py
│ │ ├── sft.py
│ │ ├── chat.py # 终端交互式对话
│ │ └── generate.py # llada推理代码
│ ├── qwen
│ │ ├── pt.py
│ │ ├── sft.py
│ │ ├── chat.py # 终端交互式对话
│ │ └── utils.pyconfigs:包含训练超参数设置、deepspeed分布式训练参数设置等scripts:训练启动文件、eval启动文件等examples:核心微调、预训练训练代码等
预训练
预训练和微调的训练方式可能会稍微有点不一样,原因如下:
- 教程仅做为示例,核心还是微调
- 我想验证下Diffusion Beats Autoregressive in Data-Constrained Settings这篇文章的观点,因此会采用小参数量的模型,和少规模tokens的数据集作为训练资源
💡从原因上大家也能看出,和微调不一样的是,小参数量模型 作为基座模型。那么如何构建小参数量模型呢?
其实很简单,预训练模型其实就是构建好框架后,喂大量的数据集让模型学会如何生成内容,而训练前是没有权重文件的,或者说用不上权重文件的。因此想要构建小参数量模型,直接把config文件以及tokenizer相关文件下载下来就行,类似于*.safetensors这样的文件直接不用下载。然后我们修改config.json中的参数,让最终算出来的参数量达到我们要的量级就行,我使用的模型是100M大小。
下面跟着我的代码按步骤实现:
1. 下载文件
由于我们核心为微调,在微调代码中已经包含了下载llada-8b模型的步骤,因此如果要构建一个100M的模型,把llada-8b中去除 *.safetensors的所有的文件复制到新的文件夹中,命名成llada-100M就行。

2. 修改参数
对于如何修改参数,论文中给出了对应的参数量,如下图所示:
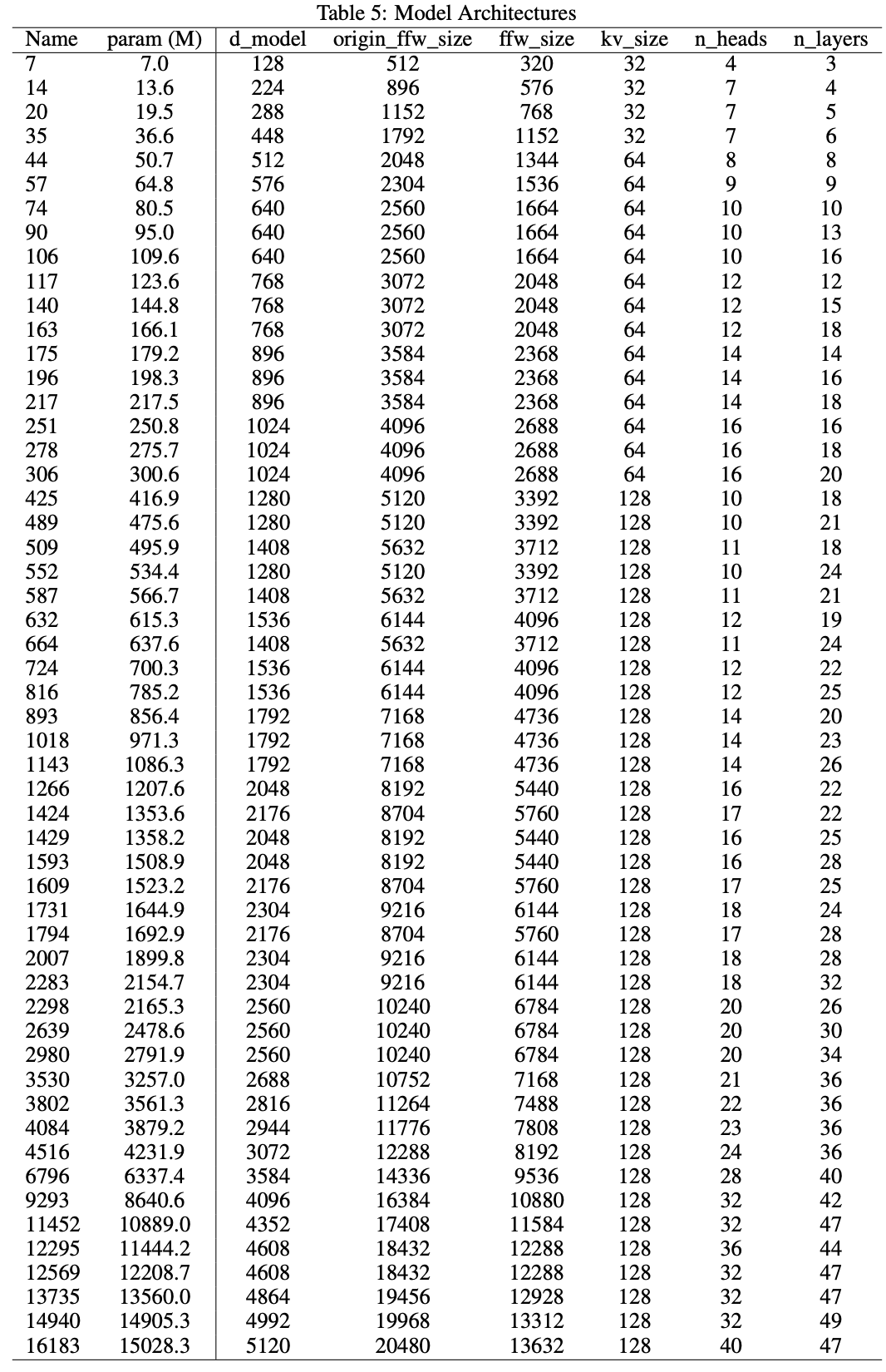
但是我在实践的时候发现总是会超过表格中的参数,这可能是由于vocab_size以及其他的一些参数导致的,因此表格中参数仅做参考,我设置的参数如下所示:
{
"activation_type": "silu",
"alibi": false,
"alibi_bias_max": 8.0,
"architectures": ["LLaDAModelLM"],
"attention_dropout": 0.0,
"attention_layer_norm": false,
"attention_layer_norm_with_affine": true,
"auto_map": {
"AutoConfig": "configuration_llada.LLaDAConfig",
"AutoModelForCausalLM": "modeling_llada.LLaDAModelLM",
"AutoModel": "modeling_llada.LLaDAModelLM"
},
"bias_for_layer_norm": false,
"block_group_size": 1,
"block_type": "llama",
"d_model": 448,
"embedding_dropout": 0.0,
"embedding_size": 126464,
"eos_token_id": 126081,
"flash_attention": false,
"include_bias": false,
"include_qkv_bias": false,
"init_cutoff_factor": null,
"init_device": "meta",
"init_fn": "mitchell",
"init_std": 0.02,
"input_emb_norm": false,
"layer_norm_type": "rms",
"layer_norm_with_affine": true,
"mask_token_id": 126336,
"max_sequence_length": 1024,
"mlp_hidden_size": 768,
"mlp_ratio": 2,
"model_type": "llada",
"multi_query_attention": null,
"n_heads": 7,
"n_kv_heads": 7,
"n_layers": 6,
"pad_token_id": 126081,
"precision": "amp_bf16",
"residual_dropout": 0.0,
"rms_norm_eps": 1e-5,
"rope": true,
"rope_full_precision": true,
"rope_theta": 10000.0,
"scale_logits": false,
"transformers_version": "4.46.3",
"use_cache": false,
"vocab_size": 126464,
"weight_tying": false
}通过计算得到总参数量:
from transformers import AutoConfig, AutoModelForCausalLM
import torch
config = AutoConfig.from_pretrained("/data/lxy/diffusion/llada-100M",trust_remote_code=True)
with torch.device("meta"):
model = AutoModelForCausalLM.from_config(config) # 只建形状,不占内存
print(model.num_parameters())
# 124327616然后预训练启动代码如下:
bash scripts/train-llada-pt-multinpu.sh对应超参数设置为configs/llada-100M-pt-npu.yaml,具体的参数设置如下:
# ModelArguments
model_name_or_path: /data/lxy/diffusion/llada-100M
# DataArguments
dataset_args: /data/lxy/diffusion/data/c4-en-shuffled[train:1000_000,test:1000]
text_field: text
streaming: false
num_proc: 8
drop_tail: true
max_length: 1024
load_preprocessed_data: true
insert_eos: true
random_length_ratio: 0.01
# TrainingArguments
output_dir: /data/lxy/diffusion/output/llada-pt-c4-500Mtokens-epoch-1
run_name: llada-pt-c4-500Mtokens-epoch-1
learning_rate: 3.0e-4
warmup_steps: 2000
# num_train_epochs: 1
max_steps: 10
per_device_train_batch_size: 2
per_device_eval_batch_size: 2
gradient_accumulation_steps: 8
logging_steps: 20
eval_strategy: steps
eval_steps: 200
save_steps: 1000
save_total_limit: 2需要注意的是,warmup_steps需要根据数据量以及训练轮次来设置固定值,2000步的预热比较合适。其他的参数设置和微调参数设置相同。
微调
在下载好模型并且数据集预处理后,运行下面的代码即可:
bash scripts/train-llada-sft-multinpu.sh如果要修改超参数等,那么对configs/llada-8b-sft-npu.yaml的内容进行修改:
# ModelArguments
model_name_or_path: /data/lxy/diffusion/llada-8b
lora: true
target_modules: all-linear
r: 32
lora_alpha: 64
lora_dropout: 0.05
# DataArguments
dataset_args: /data/lxy/diffusion/data/alpaca-zh-gpt[train:2000,test:200]
num_proc: 8
max_length: 1024
load_preprocessed_data: true
# TrainingArguments
output_dir: /data/lxy/diffusion/output/llada-gpu1-epoch-test
report_to: swanlab
run_name: llada-alpaca-zh-epoch-test
learning_rate: 3.0e-4
warmup_ratio: 0.1
# num_train_epochs: 1
max_steps: 10
per_device_train_batch_size: 2
per_device_eval_batch_size: 2
gradient_accumulation_steps: 8
logging_steps: 2
eval_strategy: steps
eval_steps: 200
save_steps: 1000
save_total_limit: 2有些地方需要注意:
dataset_args是你的数据集保存地址,由于我下面的load_preprocessed_data设置为true,也就是提前处理了数据集的意思,因此保存的数据集内容要求是tokens形式。- 最好将
max_steps改成num_train_epochs,然后微调2-3个epoch即可。如果是max_steps最好提前计算下选择多少steps较为合适。 SwanLab是我们的训练观测工具,由于dllm继承了Transformers父类,而且Transformers已经集成SwanLab,因此我们直接令report_to=swanlab,唯一需要注意的是,如果想修改项目名称的话,需要提前设置环境变量,我在这里进行设置👉project_name
*Qwen
本次教程选择Qwen模型作为llada模型的对比模型,用Qwen模型进行预训练和微调,分别和llada模型对比预训练和微调效果。
其中预训练和llada一样,设置一个100M参数量的模型来进行训练,步骤和llada的一样,只不过要运行下面的代码:
bash scripts/train-qwen-pt-multinpu.sh需要注意的是,由于Qwen和llada结构不一致,因此在设计100M参数量的时候可能会稍微有点区别,因此这里给出我的config.json文件的参数设置:
{
"architectures": ["Qwen2ForCausalLM"],
"attention_dropout": 0.0,
"bos_token_id": 151643,
"eos_token_id": 151643,
"hidden_act": "silu",
"hidden_size": 448,
"initializer_range": 0.02,
"intermediate_size": 768,
"max_position_embeddings": 2048,
"max_window_layers": 6,
"model_type": "qwen2",
"num_attention_heads": 7,
"num_hidden_layers": 6,
"num_key_value_heads": 7,
"rms_norm_eps": 1e-6,
"rope_theta": 10000.0,
"sliding_window": 2048,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.40.1",
"use_cache": true,
"use_mrope": false,
"use_sliding_window": false,
"vocab_size": 152064
}其次是微调,对于Qwen模型的微调我们已经设置了很多教程,如果有兴趣的小伙伴可以查看我的另外一篇专门讲lora训练的文章,这里只需要运行下面的启动文件就行:
bash scripts/train-qwen-sft-multinpu.sh超参数设置在configs/qwen2.5-7b-alpaca-npu.yaml
该部分仅作为llada模型结果的对比
SwanLab观测结果
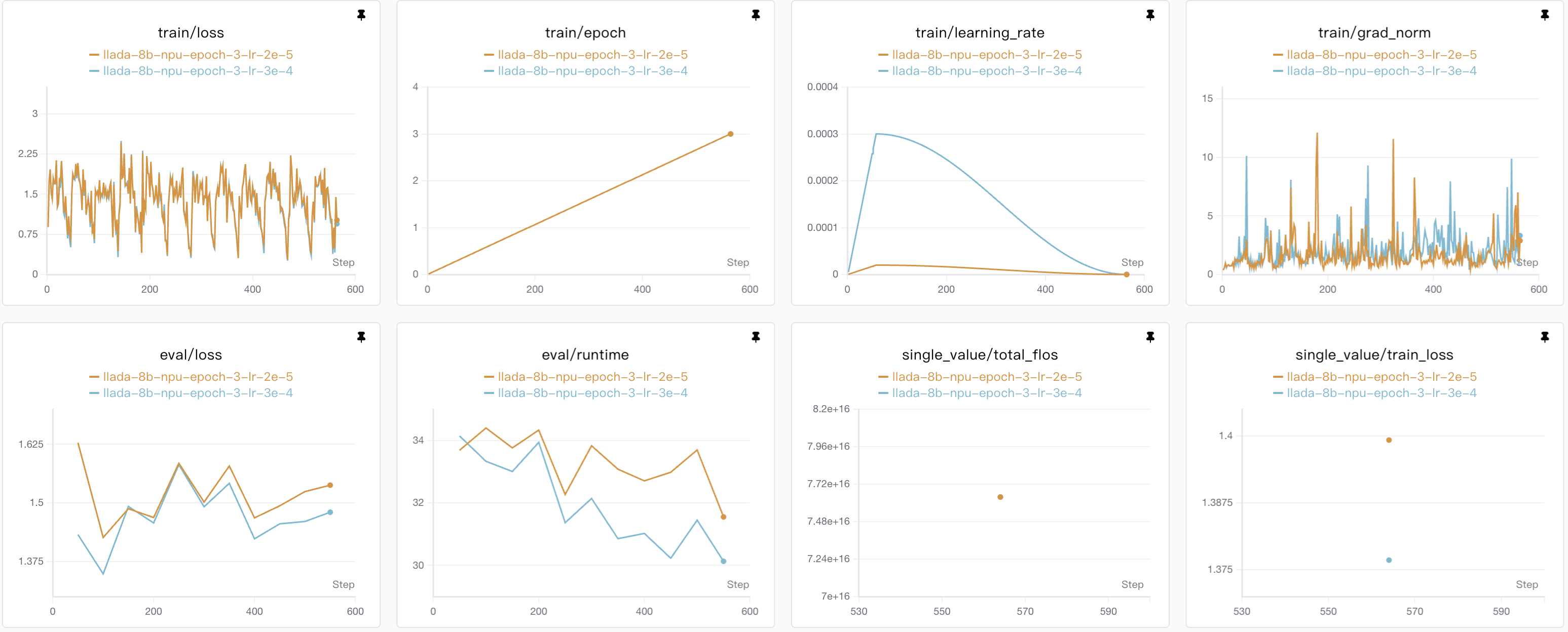
LLaDA微调结果
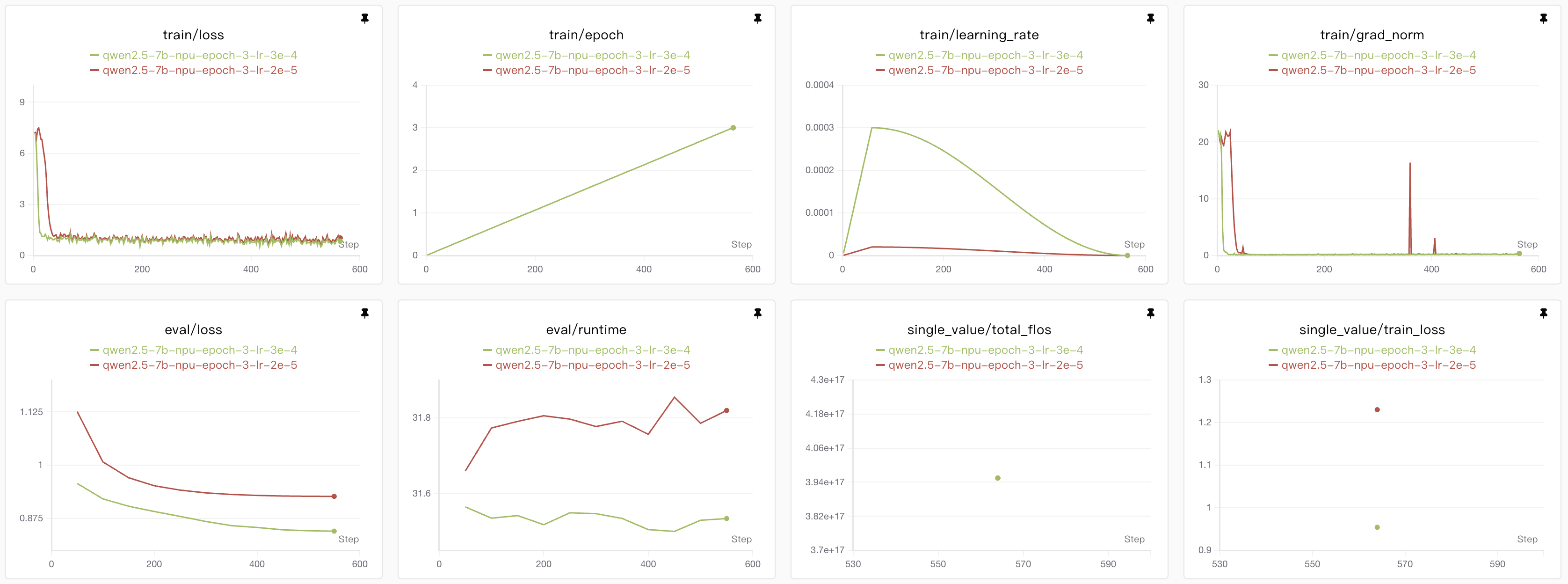
Qwen模型微调结果
微调结果对比
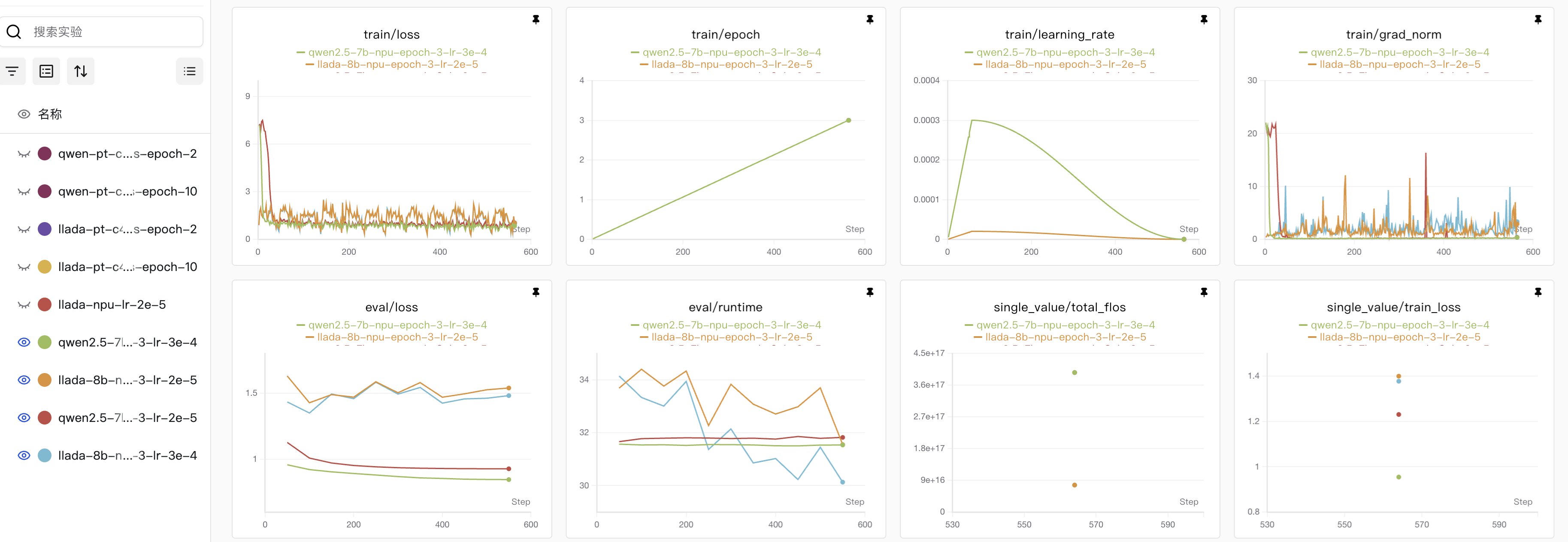
微调我使用的是经典alpaca数据集,用了前3000条数据作为训练集,都是训练了3个epoch,
在epoch=3的时候,Qwen模型表现出来的效果还是比较好的,但是如果更多的epoch可能会导致Qwen模型的过拟合,相比较而言llada模型还有下降的空间。
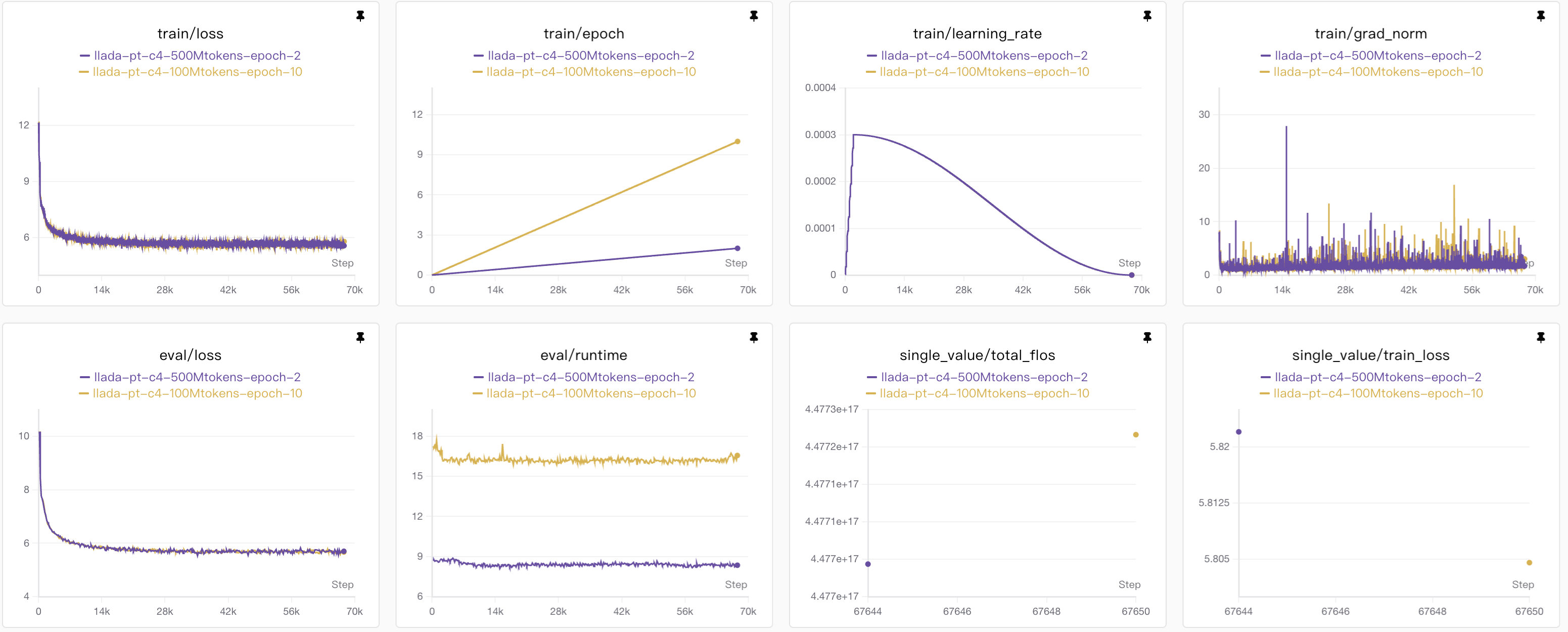
LLaDA预训练结果
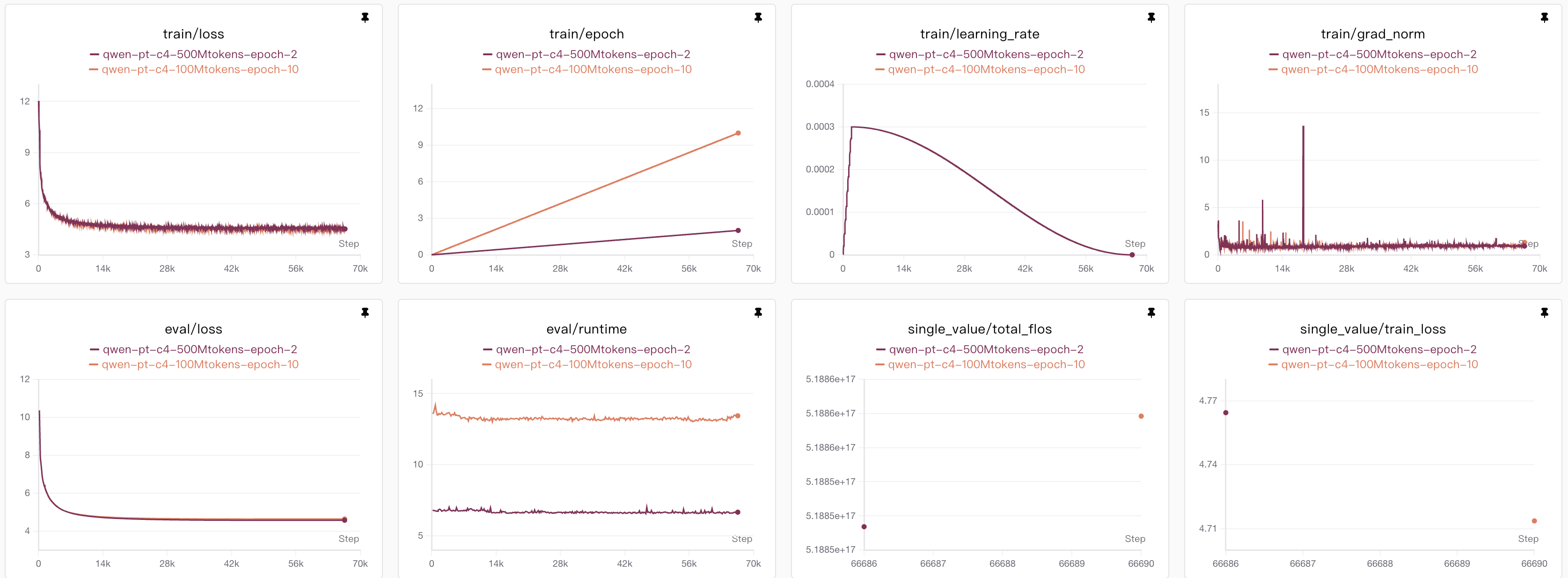
Qwen预训练结果
预训练结果对比
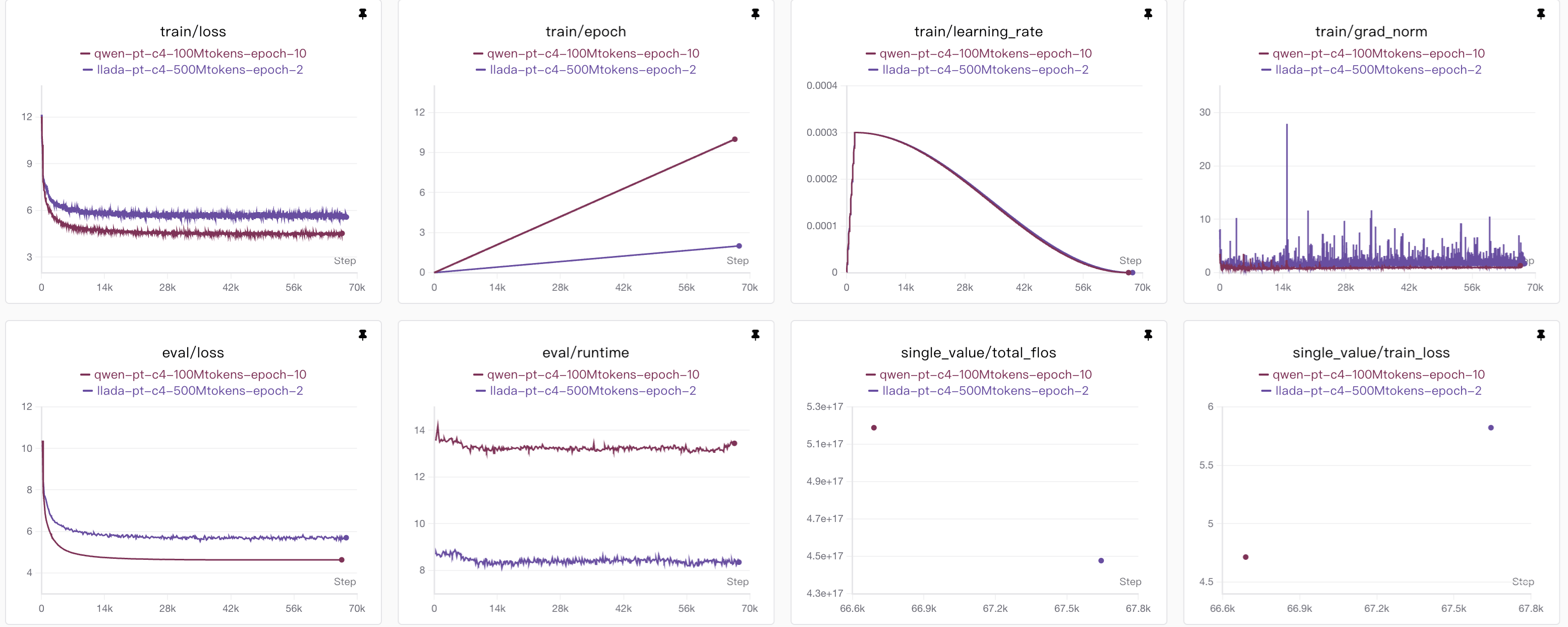
预训练我使用的是C4-en中的一部分,模型我设置为100M的大小,分别对比了epoch=2和epoch=10的情况。
其中epoch=2的时候,我使用了前100万条数据,通过计算得知,每条数据平均有大约500 tokens左右,因此总共的计算量应该有500M tokens;
然后epoch=10,我设置数据集为前20万,计算量保持一致;
之所以这样设置,我只是想观测unque数据和计算量两个会不会影响结果,但是从图表显示并没有什么变化,不过也可能是因为我的模型参数量设置的太小的缘故。
结果测试
对于训练得到的结果,可以直接进行chat推理对话,或者也可以使用ceval、cmmlu等数据批量测试并得到结果数据。
单次推理对话
我们先看下如何推理,在推理前,我们先合并模型参数,微调用的lora微调,需要合并参数,但是如果是全参量微调,不用在意这一步:
python /home/lxy/diffusion_project/llada-sft/examples/llada/merge.py \
--lora_path /data/lxy/diffusion/output/llada-gpu1-epoch-3/checkpoint-final \
--base_model_path /data/lxy/diffusion/llada-8b \
--merge_path /data/lxy/diffusion/output/merge-llada-8b-alpaca-zh-gpt-epoch-3然后如果想直接推理,llada模型有两个可以使用的代码:
chat.py:终端交互式对话generate.py:代码中修改,并在终端打印结果
如果想在终端进行互动,可以运行下面的代码:
ASCEND_RT_VISIBLE_DEVICES=0 python examples/llada/chat.py \
--model_name_or_path "/root/models/LLaDA/output/merge-llada-8b-epoch-3-lr-2e-5" \
--steps 128 \
--max_length 128 \
--block_length 32steps:在扩散模型的反向生成过程中,从t=1(全掩码)到t=0(无掩码)需要执行的迭代次数。每一步对应一个离散的t值,模型在该步骤预测掩码位置的内容。steps越大:生成质量通常更高,因为更多迭代允许更精细的调整,但推理速度越慢。
steps越小:推理越快,但可能牺牲生成质量。
block_size:在使用块扩散采样策略时,每个块(block) 的长度。block_size = 生成长度(如1024):相当于纯扩散采样,一次性生成整个序列。
block_size = 1:相当于完全自回归采样,逐词生成。
block_size 介于两者之间:半自回归采样,平衡速度和质量。
论文验证了在block_size=32的时候,和纯扩散模型效果差不多,因此这样设置:
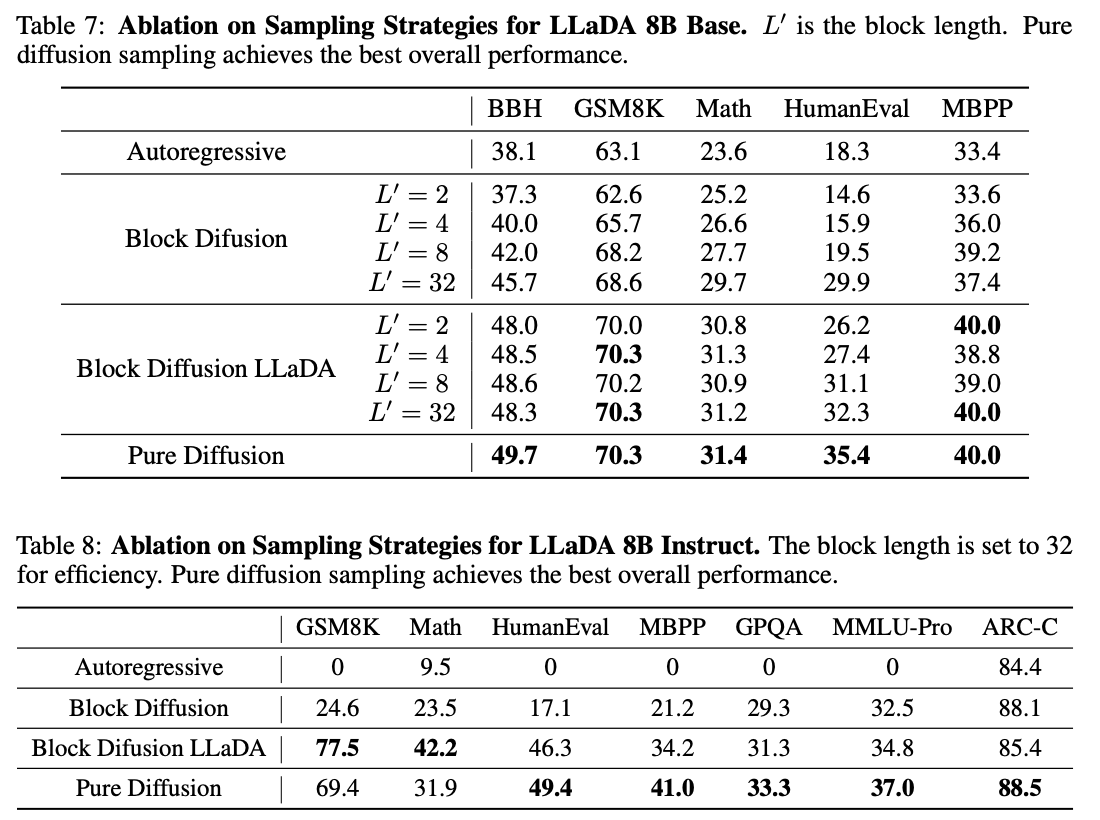
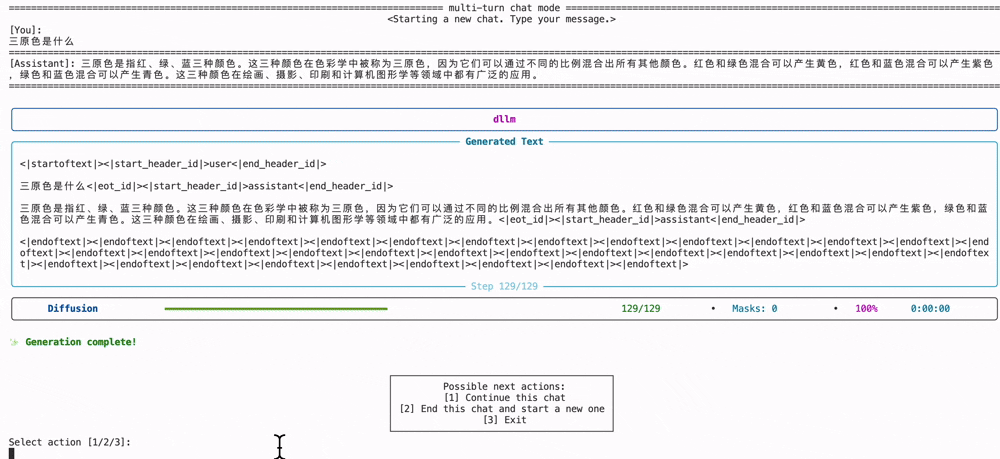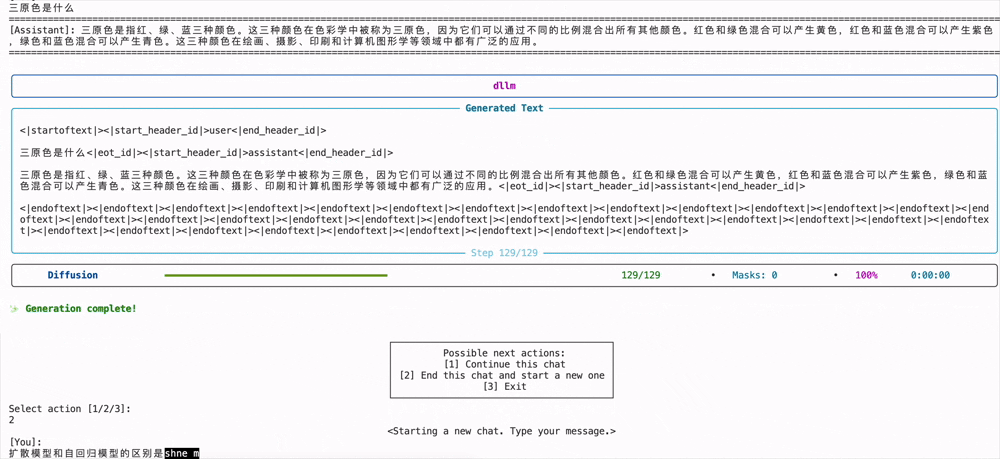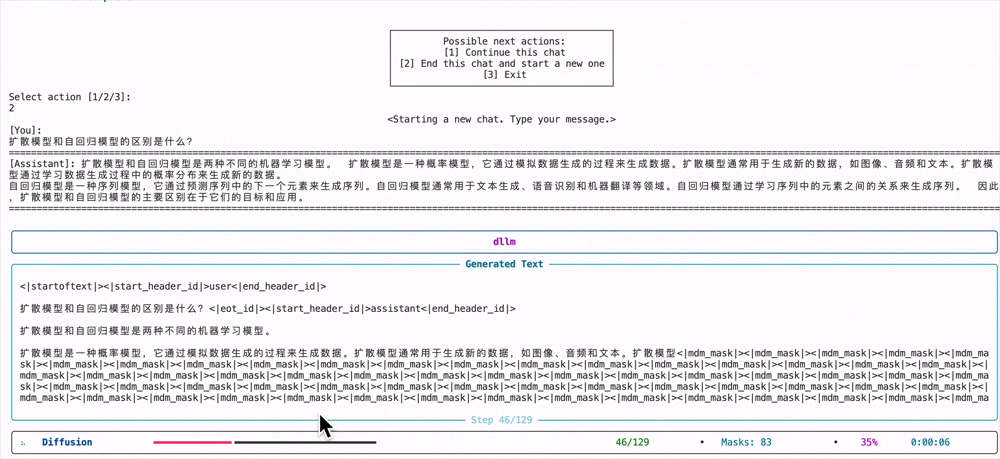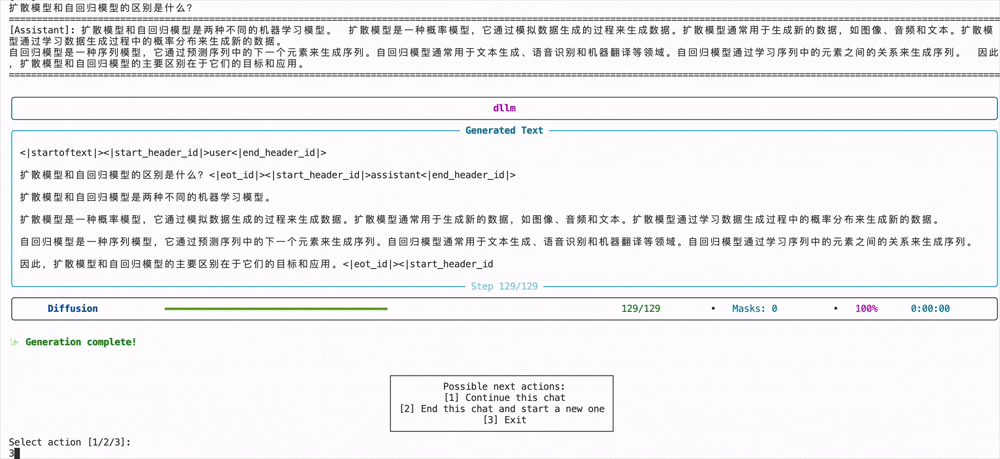
然后最终的推理效果和之前说的动图一样,在生成tokens的时候会不断的消除[MASK],diffusion模型和自回归模型很不一样的地方在于,消除的[MASK]并不一定是按照顺序的,有可能会反复确认并生成:
当然也可以直接运行下面的代码,然后终端打印结果,如果想要修改提示词,请在generate.py的代码中修改prompt:
python examples/llada/generate.py# 运行该代码
ASCEND_RT_VISIBLE_DEVICES=0 python examples/qwen/chat.py \
--model_name_or_path /root/models/Qwen/qwen2.5-7b-it \
--max_new_tokens 256
从效果上看,Qwen模型生成的时候是按照从前往后的顺序依次生成tokens,和diffusion模型不同,它并不会对已经给出的历史记录进行修改,因此在训练的时候,diffusion之类的模型能够更加理解话语中的深层含义,自回归模型容易沿着错误的生成结果一直生成。
批量测试
我已经根据dllm的代码设计了测试用的脚本,运行下面的代码就可以进行测试:
bash scripts/eval-llada.sh或者运行下面的代码:
export PYTHONPATH=../:$PYTHONPATH
export HF_ALLOW_CODE_EVAL=1 # Allow code evaluation
export HF_DATASETS_TRUST_REMOTE_CODE=True # For cmmlu dataset
export TORCH_NCCL_ASYNC_ERROR_HANDLING=1 # Enable async error handling for multi-GPU communication to avoid deadlocks
export NCCL_DEBUG=warn # Show NCCL warnings for better diagnosis without flooding logs
export TORCH_DISTRIBUTED_DEBUG=DETAIL # Provide detailed logging for PyTorch distributed debugging
accelerate launch --num_processes 1 \
dllm/pipelines/llada/eval.py \
--tasks cmmlu \
--model llada \
--apply_chat_template \
--output_path /data/lxy/diffusion/eval/llada/llada-cmmlu/llada-8b-epoch-3/test \
--log_samples \
--max_batch_size 4 \
--model_args "pretrained=/data/lxy/diffusion/output/merge-llada-8b-alpaca-zh-gpt-epoch-3,is_check_greedy=False,mc_num=1,max_length=1024,steps=256,block_size=64,cfg=0.0"如果要进行别的task测试任务,修改其中的tasks即可,需要注意的是,dllm使用lm_eval来测试的,因此tasks要选择该框架中有的,具体可以查看👉tasks列表
参考文献
[1].7B扩散LLM,居然能跟671B的DeepSeek V3掰手腕,扩散vs自回归,谁才是未来?
[3].嚯!大语言扩散模型来了,何必只预测下一个token | 人大高瓴&蚂蚁
[4].Large Language Diffusion Models
[5].Diffusion Beats Autoregressive in Data-Constrained Settings