Qwen3.5微调-甄嬛角色扮演
Qwen3.5 是阿里千问团队开源的大语言模型。以 Qwen3.5 作为基座大模型,通过监督微调(sft)的方式做角色扮演,是学习LLM微调的入门任务。

在本文中,我们会使用 Qwen3.5-4B 模型在 **甄嬛传数据集“Chat-嬛嬛” **上做指令微调训练,使用 TRIO 作为计算平台(一种大模型训练API),同时使用SwanLab监控训练过程、评估模型效果。
TRIO 不需要考虑本地算力,只要一台能联网的笔记本就行
代码:完整代码直接看本文第5节
实验日志过程:chat-huanhuan - swanlab
模型:Qwen3.5-4B
数据集:Chat-嬛嬛
训练Token数:0.48M,大约花费 2.3 元
环境安装
本案例基于Python>=3.10,请在您的计算机上安装好Python;
由于使用 TRIO 作为计算引擎,所以只需要任意一台能联网的个人电脑即可,不用考虑算力;
我们需要安装以下这2个Python库,分别用于计算和实验监控:
pytrio
swanlab一键安装命令:
pip install pytrio swanlab准备数据集
本案例使用 Chat-嬛嬛 作为数据集 ,这是一个利用《甄嬛传》剧本中所有关于甄嬛的台词和语句进行合成的数据集(共 3729 条),常被用于大模型LoRA微调任务,得到模拟甄嬛语气的LLM。

Chat-嬛嬛中的部分样本如下:
{
"instruction": "皇上驾到!",
"input": "",
"output": "皇上万福金安——"
},
{
"instruction": "娘子,此番回宫,有些东西你是一定要舍弃了,比如——心!不是狠心,狠心亦是有心,娘娘要做的是狠而无心。",
"input": "",
"output": "槿汐,除了你,便再也没有人会对我说这样的话了。"
},
...每条样本包含 instruction、input、output 三个字段。
在训练时,代码会把 instruction 和 input 拼成用户输入,把 output 作为模型需要学习的回复(这里input没有的值的原因是为了符合 Alpaca 数据集格式,实际input没有发挥作用)。
我们将数据集下载到本地目录下。下载方式是前往huanhuan.json - Github ,将 huanhuan.json 下载到本地根目录下即可:
配置TRIO
TRIO 是一个专为大模型训练设计的AI计算框架,特点是开发者不需要考虑环境配置、模型下载、GPU底层等等问题,只需要在任意一台电脑上,安装pytrio包,写几行代码就能开启训练:
TRIO 的原理是将训练做了一层前后分离:开发者在本地电脑上定义训练行为(和写pytorch是类似的),TRIO在云端对一批批传递上来的数据 做前向反向计算,更新权重,并返回loss、logprobs等指标。
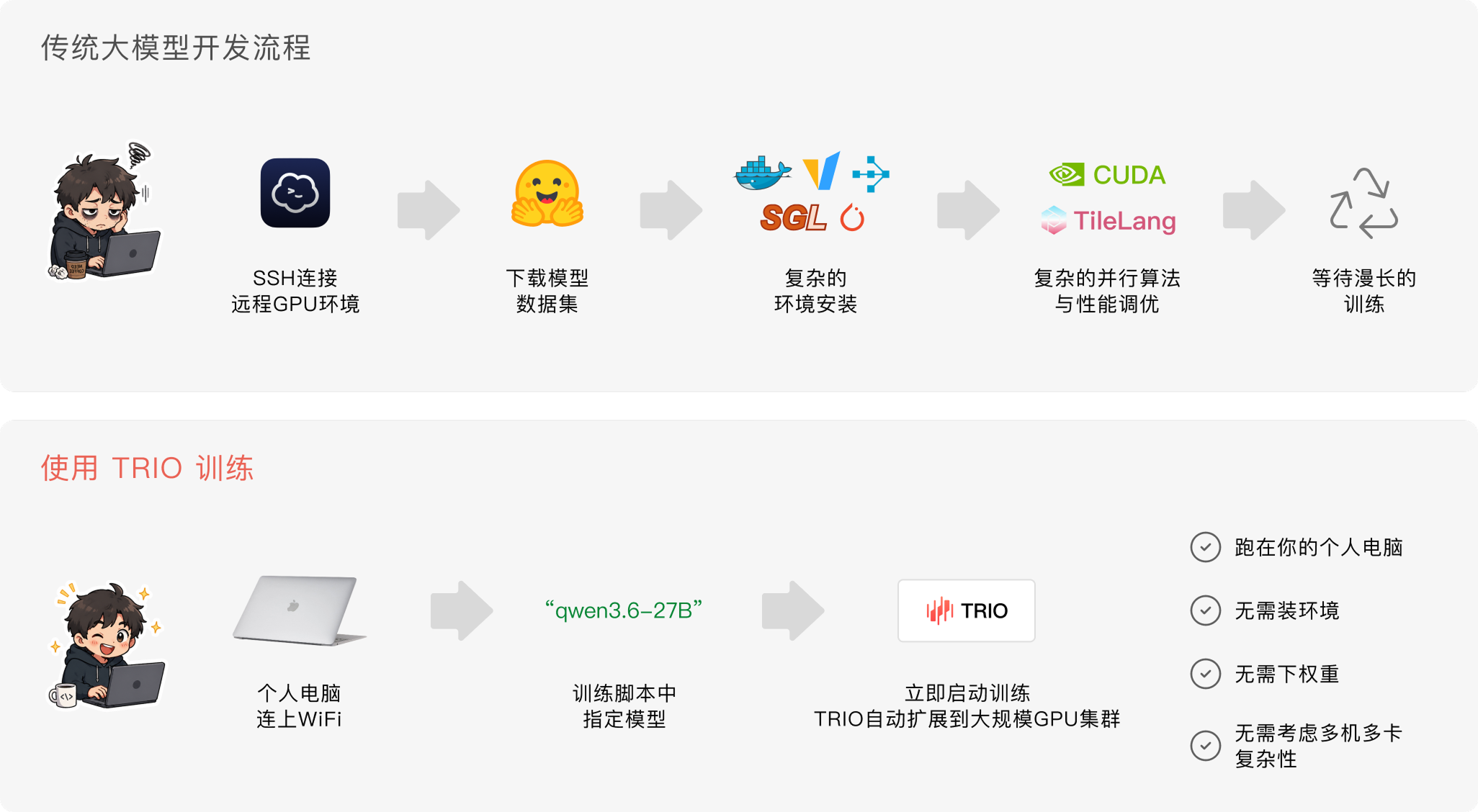
这让使用 TRIO 的训练流程特别像调用推理API —— 任意联网设备,写好代码,请求TRIO后端,就能启动训练,所以大家称 TRIO 为一种创新的“训练API”。
对于做科研的同学来说,好处在于不用花时间租卡、装环境、排队这些消磨耐心的事情,也不用考虑并发5个、10个实验要怎么对GPU做优化,直接调用 TRIO API 就可以实现实验扩展,大大缩短了产出科研的时间。
TRIO 的使用十分简单,首先去到官网(pytrio.cn)注册一个账号:

完成注册后,在「总览」页,复制 API Key:

在本地环境执行命令:
trio login然后粘贴API Key,按下回车,即可完成登录:

完成登录后,记得充点钱用于后续的训练(本教程训完大概花2块钱):
想了解使用TRIO的更多细节,可参考官方文档:https://docs.pytrio.cn/docs/quick-start
配置模型
TRIO 配置模型的方式非常简单,只需要在base_model参数里写一行字符串,而无需下载权重:
training_client = service_client.create_lora_training_client(
base_model="Qwen/Qwen3.5-4B",
rank=32,
)这意味着切换模型也只需要改字符串即可,而不用等待下载和部署时间。支持的模型列表可以在 支持模型列表 里看到。
配置可视化工具
我们使用 SwanLab 来监控整个训练过程,并评估最终的模型效果。
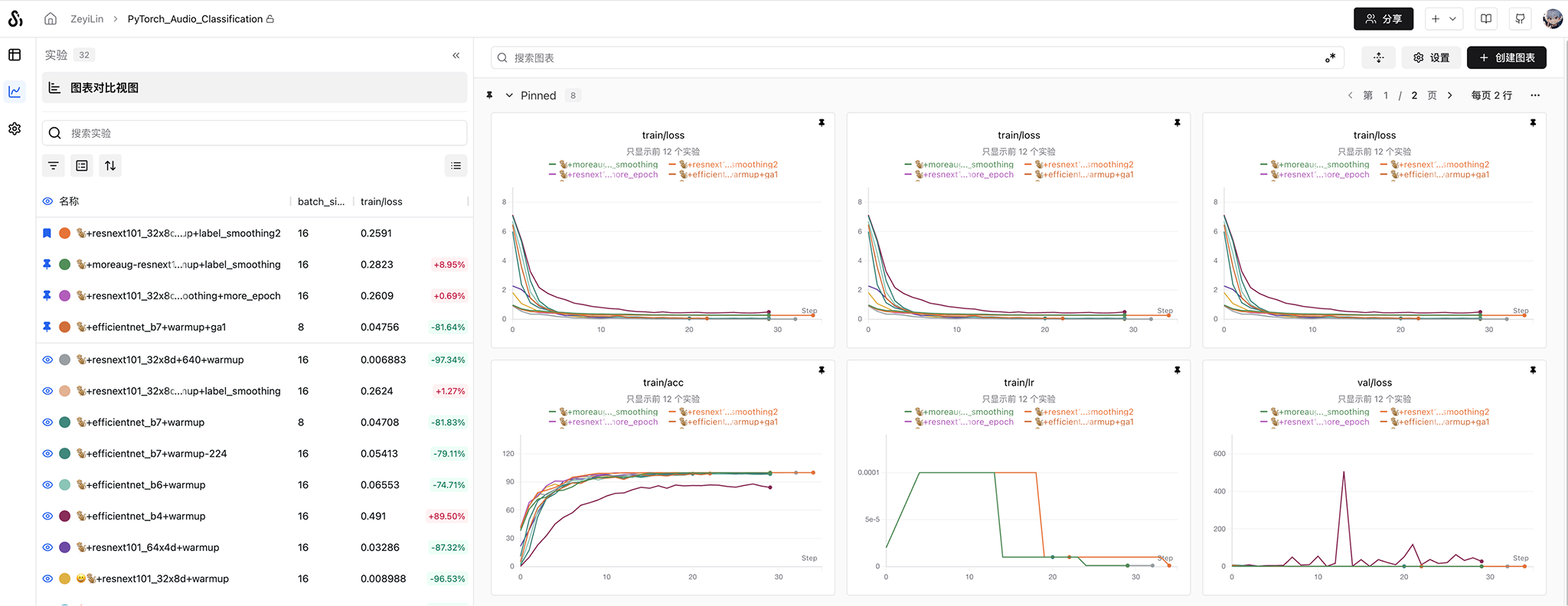
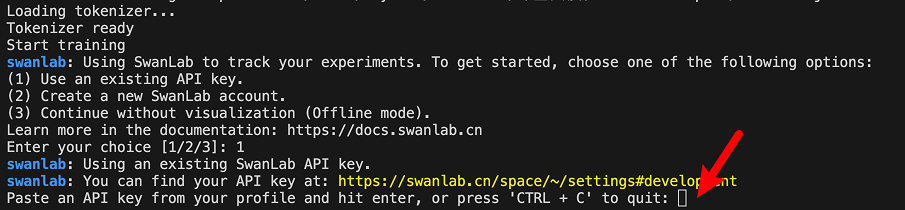
如果你是第一次使用SwanLab,那么还需要去https://swanlab.cn上注册一个账号,在用户设置页面复制你的API Key,然后在训练开始时粘贴进去即可:
完整代码
开始训练时的目录结构:
|--- huanhuan.json
|--- train.py完整训练代码train.py,复制即可使用(全程大约花费2.3元):
import json
from pathlib import Path
import time
import numpy as np
import pytrio as trio
import swanlab
from tqdm import tqdm
# 基础训练配置:按需替换模型、数据集和 LoRA 权重名称。
BASE_MODEL = "Qwen/Qwen3.5-4B"
DATASET_PATH = Path("./huanhuan.json")
NUM_EPOCHS = 2
BATCH_SIZE = 16
LORA_RANK = 32
LEARNING_RATE = 1e-4
MAX_LENGTH = 1024
SYSTEM_PROMPT = "现在你要扮演皇帝身边的女人--甄嬛"
# SwanLab 配置支持通过环境变量覆盖,方便复用同一份脚本跑多组实验。
SWANLAB_PROJECT = "trio-case"
SWANLAB_EXPERIMENT_NAME = f"chat-huanhuan-{BASE_MODEL.split('/')[-1].lower()}"
WEIGHTS_NAME = SWANLAB_EXPERIMENT_NAME
# 加载数据集
def load_examples(dataset_path: Path) -> list[dict[str, str]]:
# 数据集是 JSON 数组,每条样本包含 instruction/input/output 三个字段。
raw_examples = json.loads(dataset_path.read_text(encoding="utf-8"))
examples: list[dict[str, str]] = []
for item in raw_examples:
instruction = item.get("instruction", "").strip()
input_text = item.get("input", "").strip()
output_text = item.get("output", "").strip()
if not instruction or not output_text:
continue
# input 为空时只使用 instruction;否则把 instruction 和 input 合并成用户输入。
user_text = instruction if not input_text else f"{instruction}\n{input_text}"
examples.append({"user": user_text, "assistant": output_text})
if not examples:
raise ValueError(f"No valid training examples found in {dataset_path}")
return examples
def build_datum(example: dict[str, str], tokenizer) -> trio.Datum:
# system prompt 用于固定角色设定,user 内容来自数据集里的 instruction/input。
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": example["user"]},
]
prompt_text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False,
)
# prompt 部分不参与 loss,等价于常见 SFT 代码里 labels 使用 -100。
prompt_tokens = tokenizer.encode(prompt_text, add_special_tokens=False)
prompt_weights = [0] * len(prompt_tokens)
# assistant 回复才是模型需要学习的目标,因此 loss 权重为 1。
completion_tokens = tokenizer.encode(example["assistant"], add_special_tokens=False)
completion_weights = [1] * len(completion_tokens)
# 显式补上 EOS,让模型学习在回答结束处停止。
eos_token_id = tokenizer.eos_token_id
if eos_token_id is not None:
completion_tokens = completion_tokens + [eos_token_id]
completion_weights = completion_weights + [1]
tokens = prompt_tokens + completion_tokens
weights = prompt_weights + completion_weights
if len(tokens) > MAX_LENGTH:
# 超长样本直接截断,保持 tokens 和 weights 对齐。
tokens = tokens[:MAX_LENGTH]
weights = weights[:MAX_LENGTH]
# 自回归训练需要右移一位:input 预测 target,loss_weights 对齐 target。
input_tokens = tokens[:-1]
target_tokens = tokens[1:]
loss_weights = weights[1:]
return trio.Datum(
model_input=trio.ModelInput.from_ints(tokens=input_tokens),
loss_fn_inputs={
"weights": np.asarray(loss_weights, dtype=np.float32),
"target_tokens": np.asarray(target_tokens, dtype=np.int32),
},
)
def evaluate_client(client, tokenizer, prompts: list[str], title: str) -> None:
# 训练前后都用同一组 prompt 测试,便于观察 LoRA 微调带来的变化。
print(f"\n{title}")
stop_tokens = [tokenizer.eos_token] if tokenizer.eos_token else ["<|im_end|>"]
params = trio.SamplingParams(max_tokens=80, temperature=0.0, stop=stop_tokens)
for prompt in prompts:
# 推理时也保留同一个 system prompt,保证训练和测试输入格式一致。
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": prompt},
]
prompt_text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False,
)
prompt_ids = tokenizer.encode(prompt_text, add_special_tokens=False)
future = client.sample(
prompt=trio.ModelInput.from_ints(prompt_ids),
sampling_params=params,
num_samples=1,
)
result = future.result()
print(f"User: {prompt}")
print(f"Assistant: {result.sequences[0].text.strip()}\n")
def main() -> None:
# 使用脚本所在目录拼接数据路径,避免从其他工作目录运行时找不到数据集。
dataset_path = Path(__file__).resolve().parent / DATASET_PATH
examples = load_examples(dataset_path)
print(f"Loaded {len(examples)} training examples from {dataset_path}")
# 创建 PyTrio 服务客户端,并基于指定基座模型创建 LoRA 训练客户端。
service_client = trio.ServiceClient()
training_client = service_client.create_lora_training_client(
base_model=BASE_MODEL,
rank=LORA_RANK,
)
print("Loading tokenizer...")
tokenizer = training_client.get_tokenizer()
print("Tokenizer ready")
# 预先把原始文本样本转换成 PyTrio 训练所需的 Datum。
processed_examples = [build_datum(example, tokenizer) for example in examples]
print("Start training")
# 计算每个 epoch 的训练步数和总步数,便于进度条显示和 SwanLab 日志记录。
steps_per_epoch = (len(processed_examples) + BATCH_SIZE - 1) // BATCH_SIZE
total_steps = NUM_EPOCHS * steps_per_epoch
# 把关键超参数写入 SwanLab,便于后续复现实验。
swanlab_init_kwargs = {
"project": SWANLAB_PROJECT,
"experiment_name": SWANLAB_EXPERIMENT_NAME,
"config": {
"base_model": BASE_MODEL,
"dataset_path": str(DATASET_PATH),
"weights_name": WEIGHTS_NAME,
"num_epochs": NUM_EPOCHS,
"batch_size": BATCH_SIZE,
"lora_rank": LORA_RANK,
"learning_rate": LEARNING_RATE,
"max_length": MAX_LENGTH,
"system_prompt": SYSTEM_PROMPT,
"num_examples": len(processed_examples),
"steps_per_epoch": steps_per_epoch,
"total_steps": total_steps,
},
}
swanlab_run = swanlab.init(**swanlab_init_kwargs)
progress_bar = tqdm(total=total_steps, desc="SFT Training", unit="batch")
for epoch in range(NUM_EPOCHS):
for start in range(0, len(processed_examples), BATCH_SIZE):
batch = processed_examples[start:start + BATCH_SIZE]
batch_index = start // BATCH_SIZE
global_step = epoch * steps_per_epoch + batch_index
# 提交训练任务,进行前向和反向传播,并更新优化器参数。
fwdbwd_future = training_client.forward_backward(batch, "cross_entropy")
optim_future = training_client.optim_step(trio.AdamParams(learning_rate=LEARNING_RATE))
fwdbwd_result = fwdbwd_future.result()
optim_result = optim_future.result()
# PyTrio 返回每个 token 的 logprob,这里按 loss 权重求加权平均 loss。
logprobs = np.concatenate(
[output["logprobs"].tolist() for output in fwdbwd_result.loss_fn_outputs]
)
weights = np.concatenate(
[example.loss_fn_inputs["weights"].tolist() for example in batch]
)
loss = -np.dot(logprobs, weights) / weights.sum()
swanlab.log(
{
"loss": float(loss),
"epoch": epoch + 1,
"batch": batch_index + 1,
},
step=global_step,
)
progress_bar.update(1)
progress_bar.set_postfix(epoch=f"{epoch + 1}/{NUM_EPOCHS}", loss=f"{loss:.4f}")
progress_bar.close()
print("Saving LoRA weights...")
# 保存 LoRA 权重,并拿到带 LoRA 权重的采样客户端用于效果测试。
sft_weights = training_client.save_weights_for_sampler(name=WEIGHTS_NAME)
# 未训练前的基座模型采样客户端,用于对比训练前后的效果。
base_sampling_client = service_client.create_sampling_client(base_model=BASE_MODEL)
# 训练后带 LoRA 权重的采样客户端,用于对比训练前后的效果。
tuned_sampling_client = service_client.create_sampling_client(
base_model=BASE_MODEL,
model_path=sft_weights.result().path,
)
# 测试 prompt 列表,便于观察 LoRA 微调带来的变化。
test_prompts = [
"你是谁?",
"介绍一下你自己。",
"朕今天偶感风寒,你觉得我该如何调养身体?",
]
# 训练前后都用同一组 prompt 测试,便于观察 LoRA 微调带来的变化。
evaluate_client(base_sampling_client, tokenizer, test_prompts, title="Base model responses")
evaluate_client(tuned_sampling_client, tokenizer, test_prompts, title="Fine-tuned model responses")
print(f"Saved weights name: {WEIGHTS_NAME},Weights path: {sft_weights.result().path}")
swanlab_run.finish()
if __name__ == "__main__":
start_main_time = time.time()
main()
end_main_time = time.time()
print("#" * 50)
print("# all done")
print(f"# train cost {end_main_time - start_main_time:.2f}s")
print("#" * 50)看到下面的进度条即代表训练开始:

在这次训练中,我们的超参数如下:
base_model:Qwen/Qwen3.5-4B
epoch:2
batch_size:16
lora_rank:32
learning_rate:1e-4
max_length:1024
system_prompt:现在你要扮演皇帝身边的女人--甄嬛
训练结果演示
在SwanLab上查看最终的训练结果:
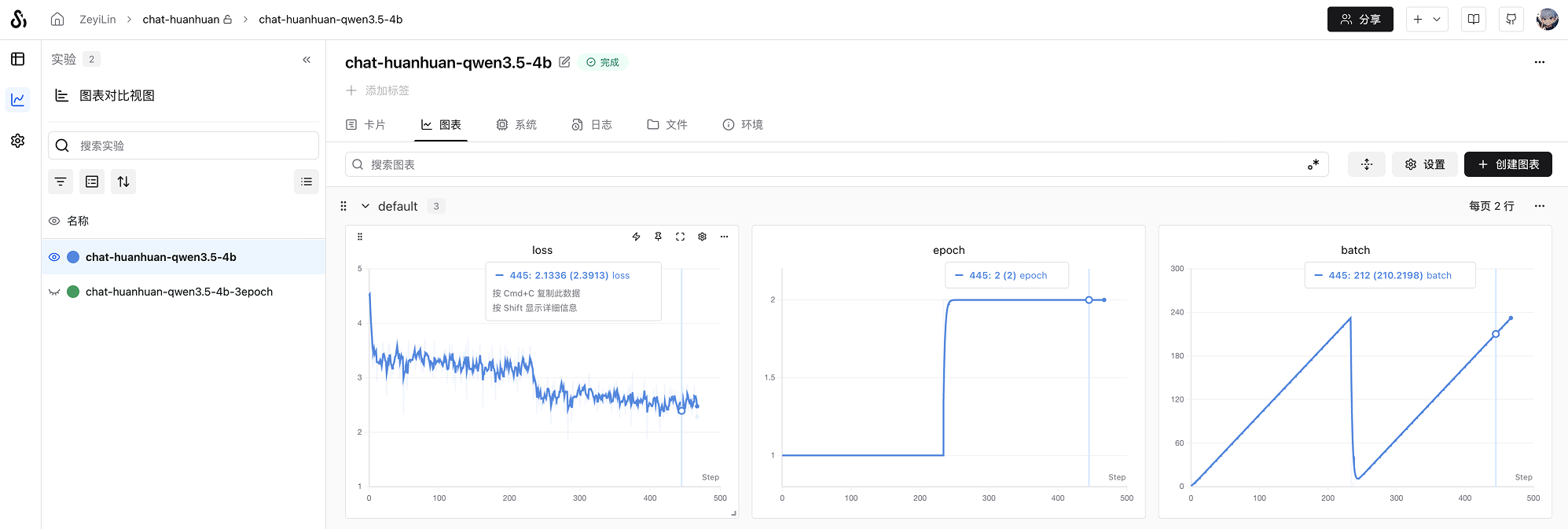
可以看到在3个epoch之后,微调后的 Qwen3.5-4B 的loss降低到了不错的水平——当然对于大模型来说,真正的效果评估还得看主观效果。
可以看到在一些测试样例上,微调后的Qwen3.5-4B能够给出符合角色的回答:
Fine-tuned model responses
User: 你是谁?
Assistant: 我是甄嬛,家父是大理寺少卿甄远道。
User: 介绍一下你自己。
Assistant: 我是甄嬛,家父是大理寺少卿甄远道。
User: 朕今天偶感风寒,你觉得我该如何调养身体?
Assistant: 风寒不宜用重药,皇上若觉得不适,可让太医送些参汤来。至此,你已经完成了 Qwen3.5 监督微调的训练!
推理训练好的模型
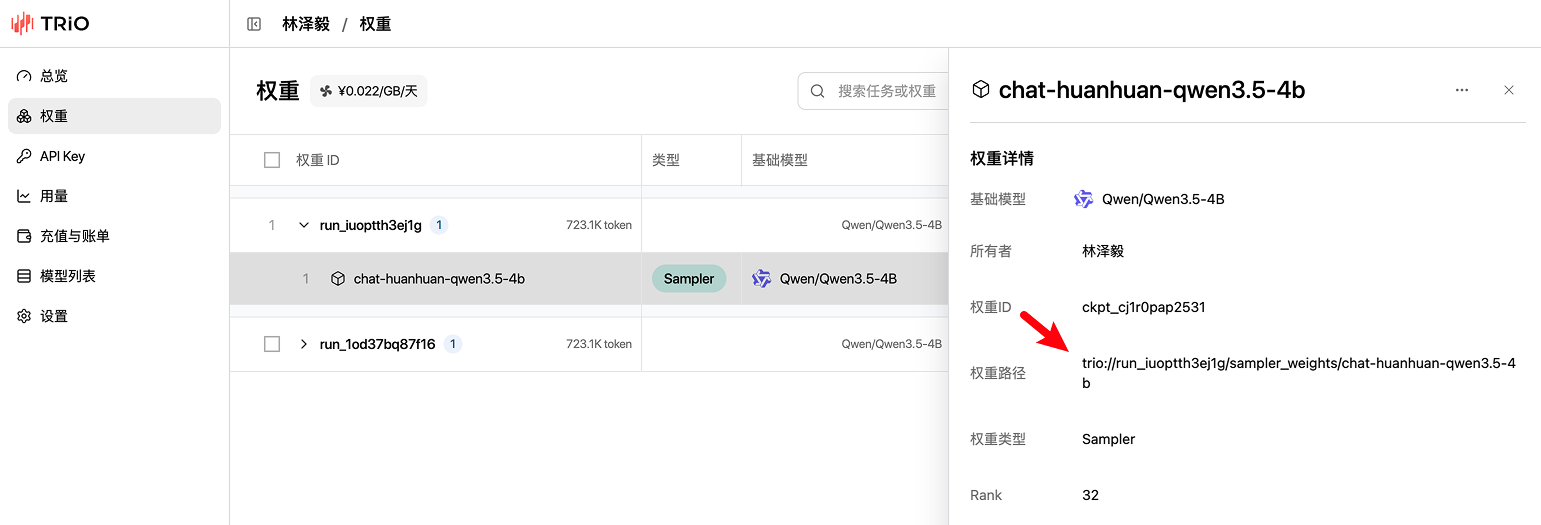
训好的 LoRA模型 可以在 TRIO控制台-权重 中找到:

你可以把权重下载到本地,也可以直接在线调用。
在线调用的代码如下:
import pytrio as trio
# 1. 与 TRIO 建立连接
service_client = trio.ServiceClient()
# 2. 创建 1 个推理客户端
sampling_client = service_client.create_sampling_client(
base_model="Qwen/Qwen3.5-4B",
model_path="你的模型路径"
)
# 3. 获取 Tokenizer 并对输入文本进行预处理
print("Loading tokenizer...")
tokenizer = sampling_client.get_tokenizer()
messages=[{"role": "user", "content": ""}]
input_text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
input_ids = tokenizer.encode(input_text)
print("tokenizer finish")
# 4. 推理
params = trio.SamplingParams(max_tokens=4096, seed=42, temperature=0.7)
response = sampling_client.sample(
prompt=trio.ModelInput.from_ints(input_ids),
num_samples=2,
sampling_params=params,
)
response = response.result()
for i, seq in enumerate(response.sequences):
print(f"Sample {i+1}: {repr(seq.text)}")在model_path那一行,填写实际的权重路径,可以在网页上找到:
执行推理代码,可以看到:
进阶-通过 OpenAI API 使用微调后模型
将下面的MODEL_PATH变量值改为实际的权重路径,即可进行openai风格的调用,实现和你的其他应用的集成:
from openai import OpenAI
BASE_URL = "https://pytrio.cn/api/openai/v1"
MODEL_PATH = "你的模型路径" # 权重路径或基模名称
api_key = "<YOUR_TRIO_API_KEY>" # 你的 TRIO API Key
client = OpenAI(
base_url=BASE_URL,
api_key=api_key,
)
response = client.chat.completions.create(
model=MODEL_PATH,
messages=[{"role": "user", "content": "what's your name?"}],
max_tokens=512,
temperature=0.7,
top_p=0.9,
)
print(f"{response.choices[0].message.content}")进阶-下载微调后的模型
将下面的checkpoint_id换成实际的权重ID,执行后即可下载:
import os
import requests
import pytrio as trio
service_client = trio.ServiceClient()
rest_client = service_client.create_rest_client()
checkpoint_id = "你的权重ID"
response = rest_client.get_checkpoint_archive_url(checkpoint_id)
download_url = response.result().url
save_filename = f"{checkpoint_id}.zip"
with requests.get(download_url, stream=True) as result:
result.raise_for_status()
with open(save_filename, "wb") as file:
for chunk in result.iter_content(chunk_size=8192):
file.write(chunk)
print(f"File download complete: {os.path.abspath(save_filename)}")
进阶- 使用 Qwen3.6-27B 训练
切换到27B模型训练的方式十分简单,只需要在第6节代码中,将BASE_MODEL改为Qwen/Qwen3.6-27B即可。
下面是用Qwen3.6-27B训练的结果:
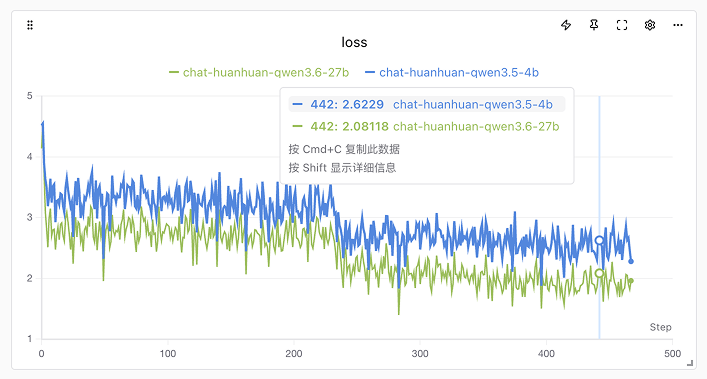
可以看到 27B 模型的训练 Loss 要明显低于 4B,在回答问题的风格上,也有差异:
问题:
朕今天偶感风寒,你觉得我该如何调养身体?
Qwen3.5-4B:
皇上身子不适,臣妾想先告辞了
Qwen3.6-27B:
皇上龙体安康乃社稷之福,皇上若偶感风寒,臣妾以为,皇上应该少食荤腥,以免积食化火,且要多饮热汤水,以助发汗。相关链接
代码:完整代码直接看本文第5节
实验日志过程:chat-huanhuan - swanlab
模型:Qwen3.5-4B
数据集:Chat-嬛嬛
TRIO:https://pytrio.cn