什么是实验记录
实验记录 是指在机器学习模型开发过程中,记录每个实验从开始到结束的超参数、指标、硬件、环境、日志等数据,并在UI界面进行组织和呈现的过程。实验记录的目的是帮助研究人员更有效地管理和分析实验结果,以便更好地理解模型性能的变化,进而优化模型开发过程。
🤔简单来说
实验记录的作用可以理解为,在进行机器学习实验时,记录下实验的各个关键信息,为后续模型的进化提供“弹药”。
与实验记录息息相关的,是可视化、可复现性、实验比较以及团队协作。
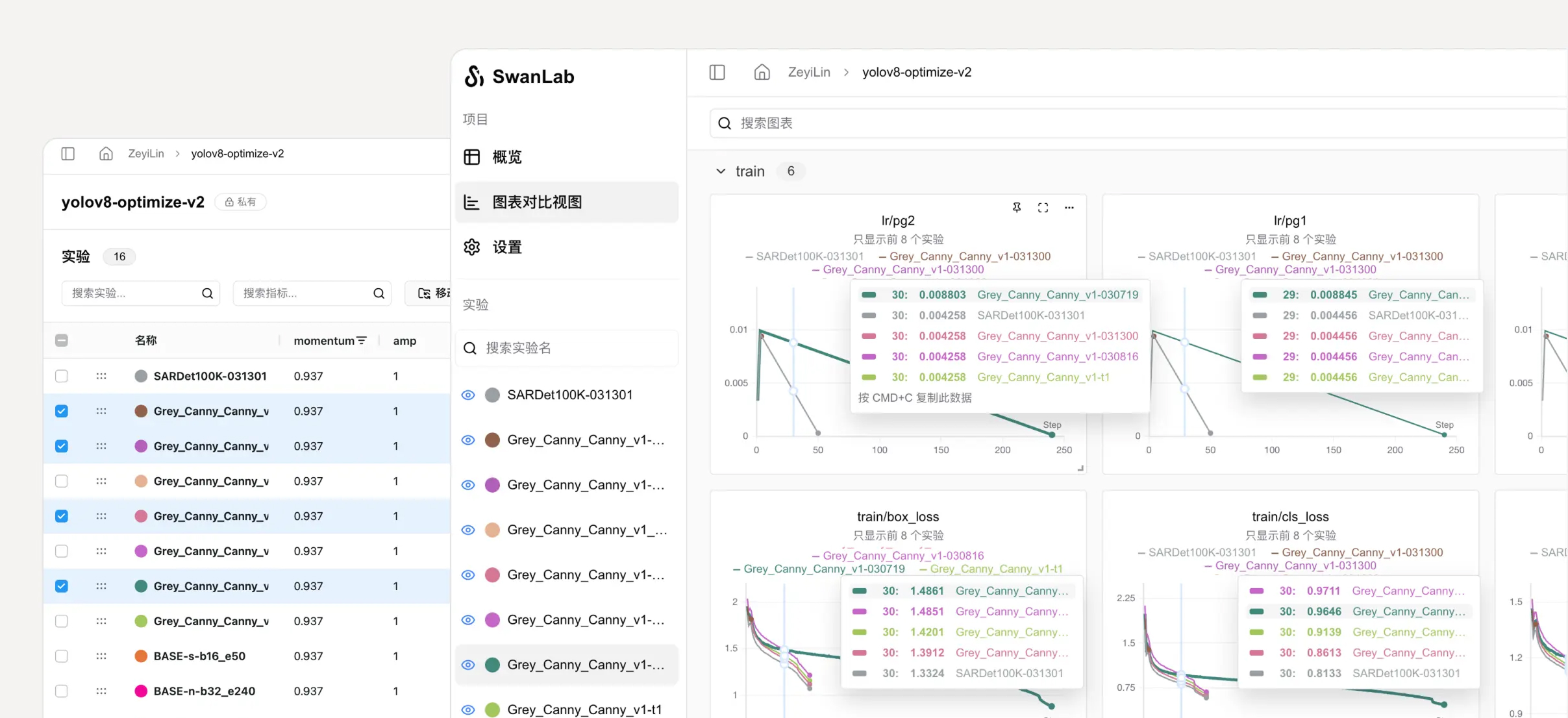
- 📊 可视化: 通过UI界面对实验记录数据进行可视化,可以让训练师直观地看到实验每一步的结果,分析指标走势,判断哪些变化导致了模型效果的提升,从而整体性地提升模型迭代效率。
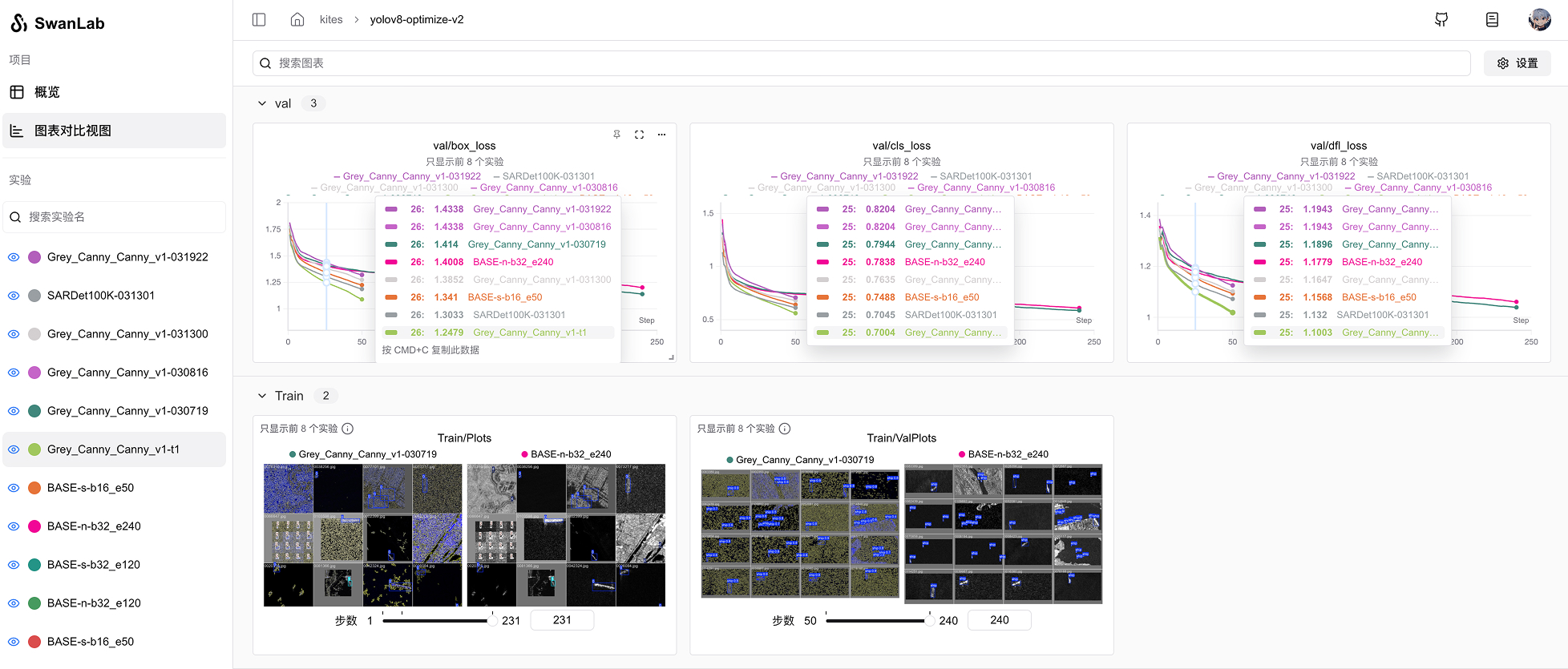
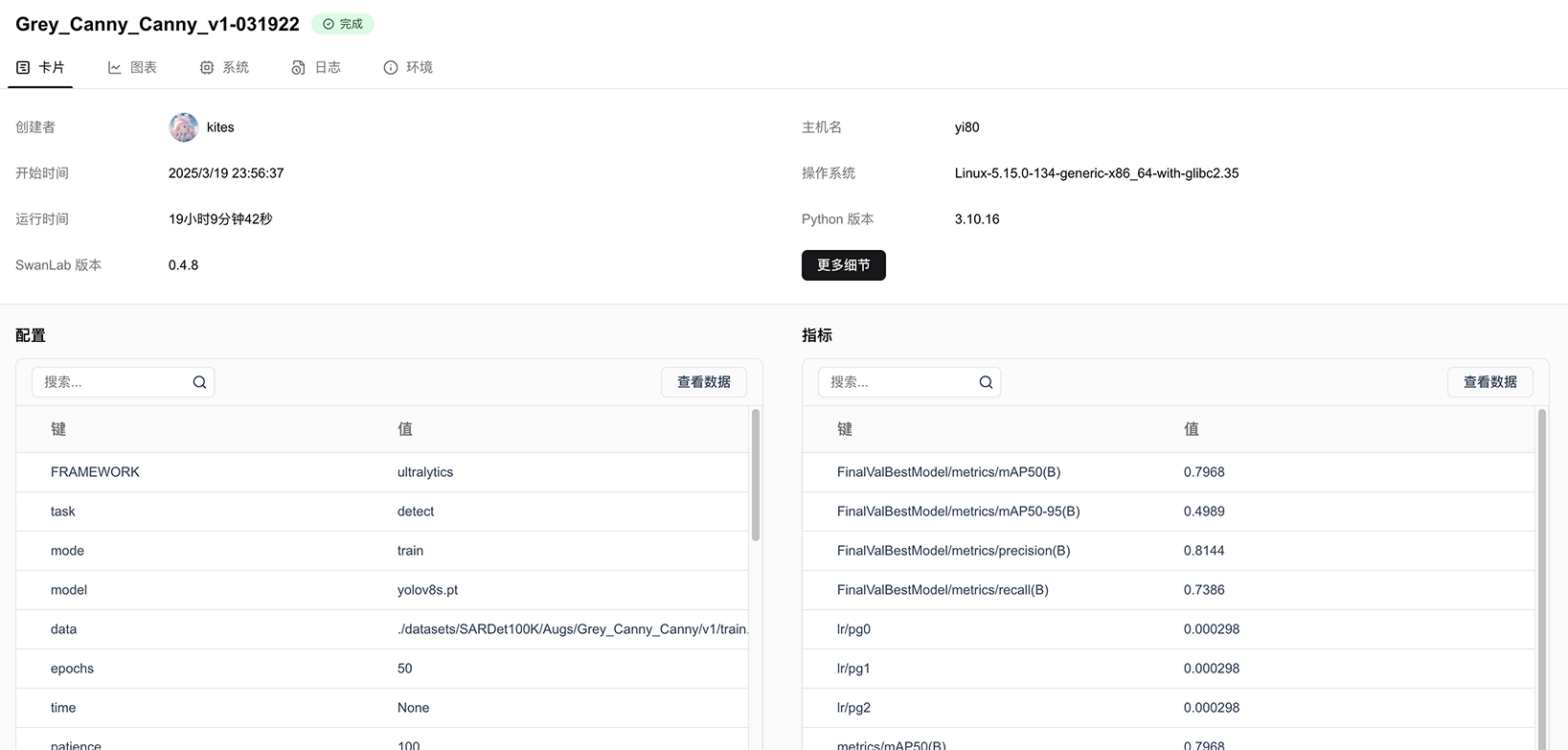
- ♻️ 可复现性: 实验从跑通到可用,再到SOTA,往往需要经历大量试验,而一些非常好的结果可能出现在中前期。但如果没有实验记录和可视化,训练师难以记住这些结果,从而导致大量优秀的实验结果记不清细节或被遗忘。而通过SwanLab的实验记录和可视化功能,可以帮助训练师随时回顾这些结果,大大提高了可复现性与整体效率。
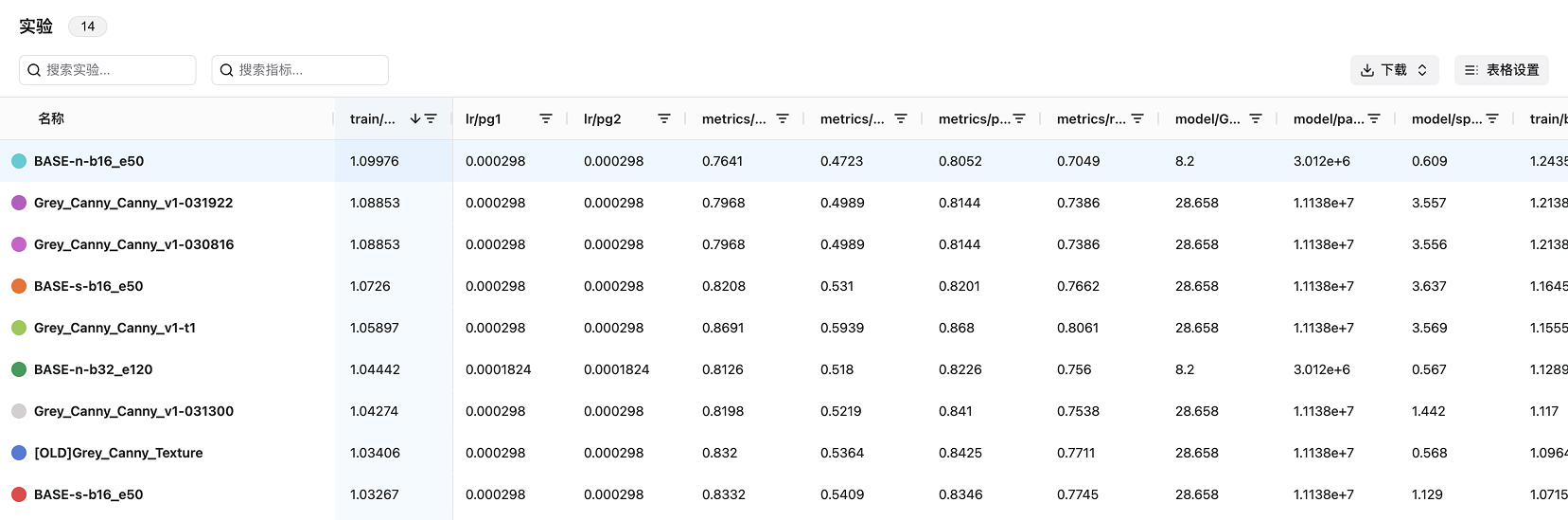
- 🆚 实验比较: 训练师可以通过SwanLab轻松地比较多组实验结果,分析哪些变化导致了性能提升,从而快速找到最优的训练策略。
- 👥 团队协作: 通过SwanLab的实验分享、团队空间、多人协同等功能,无缝地共享训练进展和心得经验,打通团队成员之间的信息孤岛,提高团队协作效率。
SwanLab是如何进行实验记录的?
SwanLab帮助你只需使用几行代码,便可以记录机器学习实验,并在交互式仪表板中查看与比较结果。记录流程:
- 创建SwanLab实验。
- 将超参数字典(例如学习率或模型类型)存储到您的配置中 (swanlab.config)。
- 在训练循环中随时间记录指标 (swanlab.log),例如准确性acc和损失loss。
下面的伪代码演示了常见的SwanLab实验记录工作流:
python
# 1. 创建1个SwanLab实验
swanlab.init(project="my-project-name")
# 2. 存储模型的输入或超参数
swanlab.config.learning_rate = 0.01
# 这里写模型的训练代码
...
# 3. 记录随时间变化的指标以可视化表现
swanlab.log({"loss": loss})如何开始?
探索以下资源以了解SwanLab实验记录: